Jak zbudowaliśmy solidną platformę Enterprise Agentic RAG w elDoc dla prawdziwej inteligencji dokumentów na dużą skalę

Przedsiębiorstwom nie brakuje danych — brakuje im możliwości inteligentnego wykorzystania danych, które już posiadają. W rzeczywistości problem jest znacznie głębszy, niż większość organizacji zdaje sobie sprawę. Zdecydowana większość wiedzy przedsiębiorstwa nie znajduje się w uporządkowanych bazach danych ani starannie ustrukturyzowanych systemach. Istnieje w zeskanowanych plikach PDF, obrazach, zdjęciach, odręcznie wypełnionych formularzach, umowach, fakturach i archiwach starszego typu — czyli w danych, które nigdy nie zostały zaprojektowane z myślą o odczycie maszynowym.
To właśnie nazywamy enterprise dark data.
Występują wszędzie:
- Wieloletnie archiwa zeskanowanych umów przechowywane w repozytoriach dokumentów
- Dokumenty compliance zapisane jako nieustrukturyzowane pliki PDF
- Zdjęcia formularzy, raportów i danych terenowych
- E-maile i załączniki ukryte w odseparowanych systemach
- Starsze systemy eksportujące statyczne pliki, których nie można przeszukiwać
⚠️ Ukryty problem
Większość inicjatyw AI po cichu pomija tę warstwę danych. Dlaczego?
Ponieważ jest to trudne.
Tradycyjne pipeline’y opierają się na:
- Czystym tekście
- Ustrukturyzowanych bazach danych
- Wstępnie przetworzonych treściach
Jednak w rzeczywistości:
Nawet 70–80% danych przedsiębiorstw ma charakter nieustrukturyzowany, a znaczna ich część występuje w formie obrazów lub zeskanowanych dokumentów.
Oznacza to, że:
- Kluczowa wiedza pozostaje niewidoczna dla systemów wyszukiwania
- Modele LLM działają w oparciu o niepełny kontekst
- Procesy decyzyjne opierają się na niepełnych informacjach
👉 Efekt?
AI, które brzmi inteligentnie, ale nie opiera się na pełnym obrazie danych przedsiębiorstwa.
🧠 Dlaczego same modele LLM nie wystarczą
Duże modele językowe są bardzo zaawansowane, jednak mają jedno fundamentalne ograniczenie:
Wiedzą tylko to, co zostanie im dostarczone.
Jeśli warstwa retrieval pomija:
- Zeskanowane dokumenty
- Obrazy
- Niezindeksowane pliki PDF
Wówczas system AI pozostaje praktycznie ślepy na ogromną część wiedzy przedsiębiorstwa.
💡 Nasze podejście w elDoc
W elDoc nie potraktowaliśmy tego jako marginalnego wyjątku — uznaliśmy to za kluczowy problem.
Zadaliśmy sobie pytanie:
Jak włączyć WSZYSTKIE dane przedsiębiorstwa, zwłaszcza ich nieuporządkowaną, nieustrukturyzowaną i opartą na obrazach większość, do inteligentnego systemu umożliwiającego wyszukiwanie i analizę?
Co ważniejsze:
Jak zrobić to w sposób, który pozwoli AI nie tylko wyszukiwać informacje, lecz także je rozumieć, analizować i bezpiecznie wykorzystywać na dużą skalę?
Wewnątrz elDoc: jak działa nasza architektura Agentic RAG na dużą skalę
Zaprojektowanie systemu Agentic RAG to jedno. Zapewnienie jego niezawodności, wysokiej dokładności i skalowalności dla milionów dokumentów przedsiębiorstwa to zupełnie inne wyzwanie.
W elDoc podeszliśmy do tego problemu od podstaw:
Skoro skuteczność AI zależy od jakości pozyskiwanych danych, retrieval musi być projektowany jako kluczowy element architektury, a nie dodatek wdrażany na końcu procesu.
Kluczowy przełom: hybrydowa architektura retrieval
Jednym z pierwszych wyzwań, z którymi się zmierzyliśmy, była jakość retrieval.
Dane przedsiębiorstwa są:
- Niespójne
- Multimodalne
- Słabo ustrukturyzowane
- Rozproszone pomiędzy różnymi systemami
Szybko dostrzegliśmy również fundamentalne ograniczenie:
Żadna pojedyncza metoda retrieval nie działa skutecznie dla wszystkich danych przedsiębiorstwa.
- Wyszukiwanie wektorowe ma trudności z dokładnym dopasowaniem treści (np. konkretnych zapisów umownych)
- Wyszukiwanie słów kluczowych nie rozumie znaczenia semantycznego
- Same metadane nie zapewniają wystarczającej głębi kontekstu
Dlatego zamiast wybierać jedno podejście, połączyliśmy je ze sobą.
Wielowarstwowy system retrieval
Stworzyliśmy hybrydową architekturę retrieval, która stanowi fundament platformy elDoc. Każda warstwa odpowiada za rozwiązanie innego aspektu problemu:
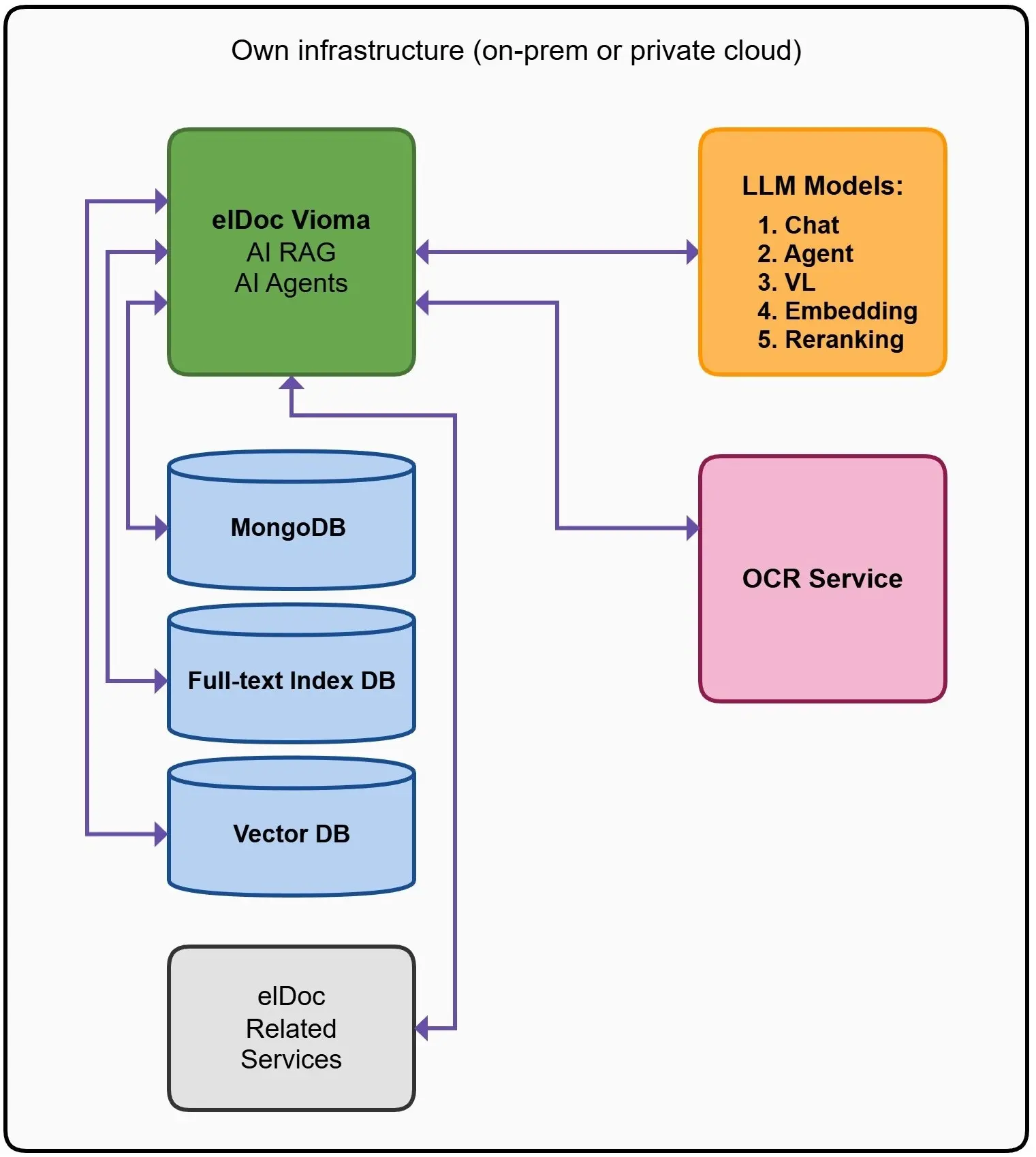
🗄️ Warstwa kontekstowa — MongoDB
Ta warstwa odpowiada za utrzymanie kontekstu i struktury danych.
Przechowuje:
- Metadane dokumentów
- Powiązania pomiędzy encjami
- Kontekst użytkownika i sesji
- Stan workflow oraz agentów
💡 Dlaczego to ma znaczenie
Retrieval przestaje być procesem pozbawionym kontekstu.
Agenci mogą:
- Rozumieć, kto zadaje pytanie
- Śledzić, jakie informacje zostały już pobrane
- Utrzymywać kontekst w wieloetapowym procesie wnioskowania
👉 To właśnie umożliwia prawdziwie agentowe działanie systemu, a nie jedynie wyszukiwanie informacji.
📄 Warstwa precyzji — wyszukiwanie pełnotekstowe
Ta warstwa zapewnia dokładność tam, gdzie ma ona największe znaczenie.
Odpowiada za:
- Dokładne dopasowanie słów kluczowych
- Zapisy prawne i umowne
- Dokumenty zgodności (compliance)
- Ustrukturyzowane zapytania
💡 Dlaczego to ma znaczenie
W środowisku enterprise:
- „Prawie poprawne” odpowiedzi są niewystarczające
- Nawet niewielka zmiana sformułowania może całkowicie zmienić znaczenie
👉 Ta warstwa gwarantuje precyzję i niezawodność.
🧠 Warstwa semantyczna — baza wektorowa
Ta warstwa odpowiada za rozumienie kontekstu i znaczenia danych.
Umożliwia:
- Retrieval oparty na podobieństwie semantycznym
- Wyszukiwanie uwzględniające kontekst
- Odkrywanie informacji wykraczających poza dokładne słowa kluczowe
💡 Dlaczego to ma znaczenie
Użytkownicy nie zawsze wiedzą, jak poprawnie sformułować zapytanie.
Dzięki tej warstwie system potrafi:
- Interpretować intencję użytkownika
- Znajdować istotne informacje, nawet jeśli użyte sformułowania się różnią
👉 Właśnie tutaj RAG staje się naprawdę inteligentny.
Od RAG do Agentic RAG: punkt zwrotny w rozwoju elDoc
Kiedy rozpoczynaliśmy budowę platformy elDoc, nie zaczynaliśmy od Agentic RAG. Podobnie jak większość systemów, rozpoczęliśmy od tradycyjnego RAG. Rozwiązanie działało… ale tylko do pewnego momentu.
⚠️ Ograniczenia tradycyjnego RAG
Już na wczesnym etapie wdrożeń zauważyliśmy powtarzające się ograniczenia:
- Jednorazowy retrieval często pomijał kluczowy kontekst
- Zapytania zwracały jedynie częściowo trafne wyniki
- System nie potrafił dostosować działania, gdy wyniki były słabe
- Nie rozumiał, którą metodę retrieval należy zastosować
- Słabo radził sobie ze złożonymi, wieloetapowymi zapytaniami enterprise
Co najważniejsze:
System nie miał świadomości własnych ograniczeń.
Wykonywał retrieval tylko raz i „zakładał”, że uzyskany wynik będzie wystarczający.
💡 Kluczowy wniosek
Szybko zrozumieliśmy, że problem nie leży w generowaniu odpowiedzi. Problemem był sposób organizacji procesu retrieval.
To doprowadziło nas do fundamentalnej zmiany podejścia:
RAG nie powinien być jedynie pipeline’em — powinien działać jako system podejmowania decyzji.
Przełom: wprowadzenie Agentic RAG
Przekształciliśmy naszą architekturę z modelu:
Pobieranie → Generowanie
w model:
Zrozumienie → Planowanie → Pobieranie → Ocena → Doprecyzowanie → Generowanie
To właśnie nazywamy Agentic RAG.
🔑 Co się zmieniło?
Zamiast traktować retrieval jako stały etap procesu, wprowadziliśmy agentów AI, którzy:
- Decydują, w jaki sposób przeprowadzić retrieval
- Wybierają systemy, które należy odpytać
- Oceniają jakość pozyskanych wyników
- Udoskonalają proces i ponawiają działania, gdy jest to konieczne
Agentic RAG w praktyce: analiza danych i inteligentne przetwarzanie w elDoc
Zrzut ekranu przedstawia bardzo praktyczny scenariusz enterprise:
Użytkownik wybiera wiele dokumentów faktur i zadaje polecenie:
„Przygotuj podsumowanie wszystkich tych faktur i oblicz łączną kwotę”.
W rzeczywistości jest to problem wymagający wieloetapowego rozumowania na nieustrukturyzowanych dokumentach.
I właśnie tutaj Agentic RAG pokazuje swoją przewagę.
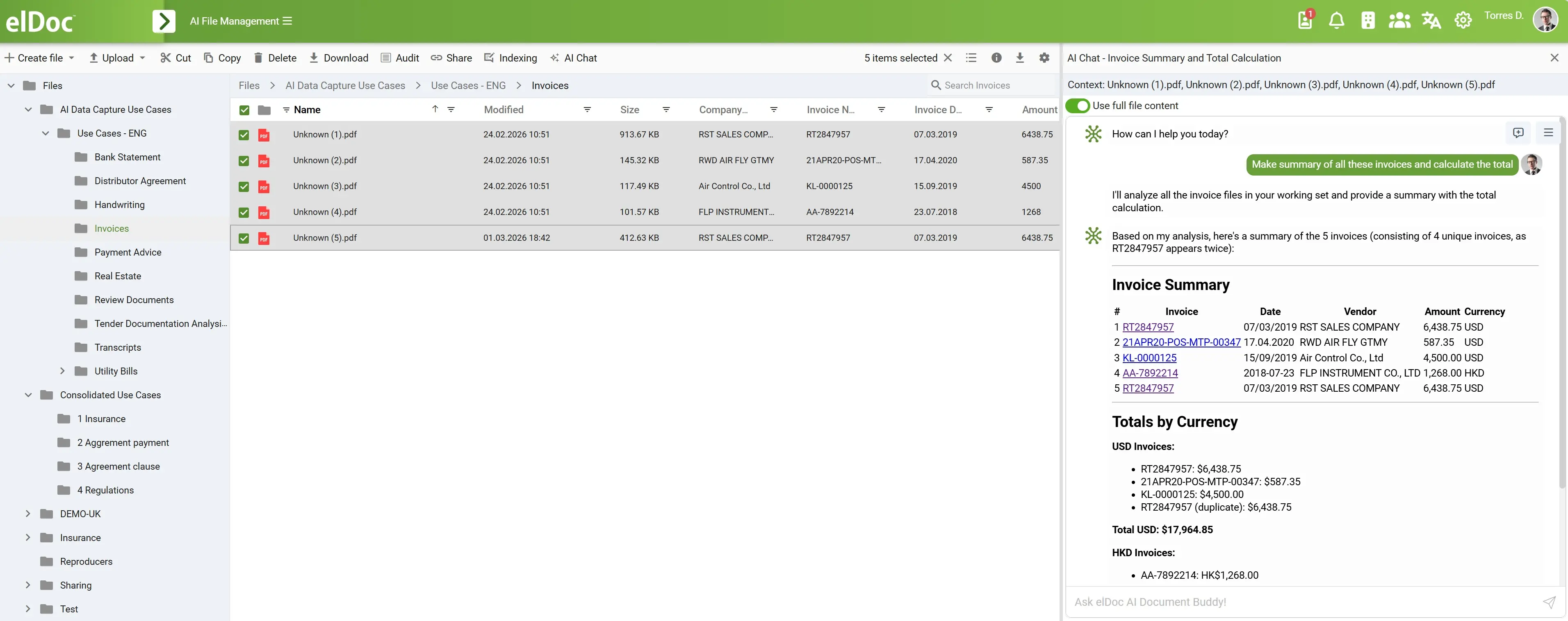
Dlaczego jest to problem agentowy, a nie tylko klasyczny RAG
Tradycyjny system RAG:
- Pobierałby fragmenty dokumentów
- Przekazywałby je do modelu LLM
- Generowałby podsumowanie
Jednak takie podejście miałoby trudności z:
- Wykrywaniem duplikatów faktur
- Agregacją danych z wielu dokumentów
- Grupowaniem danych według walut
- Generowaniem ustrukturyzowanego wyniku
👉 W efekcie system najprawdopodobniej wygenerowałby niepełną lub nieprawidłową odpowiedź.
Jak Agentic RAG w elDoc rozwiązuje ten problem krok po kroku
1. 🧠 Rozumienie intencji użytkownika
Agent nie tylko odczytuje polecenie — interpretuje jego znaczenie:
- To nie jest zwykłe podsumowanie
- Zadanie wymaga agregacji danych oraz obliczeń
- Obejmuje wiele dokumentów analizowanych jako jeden zbiór danych
- Wynik musi być uporządkowany i precyzyjny
2. 📂 Rozszerzenie kontekstu (tryb pełnych dokumentów)
W interfejsie użytkownika:
Włączona jest opcja „Use full file content”
Powoduje to, że system:
- Traktuje wszystkie wybrane faktury jako zamknięty zbiór danych
- Pobiera pełną zawartość dokumentów, a nie jedynie fragmenty
- Przygotowuje się do analizy i wnioskowania między dokumentami
3. 🔍 Retrieval obejmujący wiele dokumentów
System Agentic RAG:
- Ekstrahuje dane ze wszystkich wybranych plików PDF
- Wykorzystuje OCR (jeśli jest to konieczne) do odczytu treści faktur
- Identyfikuje kluczowe pola:
- Numer faktury
- Dostawcę
- Datę
- Kwotę
- Walutę
👉 To nie jest już zwykły retrieval — to ustrukturyzowana ekstrakcja danych.
4. 🧩 Normalizacja i ujednolicanie danych
Następnie agent:
- Ujednolica wyodrębnione dane do spójnego formatu
- Wykrywa duplikaty
- Przykład: numer
RT2847957pojawia się dwukrotnie
- Przykład: numer
- Rozróżnia faktury na podstawie:
- ID
- Dostawcy
- Daty
👉 Ten etap ma kluczowe znaczenie i jest niemożliwy do zrealizowania przy użyciu prostego RAG.
5. 🎯 Wnioskowanie i usuwanie duplikatów
System identyfikuje:
- Wybrano 5 plików
- Jednak tylko 4 unikalne faktury
Wymaga to:
- Logicznego porównania danych
- Wnioskowania pomiędzy dokumentami
- Strategii deduplikacji
💡 To kluczowy moment działania Agentic AI:
System analizuje i weryfikuje dane, a nie tylko je prezentuje.
6. 🧮 Agregacja i obliczenia
Następnie agent wykonuje:
Grupowanie danych według walut:
- Faktury w USD
- Faktury w HKD
Obliczenia:
- Sumowanie kwot dla każdej waluty
- Prawidłową obsługę duplikatów
7. 📊 Generowanie ustrukturyzowanego wyniku
Zamiast zwykłego tekstu system generuje:
✔ Tabelę podsumowującą faktury
- ID faktury
- Data
- Dostawca
- Kwota
- Waluta
✔ Podsumowanie według walut
- Dane pogrupowane
- Obliczone
- Wyraźnie rozdzielone
Gdzie Agentic RAG pokazuje pełnię swoich możliwości
Ten workflow nie ma charakteru liniowego. Agent wewnętrznie:
- Ekstrahuje → ocenia → weryfikuje → przelicza dane
- Dostosowuje logikę działania na podstawie wyników pośrednich
Tradycyjny RAG vs Agentic RAG
| Możliwości | Tradycyjny RAG | Agentic RAG (elDoc) |
|---|---|---|
| Rozumienie wielu dokumentów | Ograniczone | Zaawansowane |
| Deduplikacja | ❌ | ✅ |
| Obliczenia | ❌ | ✅ |
| Strukturalne wyniki | Słabe | Silne |
| Świadomość kontekstu | Statyczna | Dynamiczna |
| Dokładność | Niewystarczająca | Wysoka |
Co wyróżnia Enterprise Agentic RAG: bezpieczeństwo, kontrola dostępu i zaufanie wbudowane w architekturę
Agentic RAG wnosi inteligencję do procesu retrieval, umożliwiając systemom planowanie, wnioskowanie i iteracyjne działanie. Jednak w środowisku enterprise sama inteligencja nie wystarcza. Kluczowym wymaganiem jest zaufanie. W elDoc rozwijaliśmy Agentic RAG w kierunku Enterprise Agentic RAG, wbudowując bezpieczeństwo, kontrolę dostępu oraz governance bezpośrednio w architekturę — nie jako dodatek, lecz jako jej fundamentalny element.
W przeciwieństwie do standardowych systemów Agentic RAG, które koncentrują się na optymalizacji wnioskowania i retrieval, Enterprise Agentic RAG działa w ściśle określonych granicach. Każde zapytanie, każdy etap retrieval oraz każda wygenerowana odpowiedź uwzględnia zarówno kontekst, jak i uprawnienia użytkownika.
Oznacza to, że:
- Użytkownicy mają dostęp wyłącznie do danych, do których są uprawnieni
- Agenci pobierają dane w oparciu o kontrolę dostępu opartą na rolach i atrybutach (RBAC/ABAC)
- Poufne dokumenty pozostają chronione nawet w trakcie wieloetapowego wnioskowania
👉 System nie zadaje sobie wyłącznie pytania „co jest istotne?”
Zadaje również pytanie „co jest dozwolone?”
Bezpieczeństwo jest egzekwowane na wielu poziomach:
- Uprawnienia na poziomie dokumentów zapewniają precyzyjną kontrolę dostępu
- Filtrowanie kontekstu gwarantuje, że pobierane dane uwzględniają role użytkowników
- Agenci uwzględniający polityki bezpieczeństwa dynamicznie dostosowują strategie retrieval, aby unikać treści objętych ograniczeniami
- Prywatne wdrożenie (on-premise lub private cloud) zapewnia pełną suwerenność danych
Dodatkowo każda akcja jest audytowalna i możliwa do prześledzenia:
- Jakie dane zostały pobrane
- Jaki kontekst został wykorzystany
- Jak została wygenerowana końcowa odpowiedź
Ma to kluczowe znaczenie w branżach silnie regulowanych, gdzie transparentność jest wymogiem bezwzględnym.
Od dokumentów do decyzji z elDoc Agentic RAG
To, co zbudowaliśmy w elDoc Vioma, to coś więcej niż system RAG — to przejście w stronę Agentic RAG, gdzie AI nie tylko wyszukuje informacje, ale aktywnie je rozumie, wnioskuje i pracuje na danych enterprise.
Łącząc hybrydowy retrieval, orkiestrację opartą na agentach oraz przetwarzanie multimodalne, stworzyliśmy system zdolny do obsługi rzeczywistej złożoności — zeskanowanych dokumentów, rozproszonych danych i dużych zbiorów wiedzy — przy jednoczesnym dostarczaniu dokładnych, ustrukturyzowanych i użytecznych wyników.
To właśnie powoduje transformację:
- Dane → w kontekst
- Kontekst → w insight (wnioski)
- Wnioski → w decyzje
Jeśli chcesz wyjść poza podstawowy RAG i odblokować prawdziwą inteligencję dokumentów na dużą skalę, czas sprawdzić, co Agentic RAG może zrobić w Twoim środowisku.
👉 Odkryj, jak elDoc może wnieść inteligencję do Twoich danych enterprise.