如何在 elDoc 中打造強大的 Enterprise Agentic RAG 平台,實現大規模文件智慧化

企業並不缺乏資料,而是缺乏能夠真正理解與運用資料的智慧能力。事實上,這個問題比大多數企業所意識到的更加深層。絕大多數的企業知識,並不存在於乾淨的資料庫或結構化完善的系統中,而是散落於掃描 PDF、圖片、照片、手寫表單、合約、發票與舊式檔案庫中,這些資料從一開始就不是為了讓機器能夠讀取與理解而設計的。
這就是我們所稱的企業暗資料(Enterprise Dark Data)。
它無所不在:
- 數十年累積的掃描合約,存放於文件儲存庫中
- 以 PDF 格式保存、缺乏結構化的合規文件
- 表單、報告與現場資料的照片
- 分散於彼此孤立系統中的電子郵件與附件
- 舊式系統匯出的靜態且無法查詢的檔案
⚠️ 被忽視的核心問題
大多數 AI 專案都在不知不覺中忽略了這一層資料。 為什麼?
因為這非常困難。
傳統資料流程通常依賴於:
- 乾淨且可讀的文字資料
- 結構化資料庫
- 已預先處理的內容
但現實情況是:
高達 70% 至 80% 的企業資料屬於非結構化資料,其中相當大一部分還是以影像或掃描文件形式存在。
這代表:
- 關鍵知識無法被搜尋系統有效識別
- 大型語言模型(LLMs)只能基於不完整的上下文運作
- 決策建立在不完整的資訊之上
👉 最終結果是什麼?
AI 看似聰明,但實際上並未建立在完整且真實的企業資料基礎之上。
🧠 為什麼僅靠 LLMs 並不足夠
大型語言模型(LLMs)雖然功能強大,但存在一個根本性的限制:
它們只能理解與處理被提供給它們的內容。
如果您的資料檢索層忽略了:
- 掃描文件
- 圖像與圖片
- 未建立索引的 PDF 文件
那麼您的 AI 系統,實際上將無法看見龐大的企業知識資產。
💡 elDoc 的觀點
在 elDoc,我們並未將這視為少數特殊情況,而是將其視為企業 AI 的核心問題。
我們思考的是:
如何將所有企業資料,尤其是那些雜亂、非結構化、以影像為主的大量資料,整合進一個具備智慧能力且可查詢的系統中?
更重要的是:
我們該如何建立一套方法,讓 AI 不只是檢索資訊,而是真正能夠理解、推理,並以安全且可擴展的方式執行行動?
深入 elDoc:我們的 Agentic RAG 架構如何實現大規模運作
建立一套 Agentic RAG 系統是一回事,但要讓它在數百萬份企業文件環境中依然保持可靠、精準且具備可擴展性,則是另一項更大的挑戰。
在 elDoc,我們從最根本的原則出發來解決這個問題:
如果 AI 的能力取決於它能取得哪些資料,那麼資料檢索機制就必須被視為核心系統來設計,而不是事後補強的附加功能。
核心突破:混合式檢索架構
我們最早面臨的挑戰之一,就是資料檢索品質。
企業資料具有以下特性:
- 格式不一致
- 多模態
- 缺乏良好的結構化
- 分散於不同系統之中
我們很快便意識到一個根本性的限制:
沒有任何單一檢索方法,能夠適用於所有企業資料。
- 向量搜尋難以處理精確匹配需求,例如合約條款
- 關鍵字搜尋無法真正理解語意
- 單靠中繼資料缺乏足夠的上下文深度
因此,我們並未只選擇單一方法,而是將多種方法整合在一起。
多層式檢索系統
我們打造了一套混合式檢索架構,作為 elDoc 的核心骨幹。每一層架構都專門解決不同面向的問題:
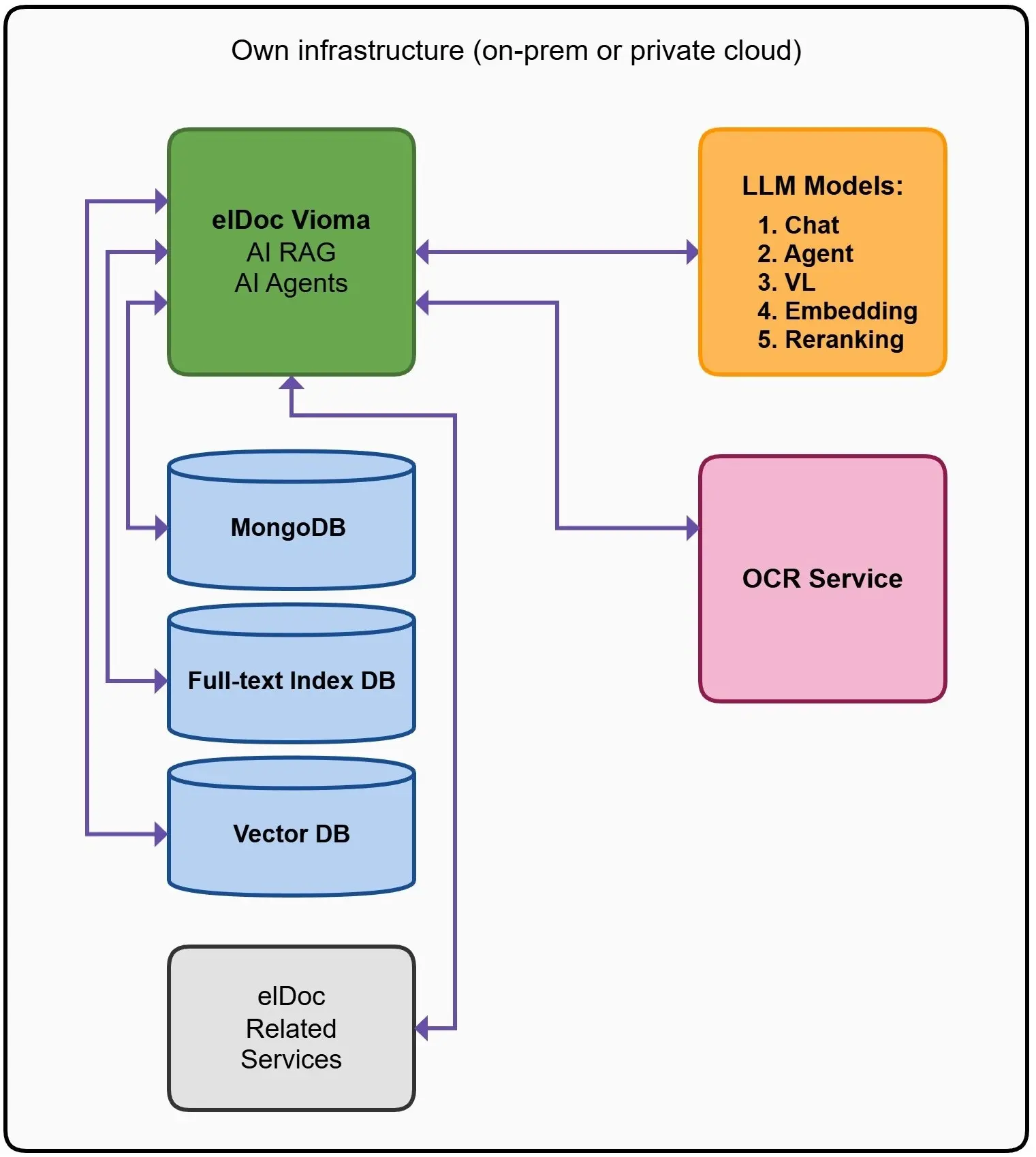
🗄️ 上下文層:MongoDB
此層負責提供狀態管理與資料結構。
它儲存:
- 文件中繼資料
- 實體之間的關聯性
- 使用者與工作階段上下文
- 工作流程與 AI Agent 狀態
💡 為什麼這很重要
資料檢索不再是無狀態的流程。
AI Agents 可以:
- 理解提問者的身份與角色
- 追蹤已經檢索過的內容
- 在多步驟推理過程中維持上下文一致性
👉 這正是真正 Agentic 行為的基礎,而不只是單純搜尋。
📄 精準層:全文搜尋
此層確保在最關鍵的場景中維持高度精準性。
它負責處理:
- 精確關鍵字匹配
- 法律條款
- 合規文件
- 結構化查詢
💡 為什麼這很重要
在企業環境中:
- 「幾乎正確」是無法被接受的
- 細微的措辭差異,都可能完全改變內容含義
👉 此層能夠確保精準度與可靠性。
🧠 語意層:向量資料庫
此層賦予系統真正的理解能力。
它能夠實現:
- 基於相似性的檢索
- 具備上下文理解能力的搜尋
- 超越精確關鍵字的資訊發現能力
💡 為什麼這很重要
使用者並不一定知道該如何正確描述查詢需求。
此層可確保系統能夠:
- 理解使用者意圖
- 即使措辭不同,也能找到相關資訊
👉 這正是 RAG 真正具備智慧能力的關鍵。
從 RAG 到 Agentic RAG:elDoc 的關鍵轉折
當 elDoc 開始打造平台時,我們並不是一開始就採用 Agentic RAG,而是和大多數系統一樣,先從傳統 RAG 開始。它確實有效,但也只能做到某個程度。
⚠️ 傳統 RAG 的限制
在早期實作中,我們持續觀察到以下限制:
- 單次檢索經常遺漏關鍵上下文
- 查詢結果往往只有部分相關
- 當檢索結果品質不佳時,系統無法自我調整
- 無法判斷應該使用哪一種檢索方法
- 難以有效處理複雜、多步驟的企業查詢
最重要的是:
系統本身完全無法意識到自身的限制。
它只進行一次檢索,然後期待結果足夠好。
💡 關鍵洞察
我們很快便理解到,真正的問題不在於生成能力,而在於資料檢索是如何被協調與執行的。
這也促使我們做出一個根本性的轉變:
RAG 不應只是單純的流程管線,而應該是一套具備決策能力的系統。
關鍵轉變:導入 Agentic RAG
我們將架構從:
檢索 → 生成
轉變為:
理解 → 規劃 → 檢索 → 評估 → 優化 → 生成
這就是我們所稱的 Agentic RAG。
🔑 有哪些改變?
我們不再將資料檢索視為固定步驟,而是導入 AI Agents,使其能夠:
- 決定應該如何進行檢索
- 選擇需要查詢的系統
- 評估檢索結果的品質
- 在必要時進行優化並重新嘗試
Agentic RAG 的實際應用:elDoc 中的資料分析與智慧能力
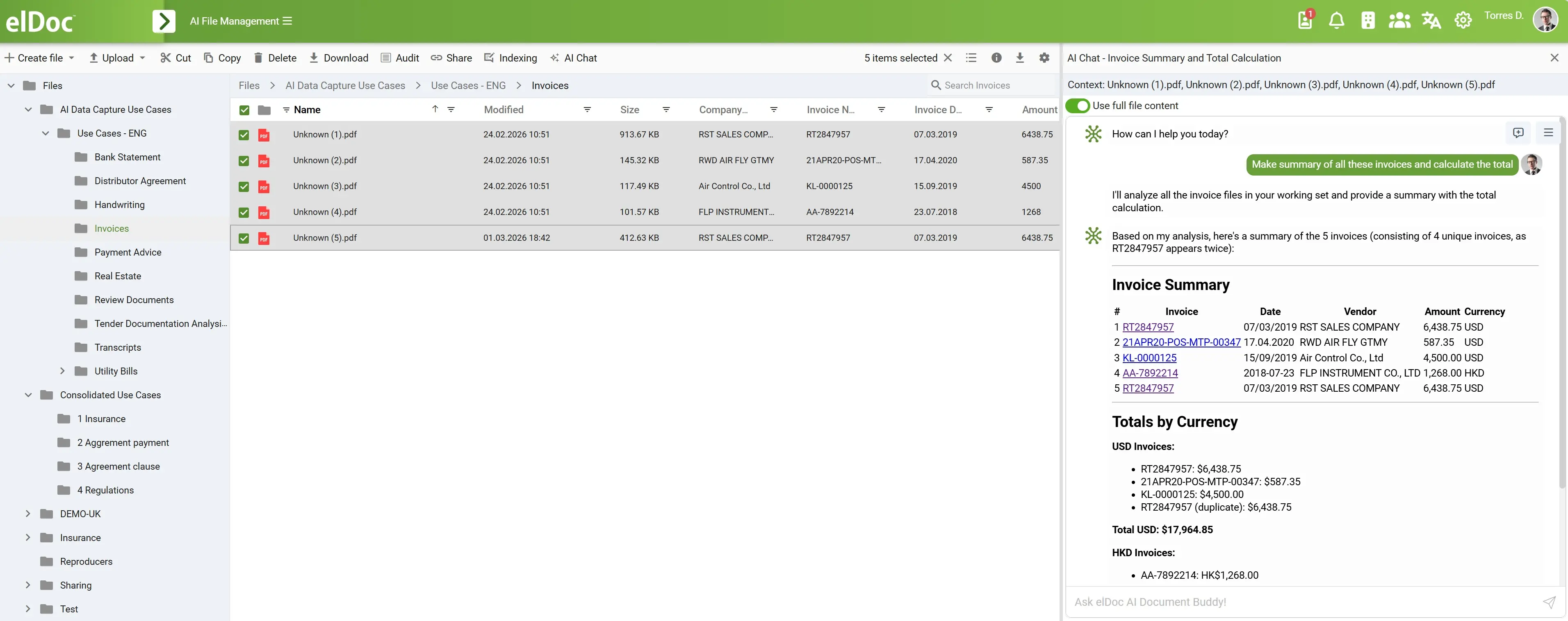
此畫面展示了一個非常典型的企業應用場景:
使用者選取多份發票文件後提出需求:
「請整理這些發票的摘要,並計算總金額。」
乍看之下,這似乎是一個簡單的任務。
但實際上,這是一個涉及非結構化文件的多步驟推理問題。
而這正是 Agentic RAG 展現真正價值的地方。
為什麼這是一個 Agentic 問題,而不只是傳統 RAG
傳統 RAG 系統通常會:
- 從文件中檢索內容片段
- 將內容輸入至 LLM
- 生成摘要
但這種方式通常難以處理:
- 重複發票
- 多文件資料彙整
- 幣別分類與分組
- 結構化輸出生成
👉 最終很可能產生不完整或不正確的結果。
elDoc 的 Agentic RAG 如何逐步解決這個問題
1. 🧠 理解使用者意圖
AI Agent 不只是讀取指令,而是會真正理解需求:
- 這不只是單純的摘要任務
- 還涉及資料彙整與計算
- 需要同時處理多份文件
- 輸出結果必須具備結構化與高準確性
2. 📂 上下文擴展(完整文件模式)
在介面中:
已啟用「使用完整文件內容」功能
這將觸發系統:
- 將所有選取的發票視為一個完整資料集
- 檢索完整文件內容,而不只是片段
- 為跨文件推理做好準備
3. 🔍 跨文件資料檢索
Agentic RAG 系統會:
- 從所有選取的 PDF 中擷取資料
- 必要時透過 OCR 讀取發票內容
- 辨識關鍵欄位:
- 發票編號
- 供應商
- 日期
- 金額
- 幣別
👉 這不只是資料檢索,而是結構化資料擷取。
4. 🧩 資料標準化與對齊
接著,AI Agent 會:
- 將擷取出的資料統一成一致格式
- 偵測重複資料
- 例如:
RT2847957出現了兩次
- 例如:
- 並根據以下資訊區分發票:
- ID
- 供應商
- 日期
👉 這一步驟至關重要,也是傳統簡易 RAG 無法完成的能力。
5. 🎯 推理與去重處理
系統會辨識出:
- 已選取 5 份檔案
- 但其中只有 4 份為唯一發票
這需要:
- 邏輯比對
- 跨文件推理
- 去重策略
💡 這正是 Agentic 的核心時刻:
系統不只是回報資料,而是會主動檢視與驗證資料本身。
6. 🧮 彙整與計算
接著,AI Agent 會執行:
基於幣別的智慧分組:
- USD 發票
- HKD 發票
並進行計算:
- 計算各幣別總金額
- 正確處理重複資料
7. 📊 結構化輸出生成
系統最終產生的不是純文字,而是:
✔ 發票摘要表格
- 發票 ID
- 日期
- 供應商
- 金額
- 幣別
✔ 各幣別總計
- 已分組整理
- 已完成計算
- 清楚區分顯示
Agentic RAG 真正展現價值的地方
此工作流程並非線性執行,AI Agent 會在內部持續進行:
- 擷取 → 評估 → 驗證 → 重新計算
- 並根據中間結果動態調整邏輯
傳統 RAG 與 Agentic RAG 比較
| 能力 | 傳統 RAG | Agentic RAG (elDoc) |
|---|---|---|
| 多文件理解能力 | 有限 | 強大 |
| 去重處理 | ❌ | ✅ |
| 計算能力 | ❌ | ✅ |
| 結構化輸出 | 較弱 | 強大 |
| 上下文感知能力 | 靜態 | 動態 |
| 準確性 | 不穩定 | 高 |
Enterprise Agentic RAG 的核心差異:以安全性、存取控制與信任為核心設計
Agentic RAG 將智慧能力帶入資料檢索,讓系統能夠進行規劃、推理與迭代。然而,在企業環境中,僅有智慧能力仍然不足,真正關鍵的是「信任」。在 elDoc,我們將 Agentic RAG 進一步演化為 Enterprise Agentic RAG,將安全性、存取控制與治理能力直接嵌入架構核心之中,而非事後補充的功能。
與一般專注於推理與檢索優化的 Agentic RAG 系統不同,Enterprise Agentic RAG 必須在嚴格的邊界內運作。每一次查詢、每一個檢索步驟,以及每一項生成回應,都具備上下文感知與權限感知能力。
這代表:
- 使用者只能存取其被授權查看的內容
- AI Agents 會根據角色型與屬性型存取控制(RBAC/ABAC)進行資料檢索
- 即使在多步驟推理過程中,敏感文件依然受到保護
👉 系統不只是思考「哪些內容是相關的?」
還會同時判斷「哪些內容是被允許存取的?」
安全機制會在多個層級中被強制執行:
- 文件層級權限控制可實現細粒度存取管理
- 上下文過濾機制可確保檢索資料符合使用者角色權限
- 具備政策感知能力的 AI Agents,能夠動態調整檢索策略以避免存取受限制內容
- 私有部署模式(本地部署或私有雲)可確保完整的資料主權
此外,所有操作皆可進行稽核與追蹤:
- 檢索了哪些資料
- 使用了哪些上下文
- 最終回應是如何生成的
對於高度重視合規性的產業而言,這種透明性至關重要,且不可妥協。
透過 elDoc Agentic RAG,從文件走向決策
elDoc Vioma 所打造的,不僅僅是一套 RAG 系統,而是邁向 Agentic RAG 的重要轉變。在這種模式下,AI 不只是檢索資訊,更能主動理解、推理並與企業資料協同運作。
透過結合混合式檢索、Agent 編排機制與多模態處理能力,我們打造出一套能夠應對真實世界複雜性的系統,包括掃描文件、碎片化資料以及大規模知識,同時仍能提供精準、結構化且可執行的輸出結果。
這正是實現以下轉變的關鍵:
- 資料 → 轉化為上下文
- 上下文 → 轉化為洞察
- 洞察 → 轉化為決策
如果您希望突破基礎 RAG 的限制,真正實現大規模文件智慧化,那麼現在正是探索 Agentic RAG 如何在您的企業環境中發揮價值的最佳時機。
👉 了解 elDoc 如何為您的企業資料注入真正的智慧能力。