Agentic RAG для бізнесу: створювати чи обрати платформу (власне рішення vs elDoc)

Компанії стрімко змінюють підходи до впровадження штучного інтелекту. Те, що починалося як експерименти з публічними AI-інструментами, сьогодні перетворилося на стратегічний перехід до AI-систем корпоративного рівня. Зазвичай цей шлях проходить у три етапи:
- Публічний AI (чат-орієнтовані асистенти)
- Корпоративний RAG (підключений до внутрішніх даних)
- Agentic RAG (AI, що виконує завдання автономно)
У центрі цієї трансформації:
Agentic RAG (Retrieval-Augmented Generation), що поєднує доступ до корпоративних знань, аналітичні можливості AI та автоматизоване виконання завдань.
Коли організації досягають цього етапу, постає ключове питання:
Чи варто створювати власну систему Agentic RAG, чи доцільніше обрати готову платформу, на зразок elDoc?
Еволюція: від чату до дії. Фаза 1: Публічний AI (ізольований інтелект)
Початкове впровадження AI в компаніях розпочалося з використання публічних інструментів, таких як Claude і ChatGPT, які запропонували просту модель взаємодії:
User → AI → AnswerЦей етап приніс очевидні переваги, зокрема взаємодію природною мовою, швидкі відповіді та підвищення індивідуальної продуктивності. Водночас під час застосування в корпоративному середовищі швидко проявилися суттєві обмеження.
1. Відсутність доступу до корпоративних даних
Публічні AI-системи працюють без підключення до внутрішніх корпоративних систем. Вони не мають доступу до:
- внутрішніх документів
- структурованих даних (ERP, CRM, фінансові системи)
- платформ для спільної роботи, таких як Microsoft SharePoint
У результаті відповіді:
- є узагальненими, а не адаптованими до конкретної компанії
- не підкріплені реальними бізнес-даними
2. Пошукова поведінка замість справжнього інтелекту
На практиці раннє використання AI більше нагадує удосконалену пошукову систему:
- знаходить і перефразовує відому інформацію
- ефективно резюмує зміст
- не має глибокого розуміння корпоративного контексту
Це означає:
- відсутність розуміння бізнес-процесів
- відсутність розуміння взаємозв’язків між даними
👉 Система «звучить розумно», але позбавлена операційного розуміння.
3. Відсутність розуміння історичних і динамічних даних
Корпоративні дані бувають:
- історичними (транзакції, тренди, записи)
- динамічними (постійно змінюються)
- розподіленими між кількома системами
Публічний AI не здатний:
- відстежувати історичну еволюцію даних
- аналізувати закономірності, що змінюються з часом
- поєднувати дані в реальному часі з історичними
👉 Це призводить до відповідей, які можуть бути правильними самі по собі, але не відповідають поточній бізнес-реальності.
4. Ризики витоку даних у публічних AI-сервісах
Ще одним критичним обмеженням публічних AI-сервісів є підхід до обробки даних. Здебільшого користувачі змушені завантажувати документи або вставляти вміст у зовнішні платформи для опрацювання. Це створює значні корпоративні ризики.
- Конфіденційні документи (фінансові дані, контракти, HR-записи) виходять за межі контрольованого середовища організації
- Дані можуть оброблятися поза корпоративним периметром безпеки
- Існує ризик потрапляння даних до сторонніх систем або ненавмисного збереження
👉 Для компаній це створює:
- ризики невідповідності нормативним вимогам
- загрозу витоку даних
- порушення регуляторних норм (наприклад, щодо обробки фінансових або персональних даних)
Публічні AI-рішення не були спроєктовані з урахуванням корпоративного рівня управління даними як першочергової вимоги.
5. Відсутність контролю доступу та врахування прав користувачів
Публічні AI-сервіси зазвичай не враховують і не забезпечують корпоративні механізми контролю доступу.
У корпоративному середовищі:
- дані розмежовані за ролями (HR, фінанси, юридичний відділ)
- доступ контролюється на рівні документів, папок або систем
- права доступу суворо контролюються
Натомість у публічних AI-сервісах:
- після завантаження даних контекст прав доступу втрачається
- AI не може відрізнити авторизовані дані від неавторизованих
- відсутня інтеграція із системами ідентифікації або рольовим доступом
👉 Це створює суттєвий ризик:
користувачі можуть ненавмисно розкрити або обробити дані, до яких не повинні мати доступу.
6. Неспроможність обробляти великі масиви корпоративних даних
Корпоративні дані не є малими чи простими. Вони часто охоплюють:
- великі сховища документів (терабайти даних)
- скановані зображення та PDF-файли
- історичні архіви
- набори даних, що постійно поповнюються
Публічні AI-сервіси стикаються з практичними обмеженнями:
- обмеження на розмір файлів
- ліміти завантаження
- неможливість ефективно обробляти великі обсяги даних
- відсутність підтримки безперервних конвеєрів завантаження даних
👉 Особливо це стосується сканованих документів:
- вони потребують OCR-обробки
- їм необхідні структуровані конвеєри
- їх неможливо опрацювати через прості інтерфейси завантаження
Фаза 2: Корпоративні AI-асистенти (RAG і копілоти – інтегровані, але з обмеженими можливостями)
У міру того як організації виходили за межі публічного AI, наступним кроком стало впровадження корпоративно інтегрованих асистентів, таких як Microsoft Copilot і Google Gemini.
Ці рішення запровадили концепцію AI, підключеного до корпоративних даних, здебільшого на основі ранніх можливостей RAG (Retrieval-Augmented Generation).
User → Enterprise data (partial access) → AI → AnswerЦе стало значним кроком уперед порівняно з публічним AI:
- доступ до внутрішніх документів
- інтеграція з корпоративними інструментами (електронна пошта, документи, платформи для спільної роботи)
- більш контекстні відповіді
Однак, попри ці переваги, компанії швидко зіткнулися зі структурними обмеженнями.
1. Фрагментований доступ до даних
Корпоративні копілоти зазвичай підключені до окремих екосистем, а не до всієї IT-інфраструктури компанії.
- ефективні в межах власної платформи (наприклад, екосистеми Microsoft або Google)
- мають обмежений або відсутній доступ до зовнішніх систем
- складно інтегруються з:
- ERP-системами
- фінансовими платформами
- застарілими базами даних
- сторонніми застосунками
👉 Як результат:
AI отримує лише часткове уявлення про корпоративні дані
2. Модель асистента, а не операційна система
Copilot і Gemini переважно працюють як персональні асистенти, а не як інструменти для виконання операційних процесів у компанії.
Вони:
- допомагають створювати тексти, узагальнювати інформацію та здійснювати пошук
- відповідають на запити в межах застосунків
Проте вони НЕ можуть:
- виконувати комплексні робочі процеси
- обробляти великі обсяги документів
- автоматизувати багатоетапні бізнес-процеси
👉 Виконання завдань і надалі залежить від користувача.
3. Відсутність узгодженого контролю доступу між системами
Хоча корпоративні інструменти забезпечують контроль доступу в межах власних екосистем, проблеми виникають, коли:
- користувачі переходять з одного відділу в інший
- дані розподілені між кількома системами
- необхідні міжфункціональні процеси
AI-асистенти:
- не забезпечують вбудованої уніфікації прав доступу між системами
- мають труднощі із забезпеченням послідовного контролю доступу в мультисистемних середовищах
- не мають повного уявлення про загальнокорпоративні моделі ідентифікації та авторизації
👉 У результаті питання безпеки та управління стають критично важливими
4. Відсутність вбудованої підтримки конвеєрів обробки документів
Під час роботи з реальними корпоративними даними, особливо:
- сканованими документами
- PDF-файлами
- зображеннями
організаціям усе ще доводиться створювати:
- OCR-конвеєри
- процеси завантаження документів
- процеси витягування даних
Рішення на кшталт Copilot або Gemini:
- не забезпечують повноцінні конвеєри обробки документів
- потребують додаткових сервісів для OCR і структурованого витягування даних
👉 Тягар інтеграції залишається на організації.
5. Труднощі масштабування з огляду на обсяг корпоративних даних
Підприємства працюють із:
- терабайтами документів
- історичними архівами
- наборами даних, що постійно зростають
Рішення на кшталт Copilot або Gemini не призначені для:
- масштабного завантаження даних
- пакетної обробки документів
- безперервного виконання конвеєрів
👉 Вони оптимізовані для інтерактивного використання, а не для операційного масштабу
6. Перехід від RAG до Agentic RAG
Мабуть, найважливіше обмеження є концептуальним.
Ранні корпоративні AI-рішення були зосереджені на:
RAG = знайти і відповісти
Проте зараз підприємства потребують:
Agentic RAG = знайти, проаналізувати та діяти
Це висуває нові вимоги:
- багатоетапного аналізу
- оркестрації між системами
- автоматизованого виконання
- перевірки та прийняття рішень
Помічники на кшталт Copilot:
- працюють у невеликому масштабі
- зосереджені на окремих запитах
- не мають повноцінних агентних можливостей
👉 Вони не підтримують комплексну автоматизацію бізнес-процесів
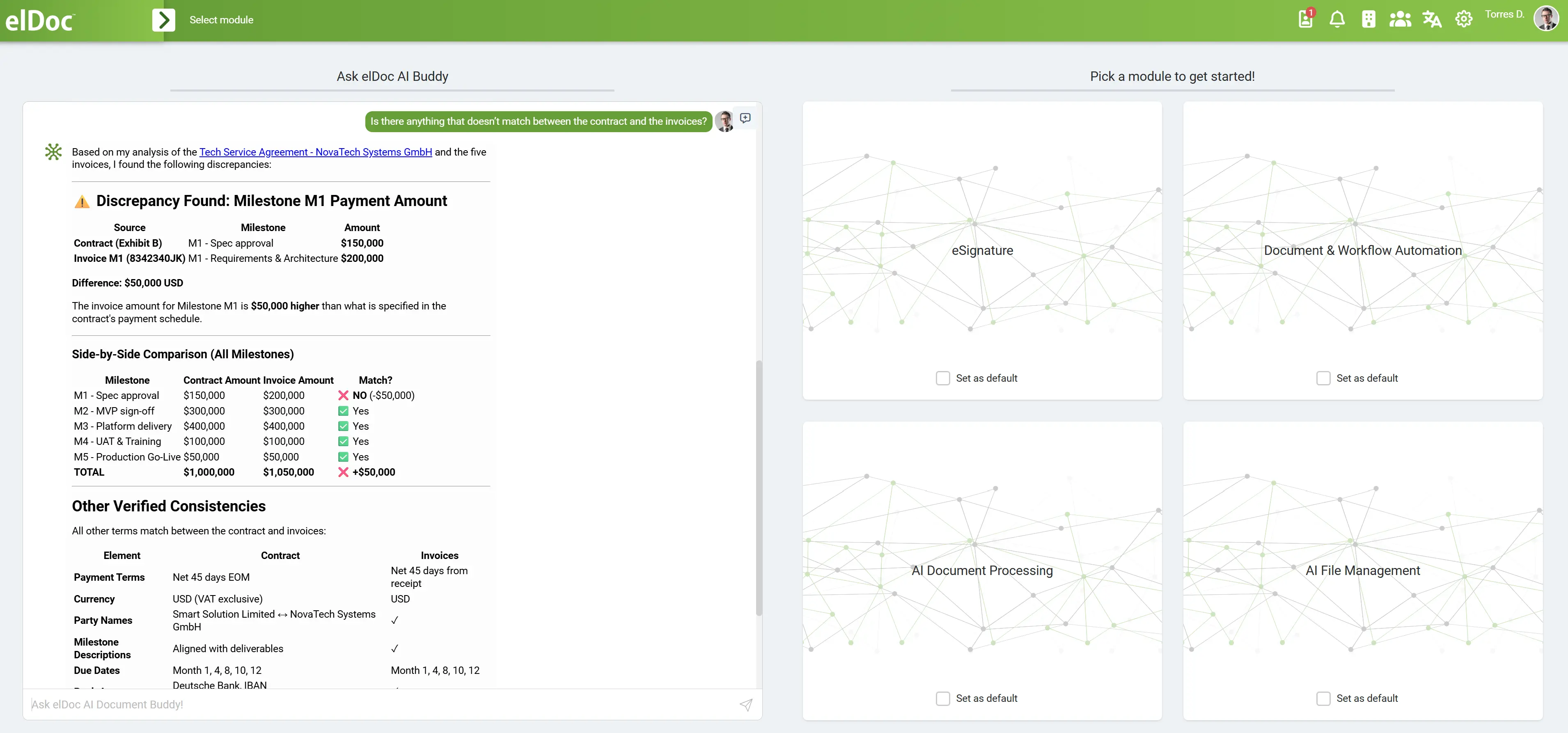
Стратегічний вибір: власна розробка чи готова платформа (Agentic RAG з elDoc)
На етапі Agentic RAG компанії досягають критичної точки вибору:
Чи створювати повноцінну систему Agentic RAG самостійно, чи обрати платформу на кшталт elDoc, яка вже забезпечує ці можливості?
Це вже не суто технічний вибір, а стратегічне рішення, що стосується швидкості, ризиків, масштабованості та безпеки.
У міру того як організації переходять від чат-орієнтованого AI та ранніх реалізацій RAG, складність побудови й експлуатації систем Agentic RAG стає дедалі очевиднішою. Компанії вже мають справу не з окремими сценаріями використання, а з:
- багатоетапними робочими процесами
- даними, розподіленими між різними системами
- конфіденційною та регульованою інформацією
- масштабною обробкою документів (нерідко терабайти)
- безперервними операціями в режимі реального часу
👉 Основний виклик полягає не лише в інтелекті, а в безпечній оркестрації цього інтелекту у великих масштабах.
Чому Agentic RAG потребує платформи на кшталт elDoc
Agentic RAG означає фундаментальну зміну в корпоративному AI.
Йдеться вже не про ізольований інтелект чи навіть підключені знання, а про інтеграцію AI безпосередньо в рівень виконання процесів у компанії.
На відміну від традиційних AI-систем, Agentic RAG впроваджує можливості, що є за своєю природою складними та взаємопов’язаними:
- отримання даних із різних корпоративних систем
- контекстний аналіз із використанням як історичних, так і динамічних даних
- виконання дій (витягування даних, перевірка, оновлення систем)
- безперервна, подієво-керована автоматизація робочих процесів
Ці можливості не можуть ефективно функціонувати окремо. Вони потребують скоординованого, інтегрованого середовища.
Чому необхідний платформний підхід
Щоб забезпечити роботу Agentic RAG у великих масштабах, організаціям необхідні:
1. Уніфікований доступ до даних
- безперебійне підключення до документів, баз даних і систем
- можливість отримувати як структуровані, так і неструктуровані дані
2. Інтегрована обробка документів
- вбудована обробка PDF-файлів, сканованих документів і зображень
- вбудовані конвеєри OCR
- безперервне завантаження великих обсягів документів
3. Багатоетапний аналіз і перевірка
- ітеративний пошук і аналіз даних
- міждокументний аналіз
- перевірка відповідно до бізнес-правил та історичних даних
4. Оркестрація процесів
- координація багатоетапних процесів
- ініціювання дій на основі подій
- обробка винятків і сценаріїв із залученням людини
5. Суворий захист і контроль доступу
- пошук з урахуванням прав доступу
- дотримання рольового доступу
- захищені середовища виконання
- повна простежуваність рішень і дій
6. Масштабованість для корпоративних навантажень
- обробка тисяч документів щодня
- робота з терабайтами даних
- підтримка паралельного виконання та операцій у реальному часі
7. Повністю локальне розгортання з ізольованими середовищами виконання
Для багатьох компаній, особливо в регульованих галузях, таких як фінанси, охорона здоров’я та державний сектор, контроль над даними і їх ізоляція є обов’язковими вимогами.
Системи Agentic RAG мають не лише обробляти дані у великих масштабах, а й гарантувати, що:
- конфіденційні дані ніколи не виходять за межі організації
- середовища ізольовані між командами, клієнтами або бізнес-підрозділами
- виконання є контрольованим, придатним до аудиту та безпечним
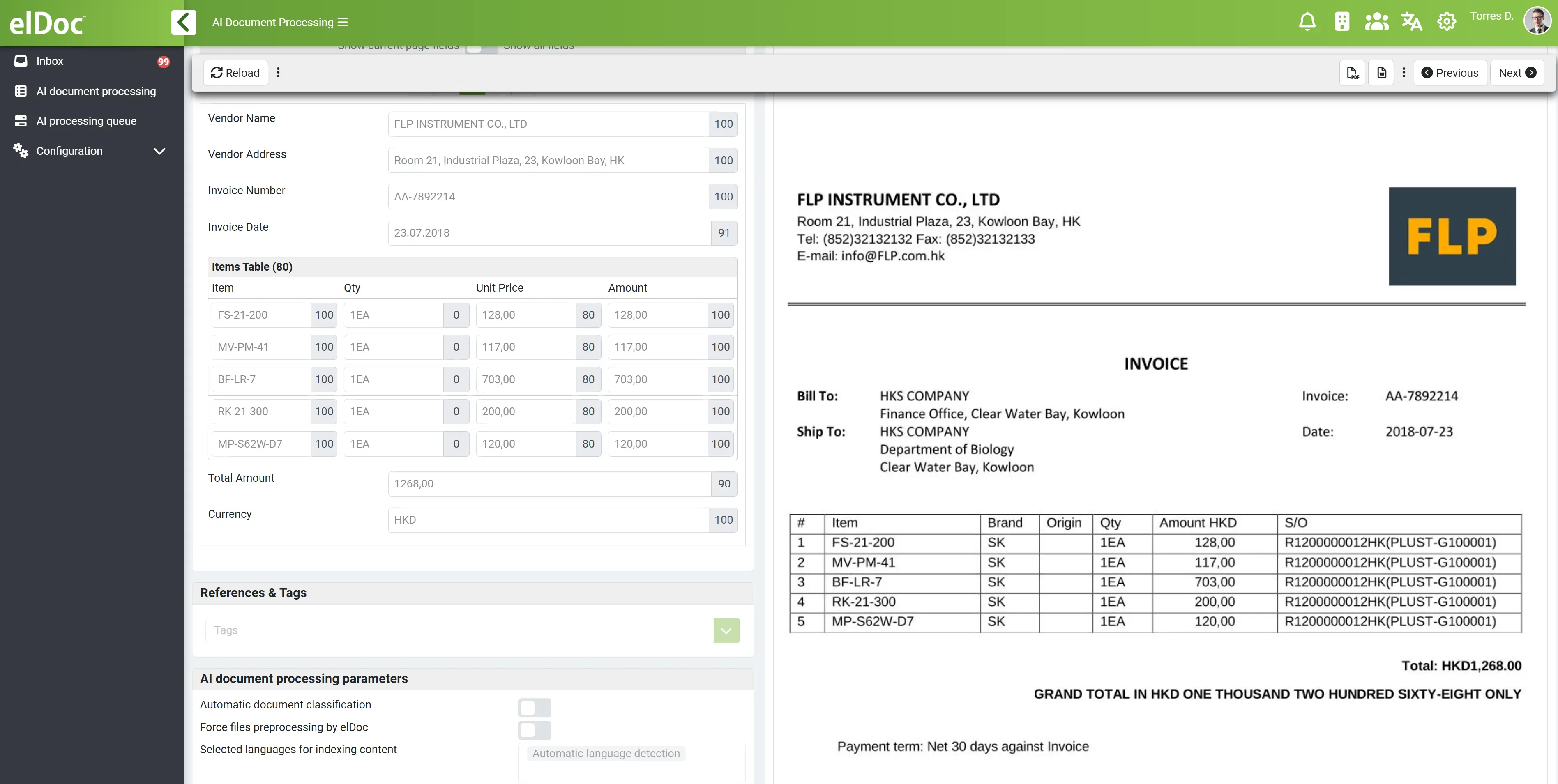
Готова до використання архітектура: як працює Agentic RAG в elDoc
elDoc надає повністю інтегровану архітектуру Agentic RAG, у якій усі необхідні компоненти об’єднані в єдину операційну платформу.
Ключові компоненти архітектури
AI-конвеєр elDoc поєднує:
- MongoDB – забезпечує зберігання документів і постійність структурованих даних
- Apache Solr – забезпечує повнотекстовий пошук за ключовими словами
- Qdrant – відповідає за векторний пошук для визначення семантичної подібності та контекстного пошуку
- Механізми OCR – здійснюють витягування тексту зі сканованих документів і зображень
- LLM-моделі – забезпечують аналіз, інтерпретацію та генерацію
- AI-агенти – виконують планування, оркестрацію та виконання завдань
Критично важливою вимогою до корпоративного AI є свобода вибору великих мовних моделей (LLM) і контроль над ними. Замість того щоб прив’язувати організації до одного постачальника, elDoc побудований на модельно-незалежній архітектурі, що дозволяє компаніям обирати, поєднувати та змінювати провідні LLM залежно від їхньої продуктивності, вартості та вимог до відповідності.
Підтримувані моделі:
- Claude
- ChatGPT
- DeepSeek
- Kimi
- а також інші моделі корпоративного рівня або з відкритим кодом
Наскрізний процес обробки даних
Documents / Data Sources
↓
OCR & Ingestion
↓
Storage (MongoDB)
↓
Hybrid Retrieval (Solr + Qdrant)
↓
LLM Reasoning
↓
AI Agent Planning & Execution
↓
Validation & Workflow Actions
↓
Output to Enterprise SystemsЯк компоненти працюють разом
1. Завантаження та обробка
- документи завантажуються з корпоративних систем
- OCR витягує текст зі сканованих файлів
- дані зберігаються в MongoDB
2. Гібридний пошук
- Apache Solr забезпечує точний пошук за ключовими словами
- Qdrant уможливлює семантичний векторний пошук
👉 Разом вони забезпечують:
- точний пошук інформації
- контекстне розуміння
3. Рівень аналізу
- LLM-моделі інтерпретують і аналізують отримані дані
- підтримують багатоетапний аналіз у розрізі кількох документів
4. Агентне виконання
- AI-агенти динамічно планують завдання
- визначають, які дані отримати наступними
- виконують дії (витягування даних, перевірка, оновлення систем)
5. Перевірка та інтеграція з робочими процесами
- результати перевіряються відповідно до бізнес-правил
- запускаються процеси
- винятки передаються на перевірку людиною
6. Захищена та контрольована робота
- контроль доступу застосовується на етапі отримання даних
- обробляються лише авторизовані дані
- усі дії реєструються та доступні для аудиту
Прискорення розвитку корпоративного AI за допомогою безпечного Agentic RAG
Побудова корпоративного конвеєра RAG може бути прийнятним підходом для деяких організацій, однак він є складним за своєю природою, схильним до помилок і потребує значних інвестицій в інженерію, інтеграцію, безпеку та постійне налаштування. У міру того як підприємства рухаються до агентного RAG, де AI має не лише знаходити інформацію, а й аналізувати, перевіряти та виконувати процеси у великих масштабах, складнощі суттєво зростають, через що власні рішення стає дедалі важче підтримувати та захищати. На противагу цьому, elDoc надає готову до використання, захищену платформу Agentic RAG, яка дозволяє організаціям впроваджувати AI корпоративного рівня з першого дня завдяки вбудованій архітектурі, механізмам управління, масштабованості та гнучкості. Це дає змогу підприємствам змістити фокус із побудови та підтримки складних систем на досягнення реальних бізнес-результатів завдяки інтелектуальній і захищеній автоматизації.