Enterprise Agentic RAG as a Service: APIs for Document Intelligence and Chatbots

Organizations today require more than isolated AI tools. They need a secure, scalable, and fully managed AI ecosystem that enables them to build intelligent solutions such as virtual assistants and chatbots — grounded in their own document knowledge. This is exactly where elDoc comes in. elDoc delivers a fully compliant, enterprise-grade AI service architecture based on Retrieval-Augmented Generation (RAG) — allowing organizations to transform unstructured data into actionable intelligence, securely and efficiently.
1. Managed Document Processing API – The Foundation of Agentic RAG in elDoc
At the core of any successful Agentic RAG implementation is one critical capability: the ability to understand documents at scale and transform them into structured, usable knowledge. With elDoc, this capability is delivered as a fully managed API service, forming the first and most essential layer of its Agentic RAG architecture.
What the Service Does
elDoc provides a Managed Document Processing & Understanding API that ingests unstructured content — including:
- PDFs
- DOCX files
- Scanned documents
- Images and mixed-format archives
and converts them into structured, machine-readable data ready for AI reasoning. This is not a standalone OCR tool – it is an intelligent preprocessing layer that prepares enterprise knowledge for downstream retrieval, analysis, and automation.
How Agentic RAG Works in elDoc
What makes elDoc truly powerful is how this document understanding layer integrates into a multi-component Agentic RAG architecture. Instead of isolated tools, elDoc orchestrates a full AI pipeline, where each component plays a specific role:
The elDoc AI Pipeline
- MongoDB – stores original documents and structured data
- Apache Solr – enables fast and precise full-text search
- Qdrant – powers vector similarity search for semantic retrieval
- OCR Engines – extract and digitize document content
- LLM Models – perform reasoning, summarization, and response generation
- AI Agents – plan, orchestrate, and execute multi-step tasks
How It All Comes Together
- Ingestion & Understanding
Documents are processed through the Managed Document API (OCR + LLM + extraction) - Structuring & Storage
Data is stored in MongoDB and indexed for search in Apache Solr - Vectorization
Content is converted into embeddings and stored in Qdrant for semantic retrieval - Retrieval
When a user asks a question, elDoc retrieves the most relevant information using:- keyword search (Solr)
- semantic similarity (Qdrant)
- Reasoning & Generation
LLMs generate accurate, context-aware responses grounded in retrieved data - Agentic Execution
AI Agents orchestrate multi-step workflows — combining retrieval, validation, and actions
From Processing to Action
This architecture enables a critical shift:
- From raw documents → structured data
- From structured data → searchable knowledge
- From searchable knowledge → intelligent answers
Why This Matters
Because in enterprise environments, the challenge is not just accessing documents — it is understanding, connecting, and acting on them securely.
With elDoc’s API-driven, modular architecture, organizations can:
- Build AI assistants grounded in their own data
- Automate complex, document-heavy workflows
- Ensure accuracy, traceability, and compliance at every step
The Key Advantage — Security by Architecture, Not as an Add-On
Unlike fragmented AI tools that introduce risk through disconnected components, elDoc is designed with security embedded at every layer of the architecture. This is not just a feature — it is the foundation of how the platform operates.
Enterprise-Grade Access Control and Governance
Security in elDoc goes far beyond API protection — it extends deep into data-level governance.
- Role-Based Access Control (RBAC) down to document and segment level
- Hierarchical permission models aligned with organizational structure
- Dynamic access reassignment when roles or users change
Most importantly:
👉 AI responses are always constrained by user permissions
If a user does not have access to a document, the AI cannot retrieve or generate information from it.
2. Embedding Models & Vector Database Service
To enable fast and accurate retrieval, elDoc provides a managed vectorization and search layer — the core of any RAG architecture.
Key Capabilities
- API for generating high-dimensional embeddings from document segments
- Fully managed vector database with high availability and low latency
- Approximate Nearest Neighbor (ANN) search for real-time similarity matching
- Secure storage and management of millions of knowledge vectors
What This Enables
When a user asks a question, elDoc instantly retrieves the most relevant fragments of knowledge from across the organization’s documents — in milliseconds. This ensures that AI responses are always grounded in real, authorized data.
3. Large Language Model (LLM) API for Reasoning & Generation
At the core of intelligent interaction is the ability to reason, understand, and generate human-like responses. elDoc provides API access to state-of-the-art Large Language Models (LLMs) — fully integrated into the RAG pipeline.
Key Capabilities
- Context-aware response generation based strictly on retrieved knowledge
- Native support for Retrieval-Augmented Generation (RAG)
- Mechanisms to minimize hallucinations and ensure factual accuracy
- Support for multi-step reasoning and complex queries
- Conversation management with chat history awareness
What This Enables
Users can interact with enterprise knowledge through natural language, receiving:
- Accurate answers
- Summaries
- Explanations
- Context-driven insights
All responses are fully aligned with the organization’s own data — not generic AI outputs.
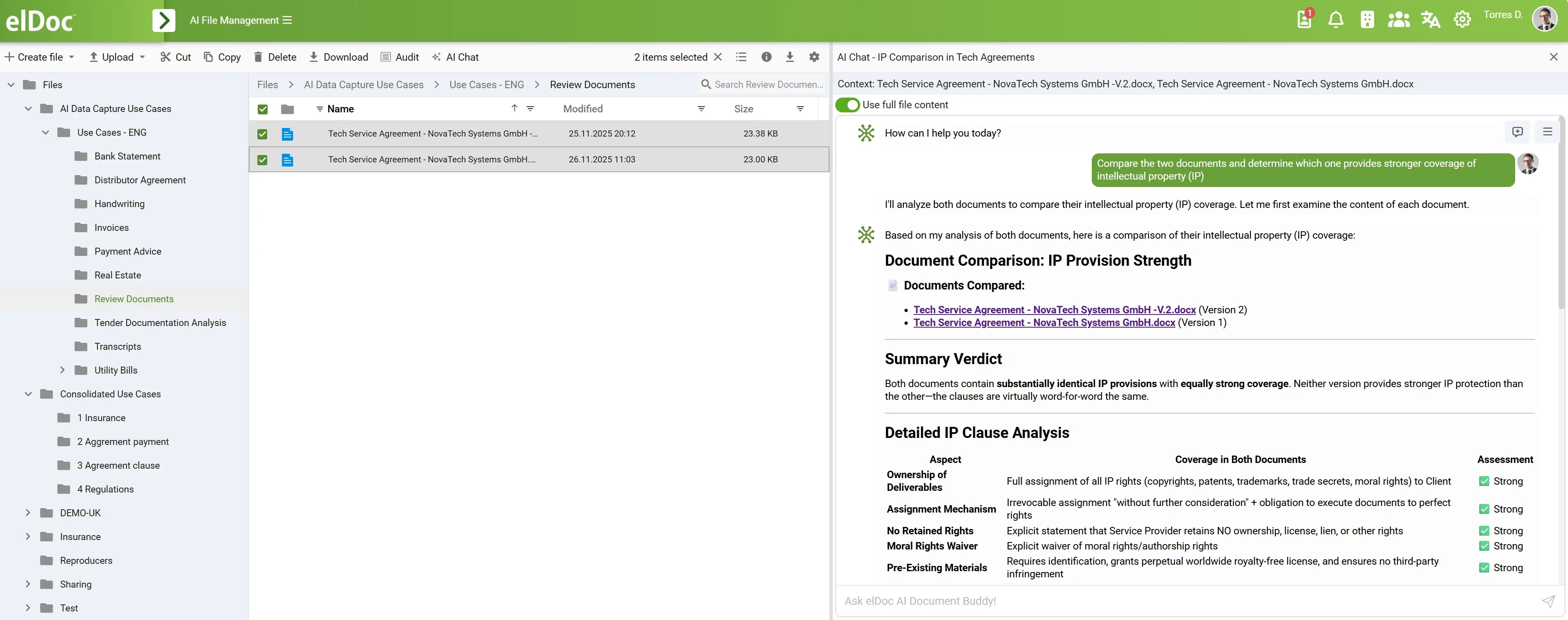
The Key Advantage — Build vs. Adopt: Accelerating Enterprise AI with elDoc
Many organizations recognize the value of Agentic RAG and consider building their own internal platform. On paper, this may seem like the most flexible approach. In reality, it is often the most complex, costly, and risky path.
The Hidden Cost of Building Your Own Agentic RAG Platform
Creating an enterprise-grade AI platform is not just about integrating a model or a vector database.
It requires building and maintaining an entire ecosystem:
- Document processing pipelines (OCR, parsing, structuring)
- Embedding models and vector databases
- Search infrastructure (keyword + semantic)
- LLM orchestration and prompt engineering
- Multi-step reasoning and agent frameworks
- API management and integration layers
- Security, governance, and compliance controls
- Monitoring, logging, and audit systems
- Infrastructure for scalability, availability, and disaster recovery
This demands:
- Significant engineering resources
- Continuous maintenance and upgrades
- Deep AI and infrastructure expertise
- Long time-to-market (often 12–24 months)
Most importantly — this is not the core business for the majority of organizations.
The Alternative — Start from Day One with elDoc
With elDoc, organizations can bypass this complexity entirely. Instead of building infrastructure, they can immediately consume a fully managed, enterprise-ready AI platform via APIs.
This means:
- No need to design architecture from scratch
- No need to integrate multiple vendors and tools
- No need to solve security and compliance independently
Everything is already:
- Pre-integrated
- Secure by design
- Scalable and production-ready