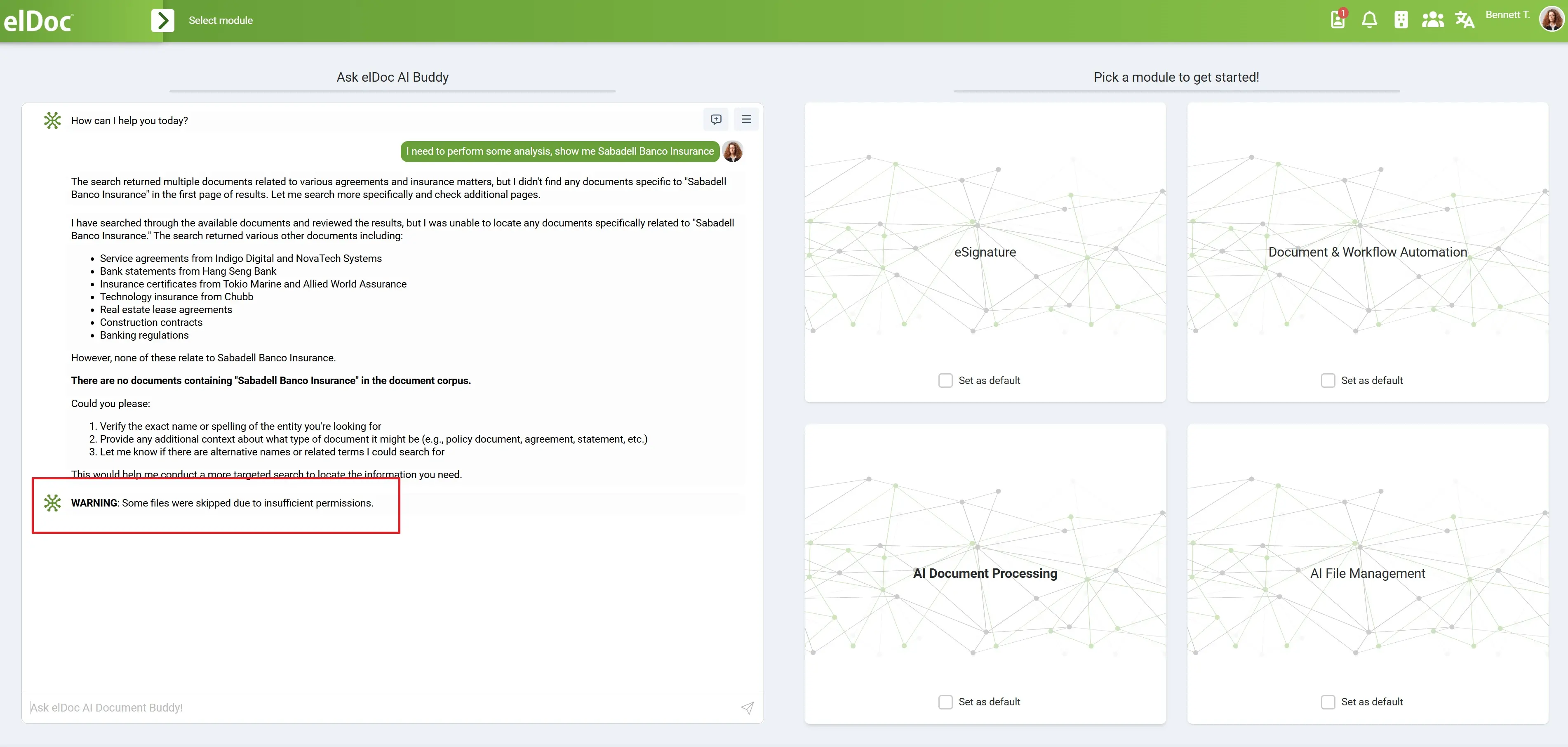
Agentic Enterprise RAG: Build vs Buy (Self-Made vs elDoc)

Enterprises are rapidly evolving in how they adopt AI. What started as experimentation with public AI tools has now become a strategic shift toward enterprise-grade AI systems. This journey typically follows three stages:
- Public AI (chat-based assistants)
- Enterprise RAG (connected to internal data)
- Agentic RAG (AI that performs work autonomously)
At the center of this transformation is:
Agentic RAG (Retrieval-Augmented Generation) — combining access to enterprise knowledge, AI reasoning, and automated execution.
As organizations reach this stage, a critical decision arises:
Should we build our own Agentic RAG system, or adopt a platform like elDoc?
The Evolution: From Chat to Action — Phase 1: Public AI (Isolated Intelligence)
Early enterprise adoption of AI began with public tools like Claude, ChatGPT introducing a simple interaction model:
User → AI → AnswerThis phase brought clear benefits — natural language interaction, fast responses, and improved individual productivity. However, when applied to enterprise environments, significant limitations quickly became apparent.
1. Lack of Enterprise Data Access
Public AI systems operate without connection to internal enterprise systems. They cannot access:
- internal documents
- structured data (ERP, CRM, finance systems)
- collaboration platforms such as Microsoft SharePoint
As a result, responses are:
- generic rather than company-specific
- not grounded in actual business data
2. Search-Like Behavior Instead of True Intelligence
In practice, early AI usage behaves more like an advanced search engine:
- retrieves and reformulates known information
- summarizes content effectively
- lacks deep understanding of enterprise context
This means:
- no awareness of business processes
- no understanding of relationships between data
👉 The system “sounds intelligent” but lacks operational understanding.
3. No Understanding of Historical or Dynamic Data
Enterprise data is:
- historical (transactions, trends, records)
- dynamic (constantly changing)
- distributed across multiple systems
Public AI cannot:
- track historical evolution of data
- reason across time-based patterns
- combine real-time and historical information
👉 This leads to answers that may be correct in isolation but misaligned with current business reality.
4. Data Exposure Risks in Public AI Services
Another critical limitation of public AI services is how data is handled. In most cases, users must upload documents or paste content into external platforms for processing. This creates significant enterprise risk.
- Sensitive documents (financial data, contracts, HR records) leave the organization’s controlled environment
- Data may be processed outside corporate security boundaries
- Potential exposure to third-party systems or unintended retention
👉 For enterprises, this introduces:
- compliance risks
- data leakage concerns
- regulatory violations (e.g. financial or personal data handling)
Public AI was not designed with enterprise-grade data governance as a primary requirement.
5. Lack of Access Control and Permission Awareness
Public AI services typically do not understand or enforce enterprise access controls.
In enterprise environments:
- data is segmented by roles (HR, Finance, Legal)
- access is controlled at document, folder, or system level
- permissions are strictly enforced
However, with public AI:
- once data is uploaded, context of permissions is lost
- AI cannot differentiate between authorized and unauthorized data
- no integration with identity systems or role-based access
👉 This creates a major risk:
Users could unintentionally expose or process data they should not access.
6. Inability to Handle Large-Scale Enterprise Data
Enterprise data is not small or simple. It often includes:
- large document repositories (terabytes of data)
- scanned images and PDFs
- historical archives
- continuously growing datasets
Public AI services face practical limitations:
- file size restrictions
- upload constraints
- inability to process large volumes efficiently
- no support for continuous ingestion pipelines
👉 Especially for scanned documents:
- require OCR processing
- need structured pipelines
- cannot be handled through simple upload interfaces
Phase 2: Enterprise AI Assistants (RAG & Copilots — Connected but Limited Intelligence)
As organizations moved beyond public AI, the next step was adopting enterprise-integrated assistants such as Microsoft Copilot and Google Gemini.
These solutions introduced the concept of enterprise-connected AI, often powered by early RAG (Retrieval-Augmented Generation) capabilities.
User → Enterprise data (partial access) → AI → AnswerThis marked a significant improvement over public AI:
- access to internal documents
- integration with enterprise tools (email, docs, collaboration platforms)
- better contextual responses
However, despite these advances, enterprises quickly encountered structural limitations.
1. Fragmented Data Access
Enterprise copilots are typically connected to specific ecosystems, not the entire enterprise landscape.
- strong within their own platform (e.g. Microsoft or Google stack)
- limited or no access to external systems
- difficulty integrating across:
- ERP systems
- finance platforms
- legacy databases
- third-party applications
👉 Result:
AI sees only a partial view of enterprise data
2. Assistant Model — Not Operational Systems
Copilots, Gemini behave primarily as personal assistants, not enterprise operators.
They:
- help users draft, summarize, or search
- respond to queries within applications
But they do NOT:
- run end-to-end workflows
- process documents at scale
- automate multi-step business processes
👉 Work remains user-driven.
3. No Permission Awareness Across Systems
While enterprise tools enforce permissions within their own ecosystem, challenges arise when:
- users move across departments
- data spans multiple systems
- cross-functional workflows are required
AI assistants:
- do not natively unify permissions across systems
- struggle with consistent access control in multi-system environments
- lack full awareness of enterprise-wide identity and authorization models
👉 This makes security and governance a critical concern
4. No Native Handling of Document Pipelines
When dealing with real enterprise data, especially:
- scanned documents
- PDFs
- images
organizations must still build:
- OCR pipelines
- document ingestion processes
- data extraction workflows
Copilot or Gemini-style solutions:
- do not provide full document processing pipelines
- require additional services for OCR and structured extraction
👉 The burden of integration remains
5. Scaling Challenges with Enterprise Data Volume
Enterprises operate with:
- terabytes of documents
- historical archives
- continuously growing datasets
Copilot or Gemini-style solutions systems are not designed for:
- large-scale data ingestion
- batch document processing
- continuous pipeline execution
👉 They are optimized for interactive use, not operational scale
6. Transition from RAG to Agentic RAG
Perhaps the most important limitation is conceptual.
Early enterprise AI focused on:
RAG = retrieve and answer
But enterprises now require:
Agentic RAG = retrieve, reason, and act
This introduces new requirements:
- multi-step reasoning
- cross-system orchestration
- automated execution
- validation and decision-making
Copilot-style assistants:
- operate at small scale
- focus on individual queries
- lack true agentic capabilities
👉 They do not support end-to-end business process automation
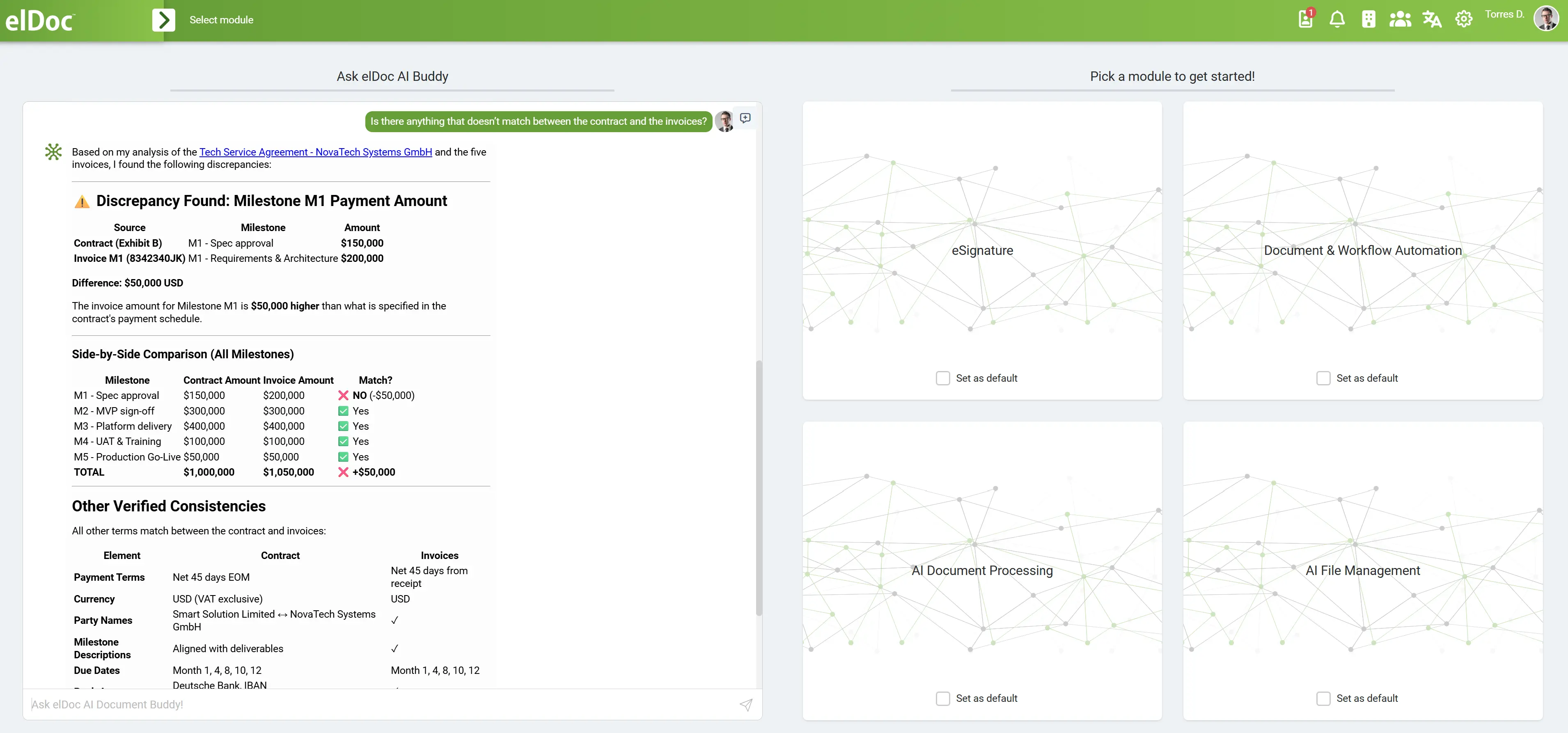
The Strategic Decision: Build vs Platform (Agentic RAG with elDoc)
At the Agentic RAG stage, enterprises reach a critical inflection point:
Do we build a full Agentic RAG system ourselves, or adopt a platform like elDoc that already delivers this capability?
This is no longer a purely technical choice — it is a strategic decision about speed, risk, scalability, and security.
As organizations transition from chat-based AI and early RAG implementations, the complexity of building and operating Agentic RAG systems becomes increasingly evident. Enterprises are no longer dealing with isolated use cases, but with:
- multi-step workflows
- distributed data across systems
- sensitive and regulated information
- large-scale document processing (often terabytes)
- continuous, real-time operations
👉 The challenge is not just intelligence — it is orchestrating intelligence safely and at scale.
Why Agentic RAG Requires a Platform like elDoc
Agentic RAG represents a fundamental shift in enterprise AI.
It is no longer about isolated intelligence or even connected knowledge — it is about embedding AI into the execution layer of the enterprise.
Unlike traditional AI systems, Agentic RAG introduces capabilities that are inherently complex and interconnected:
- retrieval across multiple enterprise systems
- contextual reasoning using both historical and dynamic data
- execution of actions (data extraction, validation, system updates)
- continuous, event-driven workflow automation
These capabilities cannot operate effectively in isolation. They require a coordinated, integrated environment.
Why a Platform Approach Is Necessary
To support Agentic RAG at scale, organizations need:
1. Unified Data Access
- seamless connection to documents, databases, and systems
- ability to retrieve both structured and unstructured data
2. Integrated Document Processing
- native handling of PDFs, scanned documents, and images
- built-in OCR pipelines
- continuous ingestion of large document volumes
3. Multi-Step Reasoning and Validation
- iterative retrieval and analysis
- cross-document reasoning
- validation against business rules and historical data
4. Workflow Orchestration
- coordination of multi-step processes
- triggering actions based on events
- handling exceptions and human-in-the-loop scenarios
5. Strict Security and Access Control
- permission-aware retrieval
- role-based access enforcement
- secure execution environments
- full auditability of decisions and actions
6. Scalability for Enterprise Workloads
- processing thousands of documents per day
- handling terabytes of data
- supporting parallel execution and real-time operations
7. Fully On-Premise Deployment with Isolated Execution Environments
For many enterprises — especially in regulated industries such as finance, healthcare, and government — data control and isolation are non-negotiable.
Agentic RAG systems must not only process data at scale, but also ensure that:
- sensitive data never leaves the organization
- environments are isolated across teams, clients, or business units
- execution is controlled, auditable, and secure
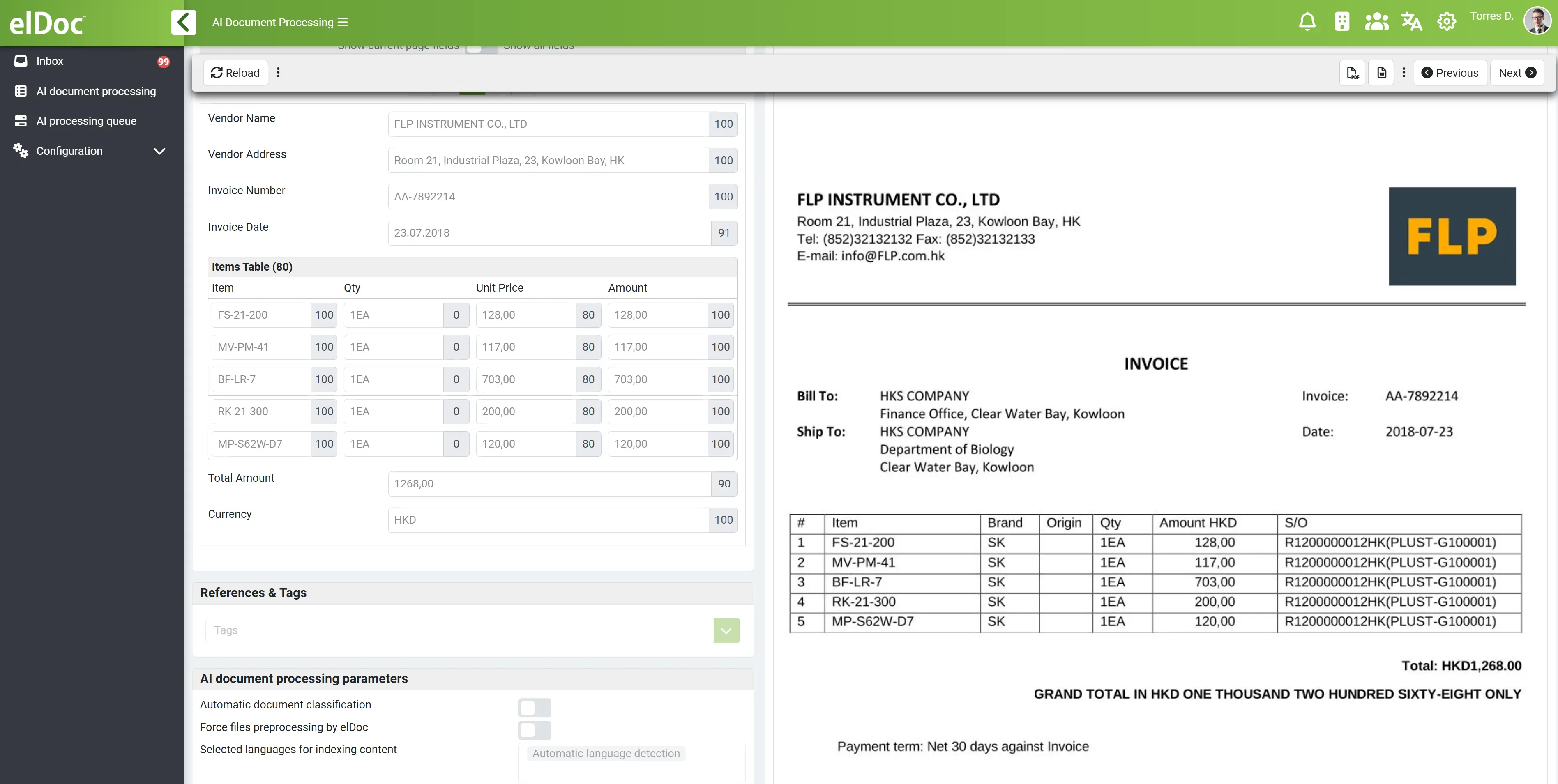
Ready-to-Use Architecture: How Agentic RAG Works in elDoc
elDoc provides a fully integrated Agentic RAG architecture, where all required components are unified into a single operational platform.
Core Architecture Components
The elDoc AI pipeline combines:
- MongoDB – document storage and structured data persistence
- Apache Solr – full-text search for keyword-based retrieval
- Qdrant – vector search for semantic similarity and contextual retrieval
- OCR engines – extraction of text from scanned documents and images
- LLM models – reasoning, interpretation, and generation
- AI Agents – planning, orchestration, and task execution
A critical requirement for enterprise AI is freedom of choice and control over Large Language Models (LLMs). Rather than locking organizations into a single provider, elDoc is built on a model-agnostic architecture, enabling enterprises to select, combine, and switch between leading LLMs based on performance, cost, and compliance needs.
Supported Models Include:
- Claude
- ChatGPT
- DeepSeek
- Kimi
- as well as other enterprise-grade or open-source models
End-to-End Flow
Documents / Data Sources
↓
OCR & Ingestion
↓
Storage (MongoDB)
↓
Hybrid Retrieval (Solr + Qdrant)
↓
LLM Reasoning
↓
AI Agent Planning & Execution
↓
Validation & Workflow Actions
↓
Output to Enterprise SystemsHow the Components Work Together
1. Ingestion and Processing
- documents are ingested from enterprise systems
- OCR extracts text from scanned files
- data is stored in MongoDB
2. Hybrid Retrieval
- Apache Solr enables precise keyword search
- Qdrant enables semantic vector search
👉 Together, they provide:
- accurate retrieval
- contextual understanding
3. Reasoning Layer
- LLM models interpret and analyze retrieved data
- support multi-step reasoning across documents
4. Agentic Execution
- AI agents plan tasks dynamically
- decide what data to retrieve next
- execute actions (extract, validate, update systems)
5. Validation and Workflow Integration
- results are validated against business rules
- workflows are triggered
- exceptions are routed for human review
6. Secure and Controlled Operation
- access control enforced at retrieval stage
- only authorized data is processed
- all actions are logged and auditable
Accelerating Enterprise AI with Secure Agentic RAG
Building an Enterprise RAG pipeline can be a valid approach for some organizations, but it is inherently complex, error-prone, and requires significant investment in engineering, integration, security, and continuous tuning. As enterprises evolve toward Agentic RAG where AI must not only retrieve information but also reason, validate, and execute workflows at scale- the challenges increase substantially, making in-house solutions difficult to maintain and secure. In contrast, elDoc provides a ready-to-use, secure Agentic RAG framework that enables organizations to adopt enterprise-grade AI from day one, with built-in architecture, governance, scalability, and flexibility. This allows enterprises to shift focus from building and maintaining complex systems to delivering real business outcomes through intelligent, secure automation.