Cómo construimos una sólida plataforma Enterprise Agentic RAG en elDoc para lograr inteligencia documental real a escala

Las empresas no carecen de datos; carecen de inteligencia sobre sus datos. De hecho, el problema es mucho más profundo de lo que la mayoría de las organizaciones imagina. Una gran parte del conocimiento empresarial no se encuentra en bases de datos limpias ni en sistemas perfectamente estructurados. Existe en archivos PDF escaneados, imágenes, fotografías, formularios escritos a mano, contratos, facturas y archivos heredados: datos que nunca fueron diseñados para ser legibles por máquinas.
Esto es lo que llamamos dark data empresarial.
Está en todas partes:
- Décadas de contratos escaneados almacenados en repositorios documentales
- Documentos de compliance almacenados como PDF sin estructura
- Fotografías de formularios, reportes y datos de campo
- Correos electrónicos y archivos adjuntos ocultos en sistemas desconectados
- Sistemas heredados que exportan archivos estáticos imposibles de consultar
⚠️ El problema oculto
La mayoría de las iniciativas de IA ignoran silenciosamente esta capa de datos. ¿Por qué?
Porque es difícil.
Los pipelines tradicionales dependen de:
- Texto limpio
- Bases de datos estructuradas
- Contenido preprocesado
Pero en la práctica:
Hasta el 70–80 % de los datos empresariales son no estructurados, y una gran parte de ellos está basada en imágenes o documentos escaneados.
Esto significa:
- El conocimiento crítico es invisible para los sistemas de búsqueda
- Los LLM operan con contexto parcial
- La toma de decisiones se basa en información incompleta
👉 ¿El resultado?
Una IA que parece inteligente, pero que no está fundamentada en toda la realidad de los datos empresariales.
🧠 Por qué los LLM por sí solos no son suficientes
Los Large Language Models son poderosos, pero tienen una limitación fundamental:
Solo conocen la información que se les proporciona.
Si tu capa de retrieval ignora:
- documentos escaneados
- imágenes
- PDF no indexados
Entonces, tu sistema de IA queda prácticamente ciego ante una enorme parte del conocimiento empresarial.
💡 Nuestra visión en elDoc
En elDoc, no tratamos esto como un caso aislado, sino como el problema central.
Nos hicimos una pregunta:
¿Cómo integrar TODOS los datos empresariales, especialmente la gran mayoría desordenada, no estructurada y basada en imágenes, en un sistema inteligente y consultable?
Y, aún más importante:
¿Cómo hacerlo de una manera que permita a la IA no solo recuperar información, sino también comprenderla, razonar sobre ella y actuar de forma segura y escalable?
Dentro de elDoc: cómo funciona nuestra arquitectura Agentic RAG a escala
Diseñar un sistema Agentic RAG es una cosa. Hacerlo confiable, preciso y escalable para millones de documentos empresariales es otra completamente distinta.
En elDoc, abordamos este desafío desde los principios fundamentales:
Si la IA es tan buena como la información que recupera, entonces el retrieval debe diseñarse como un sistema de primera clase, no como algo secundario.
El avance clave: arquitectura de retrieval híbrido
Uno de los primeros desafíos que encontramos fue la calidad del retrieval.
Los datos empresariales son:
- Inconsistentes
- Multimodales
- Débilmente estructurados
- Distribuidos entre múltiples sistemas
Y rápidamente identificamos una limitación fundamental:
Ningún método de retrieval funciona por sí solo para todos los datos empresariales.
- La búsqueda vectorial tiene dificultades con las coincidencias exactas, por ejemplo, cláusulas contractuales
- La búsqueda por palabras clave pierde el significado semántico
- Los metadatos por sí solos carecen de profundidad
Por eso, en lugar de elegir un solo enfoque, los combinamos.
Un sistema de retrieval multicapa
Diseñamos una arquitectura de retrieval híbrido que funciona como la columna vertebral de elDoc. Cada capa resuelve una parte diferente del problema:
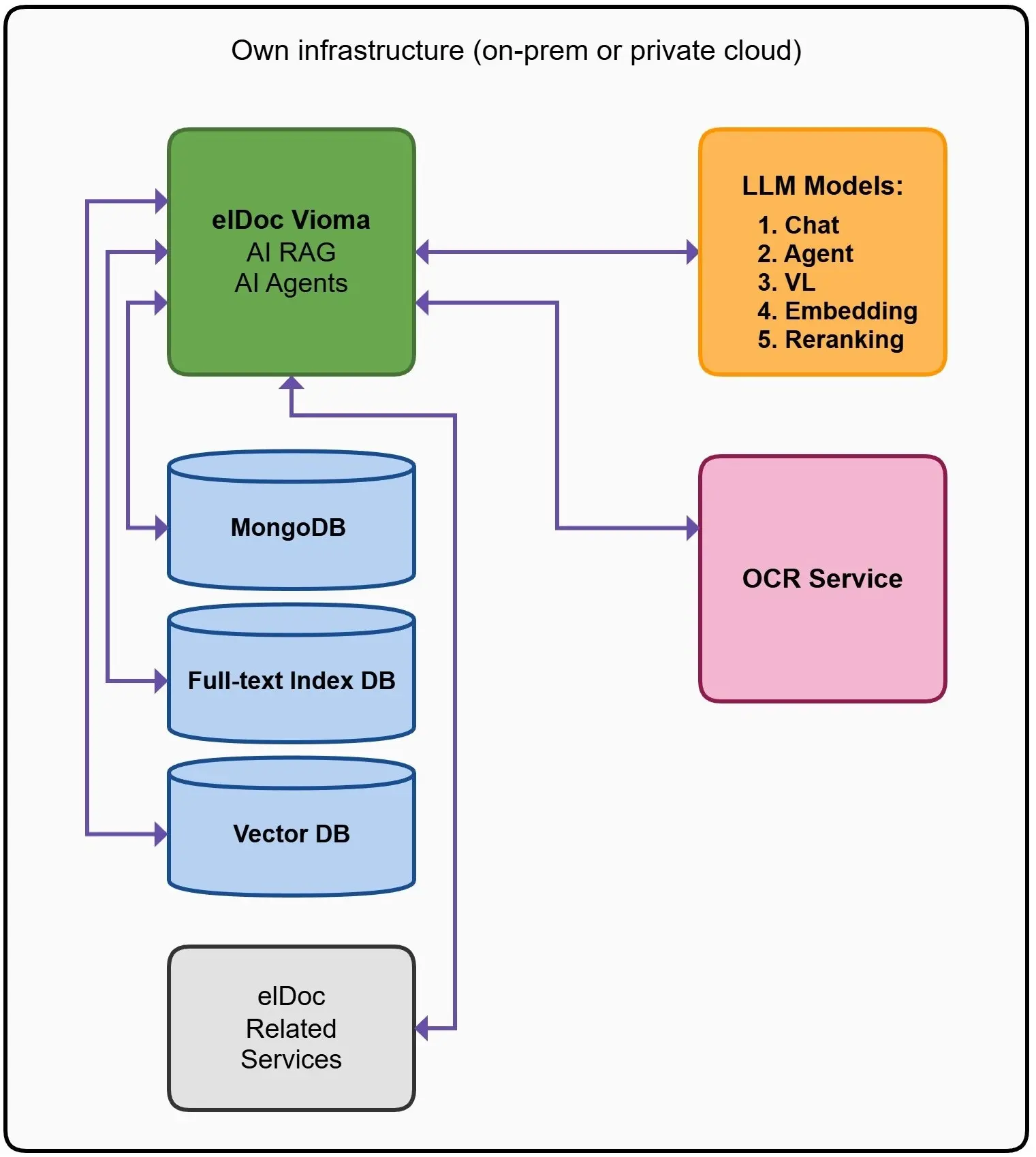
🗄️ Capa de contexto: MongoDB
Esta capa proporciona estado y estructura.
Almacena:
- Metadatos de documentos
- Relaciones entre entidades
- Contexto de usuario y sesión
- Estado de workflows y agentes
💡 Por qué es importante
El retrieval deja de ser un proceso sin estado.
Los agentes pueden:
- Comprender quién realiza la consulta
- Rastrear qué información ya fue recuperada
- Mantener el contexto durante procesos de razonamiento de múltiples pasos
👉 Esto es lo que permite un verdadero comportamiento agentic, y no solo búsqueda de información.
📄 Capa de precisión: búsqueda full-text
Esta capa garantiza precisión donde más importa.
Gestiona:
- Coincidencias exactas por palabras clave
- Cláusulas legales
- Documentos de compliance
- Consultas estructuradas
💡 Por qué es importante
En escenarios empresariales:
- “Casi correcto” no es aceptable
- Una formulación exacta puede cambiar completamente el significado
👉Esta capa garantiza precisión y confiabilidad.
🧠 Capa semántica: base de datos vectorial
Esta capa aporta comprensión.
Permite:
- Retrieval basado en similitud
- Búsqueda contextual
- Descubrimiento más allá de palabras clave exactas
💡 Por qué es importante
Los usuarios no siempre saben cómo formular sus consultas.
Esta capa garantiza que el sistema pueda:
- Interpretar la intención
- Encontrar información relevante, incluso cuando la redacción es diferente
👉 Aquí es donde RAG se vuelve verdaderamente inteligente.
De RAG a Agentic RAG: el punto de inflexión en elDoc
Cuando comenzamos a desarrollar nuestra plataforma en elDoc, no empezamos con Agentic RAG. Comenzamos donde empiezan la mayoría de los sistemas: con un RAG tradicional. Funcionaba… hasta cierto punto.
⚠️ Dónde falla el RAG tradicional
En las primeras implementaciones observamos limitaciones constantes:
- El retrieval de una sola ejecución solía omitir contexto crítico
- Las consultas devolvían resultados parcialmente relevantes
- No existía capacidad de adaptación cuando los resultados eran débiles
- No había comprensión sobre qué método de retrieval utilizar
- Manejo deficiente de consultas empresariales complejas y de múltiples pasos
Y, lo más importante:
El sistema no tenía conciencia de sus propias limitaciones.
Recuperaba información una sola vez y esperaba el mejor resultado posible.
💡 La conclusión
Comprendimos rápidamente que el problema no era la generación, sino la forma en que se orquestaba el retrieval.
Y eso nos llevó a un cambio fundamental:
RAG no debe ser un pipeline; debe ser un sistema de toma de decisiones.
El cambio: la introducción de Agentic RAG
Transformamos nuestra arquitectura de:
Recuperar → Generar
en:
Comprender → Planificar → Recuperar → Evaluar → Refinar → Generar
Esto es lo que llamamos Agentic RAG.
🔑 ¿Qué cambió?
En lugar de tratar el retrieval como un paso fijo, incorporamos agentes de IA que:
- Deciden cómo realizar el retrieval
- Eligen qué sistemas consultar
- Evalúan la calidad de los resultados recuperados
- Refinan y reintentan cuando es necesario
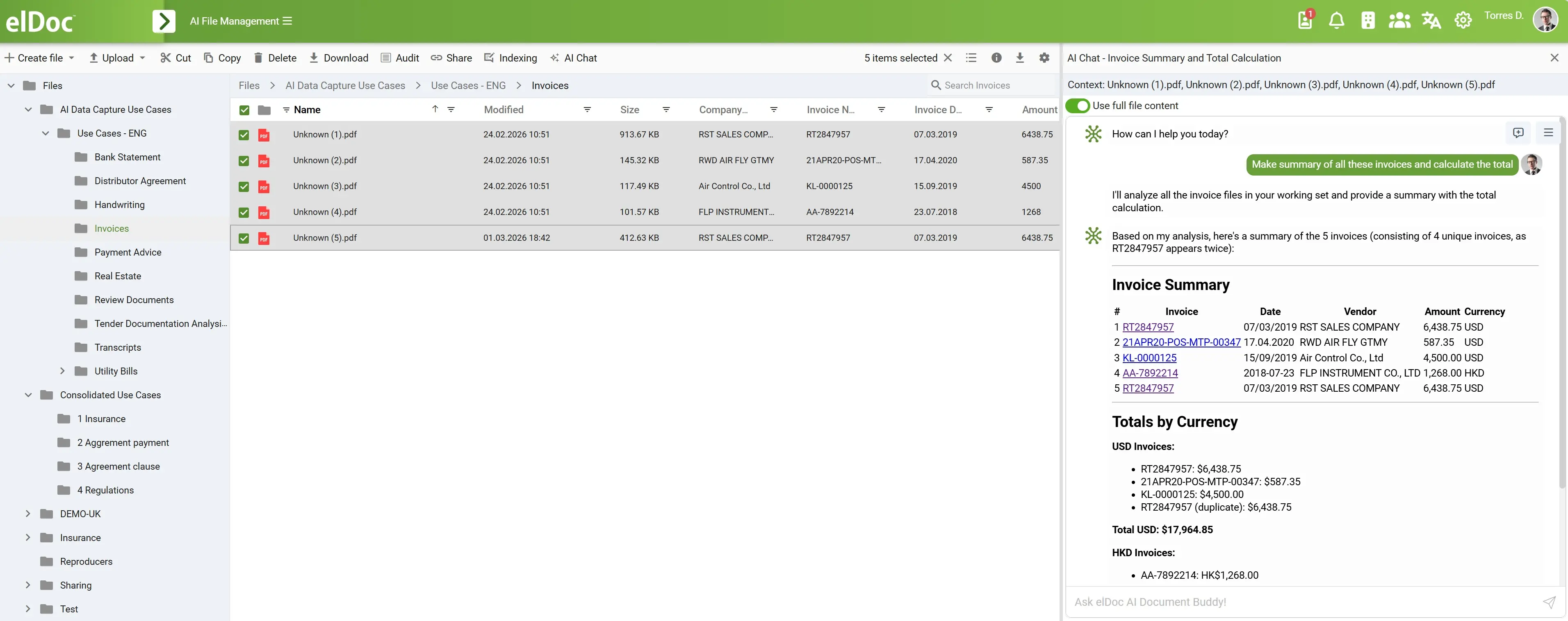
Agentic RAG en acción: análisis e inteligencia de datos en elDoc
La captura de pantalla muestra un escenario empresarial muy práctico:
Un usuario selecciona múltiples documentos de facturas y solicita:
“Genera un resumen de todas estas facturas y calcula el total”.
A primera vista, esto parece simple.
En realidad, se trata de un problema de razonamiento de múltiples pasos sobre documentos no estructurados.
Y precisamente aquí es donde Agentic RAG demuestra todo su potencial.
Qué convierte esto en un problema agentic (y no solo RAG)
Un sistema RAG tradicional:
- Recuperaría fragmentos de documentos
- Los enviaría a un LLM
- Generaría un resumen
Pero este enfoque tendría dificultades con:
- Facturas duplicadas
- Agregación de múltiples documentos
- Agrupación por moneda
- Generación de salidas estructuradas
👉 Muy probablemente produciría una respuesta incompleta o incorrecta.
Cómo Agentic RAG en elDoc resuelve esto paso a paso
1. 🧠 Comprensión de la intención
El agente no solo lee el prompt, sino que lo interpreta:
- No se trata de un simple resumen
- Requiere agregación y cálculo
- Involucra múltiples documentos como conjunto de trabajo
- La salida debe ser estructurada y precisa
2. 📂 Expansión de contexto (modo de documento completo)
Desde la interfaz:
La opción “usar todo el contenido del archivo” está habilitada
Esto permite que el sistema:
- Trate todas las facturas seleccionadas como un conjunto de datos delimitado
- Recupere el contenido completo de los documentos, y no solo fragmentos
- Se prepare para realizar razonamiento entre múltiples documentos
3. 🔍 Retrieval entre documentos
El sistema Agentic RAG:
- Extrae datos de todos los PDF seleccionados
- Utiliza OCR, si es necesario, para leer el contenido de las facturas
- Identifica campos clave:
- Número de factura
- Proveedor
- Fecha
- Importe
- Moneda
👉 Esto no es solo retrieval; es extracción estructurada de datos.
4. 🧩 Normalización y alineación de datos
Ahora el agente:
- Alinea los datos extraídos en un formato consistente
- Detecta duplicados
- Ejemplo:
RT2847957aparece dos veces
- Ejemplo:
- Diferencia las facturas según:
- ID
- Proveedor
- Fecha
👉 Este paso es crítico e imposible de lograr con un RAG básico.
5. 🎯 Razonamiento y eliminación de duplicados
El sistema identifica:
- 5 archivos seleccionados
- Pero solo 4 facturas únicas
Esto requiere:
- Comparación lógica
- Razonamiento entre documentos
- Estrategia de deduplicación
💡 Este es el momento clave de Agentic:
El sistema cuestiona los datos, no solo los reporta.
6. 🧮 Agregación y cálculo
Luego, el agente realiza:
Agrupación inteligente por moneda:
- Facturas en USD
- Facturas en HKD
Cálculos:
- Suma de totales por moneda
- Manejo correcto de duplicados
7. 📊 Generación de salidas estructuradas
En lugar de texto plano, el sistema genera:
✔ Tabla resumen de facturas
- ID de factura
- Fecha
- Proveedor
- Importe
- Moneda
✔ Totales por moneda
- Agrupados
- Calculados
- Claramente separados
Donde Agentic RAG realmente destaca
Este workflow no es lineal. Internamente, el agente:
- Extrae → evalúa → valida → recalcula
- Ajusta la lógica en función de hallazgos intermedios
RAG tradicional vs Agentic RAG
| Capacidad | RAG tradicional | Agentic RAG (elDoc) |
|---|---|---|
| Comprensión de múltiples documentos | Limitada | Avanzada |
| Deduplication | ❌ | ✅ |
| Cálculos | ❌ | ✅ |
| Salidas estructuradas | Débiles | Avanzadas |
| Comprensión contextual | Estática | Dinámica |
| Precisión | Poco confiable | Alta |
Qué diferencia a Enterprise Agentic RAG: seguridad, acceso y confianza desde el diseño
Agentic RAG incorpora inteligencia al retrieval, permitiendo que los sistemas planifiquen, razonen e iteren. Sin embargo, en entornos empresariales, la inteligencia por sí sola no es suficiente. El verdadero requisito es la confianza. En elDoc, evolucionamos Agentic RAG hacia Enterprise Agentic RAG integrando seguridad, control de acceso y gobernanza directamente en la arquitectura, no como algo secundario, sino como una capacidad central.
A diferencia de los sistemas Agentic RAG estándar, que se optimizan para razonamiento y retrieval, Enterprise Agentic RAG opera dentro de límites estrictos. Cada consulta, cada paso de retrieval y cada respuesta generada tienen en cuenta el contexto y los permisos de acceso.
Esto significa que:
- Los usuarios solo acceden a la información que tienen autorización para ver
- Los agentes recuperan datos basándose en controles de acceso basados en roles y atributos (RBAC/ABAC)
- Los documentos sensibles permanecen protegidos incluso durante procesos de razonamiento de múltiples pasos
👉 El sistema no solo pregunta “¿qué es relevante?”
También pregunta “¿qué está permitido?”.
La seguridad se aplica en múltiples niveles:
- Los permisos a nivel de documento garantizan un control de acceso granular
- El filtrado contextual garantiza que los datos recuperados respeten los roles de usuario
- Los agentes conscientes de las políticas ajustan dinámicamente las estrategias de retrieval para evitar contenido restringido
- El despliegue privado, ya sea on-premise o en nube privada, garantiza soberanía total sobre los datos
Además, cada acción es auditable y trazable:
- Qué datos fueron recuperados
- Qué contexto se utilizó
- Cómo se generó la respuesta final
Esto es fundamental para industrias altamente reguladas, donde la transparencia no es negociable.
De los documentos a las decisiones con elDoc Agentic RAG
Lo que construimos con elDoc Vioma es mucho más que un sistema RAG; es una evolución hacia Agentic RAG, donde la IA no solo recupera información, sino que también comprende, razona y trabaja activamente con datos empresariales.
Al combinar retrieval híbrido, orquestación basada en agentes y procesamiento multimodal, desarrollamos un sistema capaz de manejar la complejidad del mundo real: documentos escaneados, datos fragmentados y conocimiento a gran escala, mientras entrega resultados precisos, estructurados y accionables.
Esto es lo que transforma:
- Datos → en contexto
- Contexto → en insights
- Insights → en decisiones
Si buscas ir más allá del RAG básico y desbloquear una verdadera inteligencia documental a escala, es momento de descubrir lo que Agentic RAG puede hacer en tu entorno empresarial.
👉 Descubre cómo elDoc puede aportar inteligencia a tus datos empresariales.