How We Built a Robust Enterprise Agentic RAG Platform within elDoc for True Document Intelligence at Scale

Enterprises don’t lack data – they lack intelligence over their data. In fact, the problem is far deeper than most organizations realize. A vast majority of enterprise knowledge doesn’t live in clean databases or neatly structured systems. It exists in scanned PDFs, images, photos, handwritten forms, contracts, invoices, and legacy archives – data that was never designed to be machine-readable.
This is what we call enterprise dark data.
It’s everywhere:
- Decades of scanned contracts sitting in document repositories
- Compliance documents stored as PDFs with no structure
- Photos of forms, reports, and field data
- Emails and attachments buried in disconnected systems
- Legacy systems exporting static, non-queryable files
⚠️ The Hidden Problem
Most AI initiatives quietly ignore this layer of data. Why?
Because it’s hard.
Traditional pipelines rely on:
- Clean text
- Structured databases
- Preprocessed content
But in reality:
Up to 70–80% of enterprise data is unstructured and a large portion of that is image-based or scanned.
This means:
- Critical knowledge is invisible to search systems
- LLMs operate on partial context
- Decision-making is based on incomplete information
👉 The result?
AI that sounds intelligent but isn’t grounded in the full truth of enterprise data.
🧠 Why LLMs Alone Are Not Enough
Large Language Models are powerful but they have a fundamental limitation:
They only know what you give them.
If your retrieval layer ignores:
- Scanned documents
- Images
- Non-indexed PDFs
Then your AI system is effectively blind to a massive portion of enterprise knowledge.
💡 Our Perspective at elDoc
At elDoc, we didn’t treat this as an edge case – we treated it as the core problem.
We asked:
How do we bring ALL enterprise data especially the messy, unstructured, image-based majority into an intelligent, queryable system?
And more importantly:
How do we do it in a way that allows AI not just to retrieve information, but to understand, reason, and act on it securely and at scale?
Inside elDoc: How Our Agentic RAG Architecture Works at Scale
Designing an Agentic RAG system is one thing. Making it reliable, accurate, and scalable across millions of enterprise documents is another.
At elDoc, we approached this problem from first principles:
If AI is only as good as what it retrieves, then retrieval must be engineered as a first-class system not an afterthought.
The Core Breakthrough: Hybrid Retrieval Architecture
One of the earliest challenges we encountered was retrieval quality.
Enterprise data is:
- Inconsistent
- Multimodal
- Poorly structured
- Spread across systems
And we quickly realized a fundamental limitation:
No single retrieval method works across all enterprise data.
- Vector search struggles with exact matches (e.g., contract clauses)
- Keyword search misses semantic meaning
- Metadata alone lacks depth
So instead of choosing one approach—we combined them.
A Multi-Layered Retrieval System
We engineered a hybrid retrieval architecture that operates as the backbone of elDoc. Each layer solves a different part of the problem:
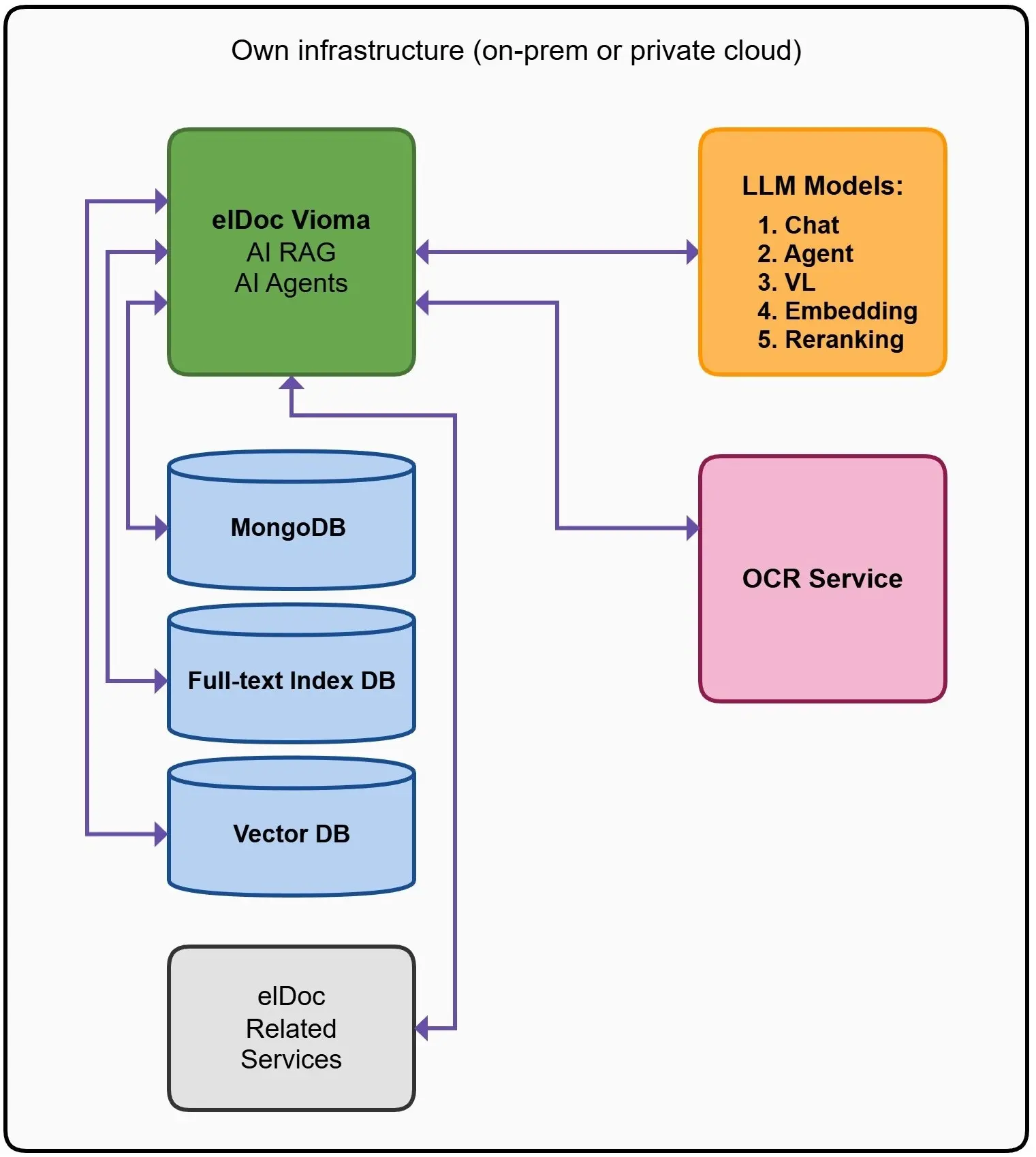
🗄️ Context Layer — MongoDB
This layer provides state and structure.
It stores:
- Document metadata
- Relationships between entities
- User and session context
- Workflow and agent state
💡 Why it matters
Retrieval is no longer stateless.
Agents can:
- Understand who is asking
- Track what has already been retrieved
- Maintain context across multi-step reasoning
👉 This is what enables true agentic behavior, not just search.
📄 Precision Layer — Full-Text Search
This layer ensures accuracy where it matters most.
It handles:
- Exact keyword matching
- Legal clauses
- Compliance documents
- Structured queries
💡 Why it matters
In enterprise scenarios:
- “Almost correct” is not acceptable
- Exact phrasing can change meaning entirely
👉 This layer guarantees precision and reliability.
🧠 Semantic Layer — Vector Database
This layer brings understanding.
It enables:
- Similarity-based retrieval
- Context-aware search
- Discovery beyond exact keywords
💡 Why it matters
Users don’t always know how to phrase queries.
This layer ensures the system can:
- Interpret intent
- Find relevant information—even when wording differs
👉 This is where RAG becomes intelligent.
From RAG to Agentic RAG: The Turning Point in elDoc
When we started building our platform at elDoc, we didn’t begin with Agentic RAG. We began where most systems do with traditional RAG. It worked… to a point.
⚠️ Where Traditional RAG Falls Short
In early implementations, we observed consistent limitations:
- One-shot retrieval often missed critical context
- Queries returned partially relevant results
- No ability to adapt when results were weak
- No understanding of which retrieval method to use
- Poor handling of complex, multi-step enterprise queries
Most importantly:
The system had no awareness of its own limitations.
It retrieved once and hoped for the best.
💡 The Realization
We quickly understood that the problem wasn’t generation. It was how retrieval was being orchestrated.
And that led us to a fundamental shift:
RAG should not be a pipeline – it should be a decision-making system.
The Shift: Introducing Agentic RAG
We transformed our architecture from:
Retrieve → Generate
into:
Understand → Plan → Retrieve → Evaluate → Refine → Generate
This is what we call Agentic RAG.
🔑 What Changed?
Instead of treating retrieval as a fixed step, we introduced AI agents that:
- Decide how to retrieve
- Choose which systems to query
- Evaluate the quality of retrieved results
- Refine and retry when needed
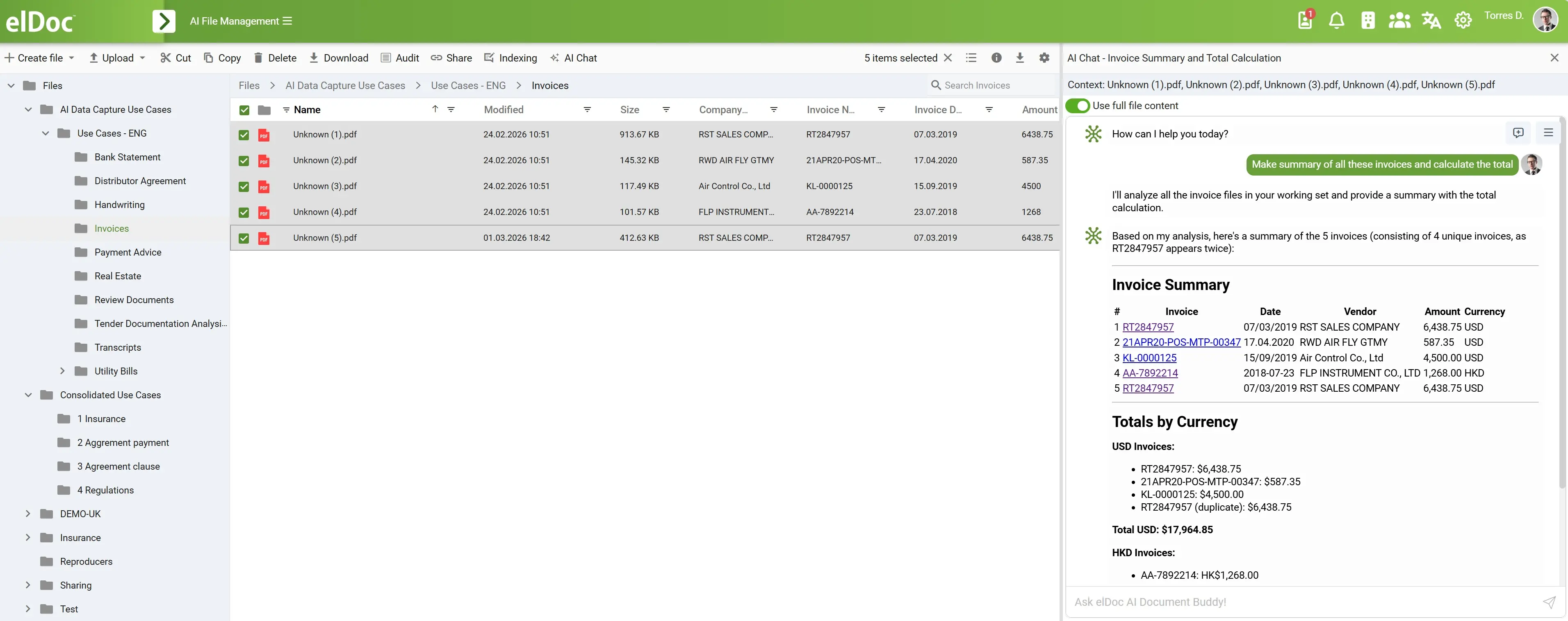
Agentic RAG in Action: Data Analysis & Intelligence in elDoc
The screenshot captures a very practical enterprise scenario:
A user selects multiple invoice documents and asks:
“Make summary of all these invoices and calculate the total.”
At first glance, this looks simple.
In reality, it’s a multi-step reasoning problem across unstructured documents.
This is exactly where Agentic RAG shows its power.
What Makes This an Agentic Problem (Not Just RAG)
A traditional RAG system would:
- Retrieve chunks from documents
- Feed them into an LLM
- Generate a summary
But that approach would struggle with:
- Duplicate invoices
- Multi-document aggregation
- Currency grouping
- Structured output generation
👉 It would likely produce an incomplete or incorrect answer.
How Agentic RAG in elDoc Solves It Step-by-Step
1. 🧠 Understanding the Intent
The agent doesn’t just read the prompt – it interprets it:
- This is not a simple summary
- It requires aggregation + calculation
- It involves multiple documents as a working set
- Output must be structured and accurate
2. 📂 Context Expansion (Full Document Mode)
From the UI:
“Use full file content” is enabled
This triggers the system to:
- Treat all selected invoices as a bounded dataset
- Retrieve full document content (not just chunks)
- Prepare for cross-document reasoning
3. 🔍 Retrieval Across Documents
The Agentic RAG system:
- Extracts data from all selected PDFs
- Uses OCR (if needed) to read invoice content
- Identifies key fields:
- Invoice number
- Vendor
- Date
- Amount
- Currency
👉 This is not just retrieval – it’s structured extraction.
4. 🧩 Data Normalization & Alignment
Now the agent:
- Aligns extracted data into a consistent format
- Detects duplicates
- Example:
RT2847957appears twice
- Example:
- Differentiates invoices by:
- ID
- Vendor
- Date
👉 This step is critical and impossible with naive RAG.
5. 🎯 Reasoning & Deduplication
The system identifies:
- 5 files selected
- But only 4 unique invoices
This requires:
- Logical comparison
- Cross-document reasoning
- Deduplication strategy
💡 This is the key Agentic moment:
The system questions the data, not just reports it.
6. 🧮 Aggregation & Calculation
The agent then performs:
Currency-aware grouping:
- USD invoices
- HKD invoices
Calculations:
- Summing totals per currency
- Handling duplicates correctly
7. 📊 Structured Output Generation
Instead of plain text, the system produces:
✔ Invoice Summary Table
- Invoice ID
- Date
- Vendor
- Amount
- Currency
✔ Totals by Currency
- Grouped
- Calculated
- Clearly separated
Where Agentic RAG Truly Shines
This workflow is not linear. The agent internally:
- Extracts → evaluates → validates → recalculates
- Adjusts logic based on intermediate findings
Traditional RAG vs Agentic RAG
| Capability | Traditional RAG | Agentic RAG (elDoc) |
|---|---|---|
| Multi-document understanding | Limited | Strong |
| Deduplication | ❌ | ✅ |
| Calculations | ❌ | ✅ |
| Structured output | Weak | Strong |
| Context awareness | Static | Dynamic |
| Accuracy | Unreliable | High |
What Differentiates Enterprise Agentic RAG: Security, Access, and Trust by Design
Agentic RAG brings intelligence into retrieval enabling systems to plan, reason, and iterate. But in enterprise environments, intelligence alone is not enough. The real requirement is trust. At elDoc, we evolved Agentic RAG into Enterprise Agentic RAG by embedding security, access control, and governance directly into the architecture not as an afterthought, but as a core capability.
Unlike standard Agentic RAG systems that optimize for reasoning and retrieval, Enterprise Agentic RAG operates within strict boundaries. Every query, every retrieval step, and every generated response is context-aware and permission-aware.
This means:
- Users only access what they are authorized to see
- Agents retrieve data based on role-based and attribute-based access controls (RBAC/ABAC)
- Sensitive documents remain protected even during multi-step reasoning
👉 The system doesn’t just ask “what is relevant?”
It also asks “what is allowed?”
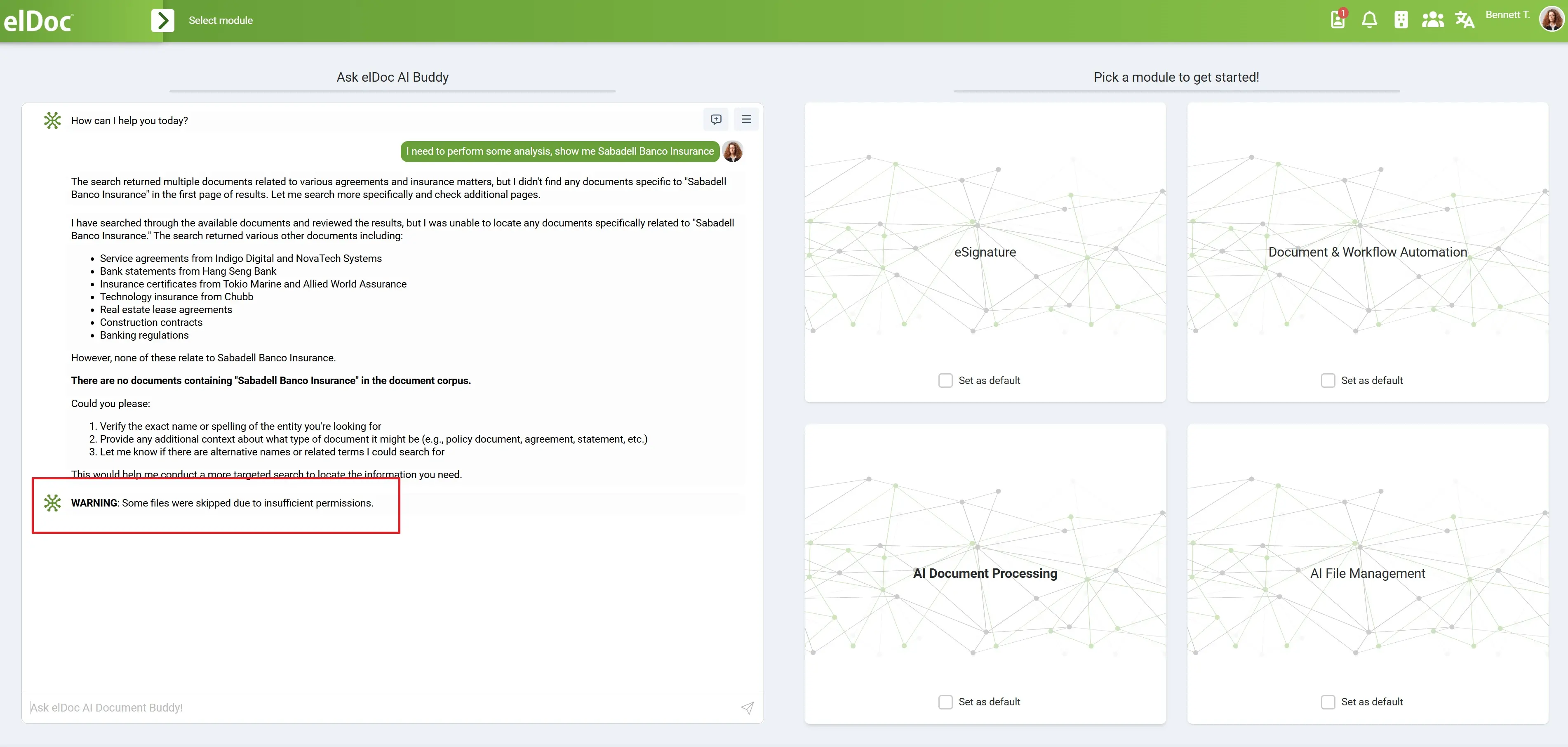
Security is enforced at multiple levels:
- Document-level permissions ensure fine-grained control over access
- Context filtering guarantees that retrieved data respects user roles
- Policy-aware agents dynamically adjust retrieval strategies to avoid restricted content
- Private deployment (on-prem or private cloud) ensures full data sovereignty
In addition, every action is auditable and traceable:
- What data was retrieved
- What context was used
- How the final response was generated
This is critical for compliance-heavy industries where transparency is non-negotiable.
From Documents to Decisions with elDoc Agentic RAG
What we built with elDoc Vioma is more than a RAG system – it’s a shift toward Agentic RAG, where AI doesn’t just retrieve information but actively understands, reasons, and works with enterprise data.
By combining hybrid retrieval, agent-based orchestration, and multimodal processing, we enabled a system that can handle real-world complexity – scanned documents, fragmented data, and large-scale knowledge—while delivering accurate, structured, and actionable outputs.
This is what transforms:
- Data → into context
- Context → into insight
- Insight → into decisions
If you’re looking to move beyond basic RAG and unlock true document intelligence at scale, it’s time to explore what Agentic RAG can do in your environment.
👉 Discover how elDoc can bring intelligence to your enterprise data.