Як ми створили потужну Enterprise Agentic RAG платформу в elDoc для інтелектуальної роботи з документами у великих масштабах

Підприємствам не бракує даних – їм бракує можливості отримувати аналітичні висновки на основі цих даних. Насправді проблема набагато глибша, ніж уявляє собі більшість організацій. Переважна частина корпоративних знань зберігається не в упорядкованих базах даних чи добре структурованих системах. Вона міститься у відсканованих PDF-файлах, зображеннях, фотографіях, рукописних формах, контрактах, рахунках-фактурах та архівних документах – тобто даних, які ніколи не призначалися для машинного зчитування.
Саме це називають корпоративними «темними даними» (Enterprise Dark Data).
Вони всюди:
- Відскановані контракти, що накопичувалися в сховищах документів десятиліттями
- Документи з дотримання нормативних вимог, збережені як неструктуровані PDF-файли
- Фотографії форм, звітів і польових даних
- Електронні листи та вкладення, приховані в розрізнених системах
- Застарілі системи, що експортують статичні файли без можливості пошуку та аналізу
⚠️ Прихована проблема
Більшість ініціатив зі впровадження ШІ фактично ігнорують цей рівень даних. Чому?
Тому що працювати з ним складно.
Традиційні конвеєри обробки даних спираються на:
- Чистий текст
- Структуровані бази даних
- Попередньо оброблений контент
Але в реальності:
До 70–80% корпоративних даних є неструктурованими, і значна їх частина існує у форматі зображень або сканів.
Це означає, що:
- Критично важлива інформація залишається невидимою для пошукових систем
- Великі мовні моделі (LLM) працюють лише з частиною контексту
- Ухвалення рішень ґрунтується на неповній інформації
👉 Який результат?
Штучний інтелект, що звучить переконливо та розумно, але не спирається на повну картину корпоративних даних.
🧠 Чому самих лише LLM недостатньо
Великі мовні моделі мають потужні можливості, але їм притаманне одне фундаментальне обмеження:
Вони знають лише те, що їм надають.
Якщо ваш рівень пошуку та отримання даних ігнорує:
- Відскановані документи
- Зображення
- Неіндексовані PDF-файли
Тоді ваша система ШІ фактично не бачить величезної частини корпоративних знань.
💡 Наш підхід в elDoc
У elDoc ми не розглядали це як окремий окремий випадок – для нас це була ключова проблема.
Ми поставили собі запитання:
Як залучити ВСІ корпоративні дані, особливо їхню неструктуровану, складну для обробки та представлену у вигляді зображень більшість, в єдину інтелектуальну систему з можливістю пошуку та аналізу?
І що ще важливіше:
Як зробити це так, щоб ШІ міг не лише знаходити інформацію, а й розуміти її, аналізувати та діяти на її основі безпечно й у масштабах усього підприємства?
Ізсередини elDoc: як наша архітектура Agentic RAG працює в корпоративному масштабі
Спроєктувати систему Agentic RAG – це одне. Забезпечити її надійність, точність і масштабованість для роботи з мільйонами корпоративних документів – зовсім інше.
У elDoc ми підійшли до цієї проблеми, спираючись на базові принципи:
Якщо якість роботи ШІ залежить від якості отриманої інформації, то система пошуку та отримання даних має бути ключовим елементом архітектури, а не другорядним доповненням.
Ключовий прорив: гібридна архітектура пошуку та отримання даних
Одним із перших викликів, з якими ми зіткнулися, стала якість пошуку та отримання даних.
Корпоративні дані є:
- Неоднорідними
- Мультимодальними
- Погано структурованими
- Розподіленими між різними системами
І ми швидко усвідомили одне фундаментальне обмеження:
Жоден окремий метод пошуку не працює однаково ефективно для всіх типів корпоративних даних.
- Векторний пошук погано справляється з точними збігами (наприклад, із пошуком конкретних пунктів договору)
- Пошук за ключовими словами не враховує семантичний зміст
- Самих лише метаданих недостатньо для глибокого аналізу
Тому замість вибору одного підходу ми об’єднали їх в єдину систему.
Багаторівнева система пошуку та отримання даних
Ми розробили гібридну архітектуру пошуку та отримання даних, яка є основою платформи elDoc. Кожен рівень вирішує окрему частину завдання:
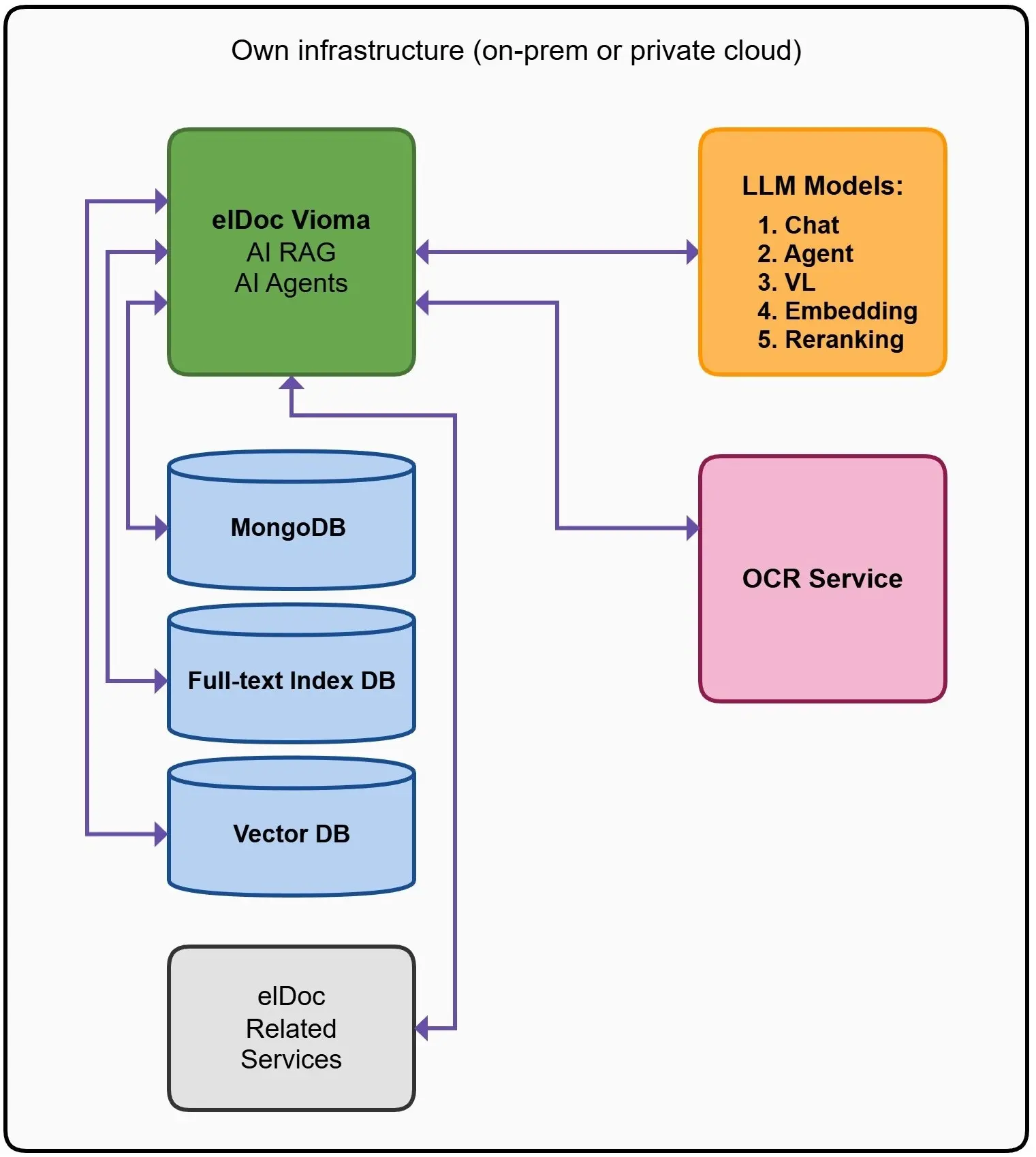
🗄️ Контекстний рівень – MongoDB
Цей рівень забезпечує збереження контексту та структури даних.
Він зберігає:
- Метадані документів
- Зв’язки між сутностями
- Контекст користувачів і сесій
- Стан робочих процесів і ШІ-агентів
💡 Чому це важливо
Пошук і отримання даних більше не є процесом без збереження контексту.
ШІ-агенти можуть:
- Розуміти, хто саме звертається із запитом
- Відстежувати, яку інформацію вже було отримано
- Зберігати контекст під час багатоетапного аналізу та міркувань
👉 Саме це забезпечує справжню агентну поведінку, а не просто пошук інформації.
📄 Рівень точності – повнотекстовий пошук
Цей рівень забезпечує точність там, де вона є критично важливою.
Він відповідає за:
- Точний пошук за ключовими словами
- Положення та пункти договорів
- Документи щодо дотримання нормативних вимог
- Структуровані запити
💡 Чому це важливо
У корпоративному середовищі:
- «Майже правильно» – недостатньо
- Точне формулювання може кардинально змінити зміст
👉 Цей рівень гарантує точність і надійність результатів.
🧠 Семантичний рівень – векторна база даних
Цей рівень забезпечує розуміння змісту даних.
Він надає можливість:
- Виконувати пошук на основі семантичної схожості
- Використовувати контекстно-орієнтований пошук
- Знаходити інформацію навіть за відсутності точних ключових слів
💡 Чому це важливо
Користувачі не завжди знають, як правильно сформулювати запит.
Цей рівень забезпечує здатність системи:
- Розпізнавати намір користувача
- Знаходити релевантну інформацію, навіть якщо формулювання відрізняються
👉 Саме тут RAG перетворюється на по-справжньому інтелектуальну систему.
Від RAG до Agentic RAG: поворотний момент в elDoc
Коли ми починали розробляти платформу elDoc, ми не стартували з Agentic RAG. Ми пішли тим самим шляхом, що й більшість рішень, – із традиційного RAG. І він працював… але лише до певної межі.
⚠️ Обмеження традиційного RAG
У перших реалізаціях ми постійно стикалися з такими обмеженнями:
- Одноразовий пошук часто пропускав критично важливий контекст
- Запити повертали лише частково релевантні результати
- Не було можливості адаптуватися, якщо результати виявлялися недостатньо якісними
- Система не розуміла, який метод пошуку слід застосувати в конкретній ситуації
- Погана обробка складних багатоетапних корпоративних запитів
І найголовніше:
Система не усвідомлювала власних обмежень.
Вона виконувала пошук один раз і фактично сподівалася на найкращий результат.
💡 Ключове усвідомлення
Ми швидко зрозуміли, що проблема полягає не в генерації відповідей, а в тому, як організовано процес пошуку та отримання інформації.
Це привело нас до принципово нового підходу:
RAG не повинен бути просто конвеєром обробки даних – він має бути системою ухвалення рішень.
Зміна підходу: впровадження Agentic RAG
Ми трансформували нашу архітектуру з моделі:
Пошук → Генерація
у модель:
Розуміння → Планування → Пошук → Оцінювання → Уточнення → Генерація
Саме це ми називаємо Agentic RAG.
🔑 Що змінилося?
Замість того щоб розглядати пошук і отримання інформації як фіксований етап, ми впровадили ШІ-агентів, які:
- Визначають, як саме виконувати пошук
- Обирають системи, до яких необхідно звернутися із запитом
- Оцінюють якість отриманих результатів
- Уточнюють підхід і повторюють пошук за потреби
Agentic RAG у дії: аналіз даних та інтелектуальна обробка інформації в elDoc
На знімку екрана показано типовий практичний сценарій використання в корпоративному середовищі:
Користувач обирає кілька рахунків-фактур і ставить запит:
«Підготуй зведення за всіма цими рахунками-фактурами та розрахуй загальну суму».
На перший погляд це виглядає простим завданням.
Насправді ж це завдання потребує багатокрокового аналізу даних із неструктурованих документів.
Саме в таких сценаріях Agentic RAG демонструє свої ключові переваги.
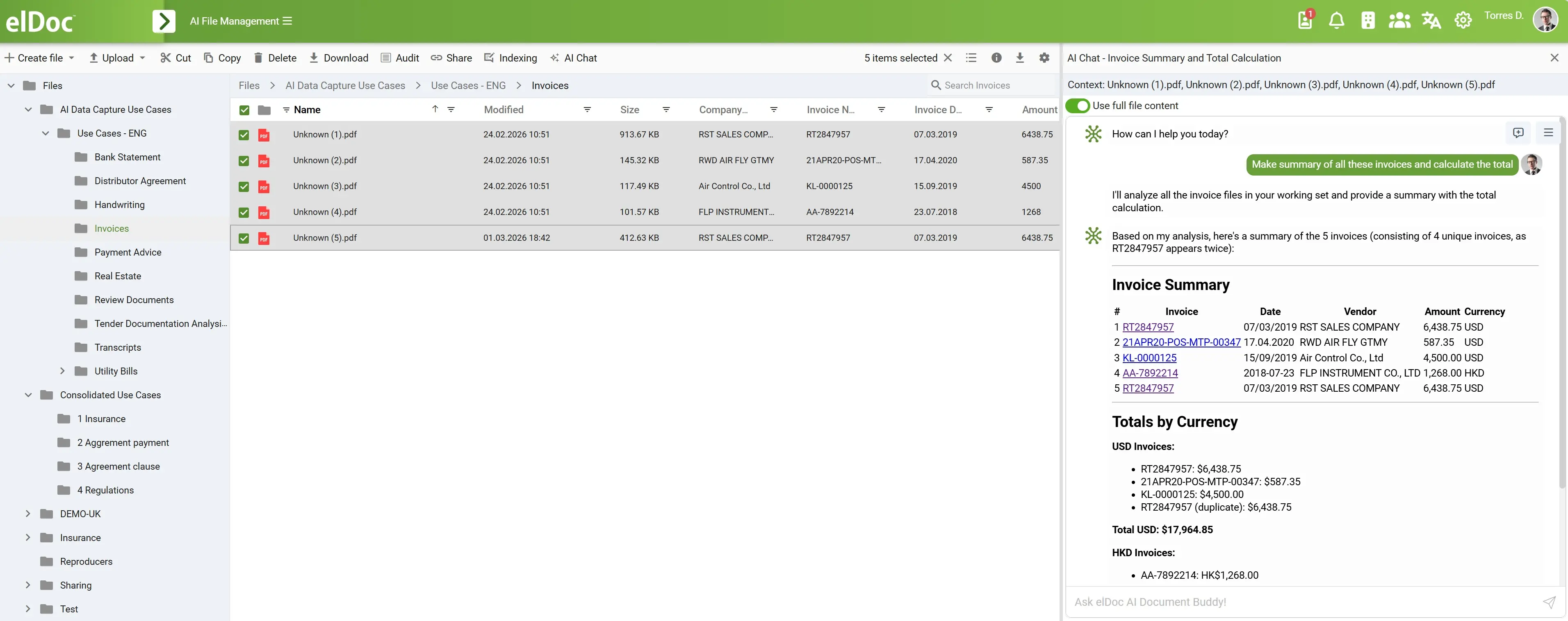
Чому це завдання потребує Agentic RAG, а не лише RAG
Традиційна система RAG виконала б такі дії:
- Отримала б фрагменти інформації з документів
- Передала б їх великій мовній моделі (LLM)
- Згенерувала б підсумкове зведення
Проте такий підхід має суттєві труднощі у випадках, коли потрібно:
- Виявляти дублікати рахунків-фактур
- Об’єднувати та аналізувати дані з багатьох документів
- Групувати суми за валютами
- Формувати структурований результат
👉 У результаті система з великою ймовірністю сформувала б неповну або некоректну відповідь.
Як Agentic RAG в elDoc вирішує це завдання покроково
1. 🧠 Розуміння наміру користувача
Агент не просто читає запит – він інтерпретує його зміст:
- Це не просте створення зведення
- Завдання потребує агрегування даних і виконання розрахунків
- Воно охоплює набір із кількох документів
- Результат має бути структурованим і точним
2. 📂 Розширення контексту (режим повного документа)
В інтерфейсі користувача:
Увімкнено опцію «Використовувати повний вміст файлу»
Це дає системі змогу:
- Розглядати всі вибрані рахунки-фактури як єдиний набір даних
- Отримувати повний вміст документів, а не лише окремі фрагменти
- Підготуватися до аналізу інформації між кількома документами
3. 🔍 Отримання даних з кількох документів
Система Agentic RAG:
- Витягує дані з усіх вибраних PDF-документів
- Використовує OCR (за потреби) для зчитування вмісту рахунків-фактур
- Визначає ключові поля:
- Номер рахунку-фактури
- Постачальник
- Дата
- Сума
- Валюта
👉 Це вже не просто пошук інформації – це структуроване вилучення даних.
4. 🧩 Нормалізація та узгодження даних
На цьому етапі агент:
- Приводить отримані дані до єдиного формату
- Виявляє дублікати
- Наприклад, рахунок
RT2847957зустрічається двічі
- Наприклад, рахунок
- Розрізняє рахунки-фактури за такими ознаками:
- Ідентифікатор
- Постачальник
- Дата
👉 Цей етап є критично важливим і практично неможливим для базового підходу RAG.
5. 🎯 Логічний аналіз і усунення дублікатів
Система визначає:
- Обрано 5 файлів
- Але серед них лише 4 унікальні рахунки-фактури
Для цього необхідні:
- Логічне порівняння даних
- Аналіз інформації між документами
- Стратегія виявлення та усунення дублікатів
💡 Саме тут проявляється ключова перевага Agentic RAG:
Система аналізує та перевіряє дані, а не просто відтворює їх.
6. 🧮 Агрегування та розрахунки
Після цього агент виконує:
Групування даних з урахуванням валют:
- Рахунки-фактури в USD
- Рахунки-фактури в HKD
Розрахунки:
- Підсумовування сум за кожною валютою
- Коректне врахування дублікатів
7. 📊 Формування структурованого результату
Замість звичайного тексту система формує:
✔ Підсумкову таблицю рахунків-фактур
- Ідентифікатор рахунку-фактури
- Дата
- Постачальник
- Сума
- Валюта
✔ Підсумкові суми за валютами
- Згруповані
- Розраховані
- Чітко розділені та структуровані
Де Agentic RAG розкриває свій повний потенціал
Цей процес не є лінійним. Усередині агент виконує:
- Вилучення даних → оцінювання → перевірку → повторний розрахунок
- Коригування логіки на основі проміжних результатів
Традиційний RAG vs Agentic RAG
| Можливість | Традиційний RAG | Agentic RAG (elDoc) |
|---|---|---|
| Розуміння інформації з кількох документів | Обмежене | Високий рівень |
| Усунення дублікатів | ❌ | ✅ |
| Розрахунки | ❌ | ✅ |
| Структурований результат | Обмежені можливості | Високий рівень |
| Урахування контексту | Статичне | Динамічне |
| Точність | Нестабільна | Висока |
Що відрізняє Enterprise Agentic RAG: безпека, контроль доступу та довіра, закладені в архітектуру
Agentic RAG додає інтелектуальність до процесу пошуку та отримання даних, дозволяючи системам планувати дії, аналізувати інформацію та вдосконалювати результати. Проте в корпоративному середовищі одного лише інтелекту недостатньо. Ключовою вимогою є довіра. Саме тому в elDoc ми розвинули Agentic RAG до рівня Enterprise Agentic RAG, інтегрувавши безпеку, контроль доступу та механізми управління безпосередньо в архітектуру як її невід’ємні компоненти.
На відміну від стандартних систем Agentic RAG, які оптимізують процеси аналізу та пошуку інформації, Enterprise Agentic RAG працює в межах чітко визначених правил. Кожен запит, кожен етап отримання даних і кожна згенерована відповідь враховують як контекст, так і права доступу.
Це означає, що:
- Користувачі отримують доступ лише до тієї інформації, на перегляд якої мають відповідні права
- Агенти отримують дані відповідно до механізмів контролю доступу на основі ролей та атрибутів (RBAC/ABAC)
- Конфіденційні документи залишаються захищеними навіть під час багатокрокового аналізу та міркувань
👉 Система ставить не лише запитання «Що є релевантним?»
Вона також перевіряє: «Що дозволено?»
Безпека забезпечується на кількох рівнях:
- Контроль доступу на рівні документів забезпечує детальне керування правами доступу
- Фільтрація контексту гарантує, що отримані дані відповідають ролям користувачів
- Агенти, які враховують політики безпеки, динамічно коригують стратегії пошуку, щоб уникати доступу до обмеженого контенту
- Розгортання в локальній інфраструктурі (on-premise) або приватній хмарі забезпечує повний контроль над даними та їх суверенітет
Крім того, кожна дія підлягає аудиту та відстеженню:
- Які дані були отримані
- Який контекст було використано
- Як саме була сформована кінцева відповідь
Це має критичне значення для галузей із жорсткими нормативними вимогами, де прозорість процесів є обов’язковою умовою.
Від документів до рішень з elDoc Agentic RAG
Те, що ми створили в elDoc Vioma, – це більше, ніж система RAG. Це перехід до Agentic RAG, де ШІ не просто знаходить інформацію, а активно її розуміє, аналізує та працює з корпоративними даними.
Поєднавши гібридний пошук і отримання даних, оркестрацію на основі агентів та мультимодальну обробку, ми створили систему, здатну працювати зі складними реальними сценаріями – відсканованими документами, фрагментованими даними та великими масивами знань, забезпечуючи при цьому точні, структуровані та придатні для практичного використання результати.
Саме це забезпечує перетворення:
- Даних → на контекст
- Контексту → на цінні висновки
- Висновків → на обґрунтовані рішення
Якщо ви прагнете вийти за межі базового RAG і розкрити справжній потенціал інтелектуальної роботи з документами в корпоративному масштабі, саме час дізнатися, на що здатний агентний RAG у вашому середовищі.
👉 Дізнайтеся, як elDoc може привнести інтелект у ваші корпоративні дані.