Agentic Enterprise RAG: Build vs Buy — własne rozwiązanie czy platforma elDoc?

Przedsiębiorstwa szybko zmieniają sposób wdrażania sztucznej inteligencji. To, co zaczęło się jako eksperymenty z publicznymi narzędziami AI, przekształciło się w strategiczne przejście w kierunku systemów AI klasy enterprise. Ten proces zazwyczaj obejmuje trzy etapy:
- Publiczna AI (asystenci czatowi)
- Enterprise RAG (połączony z danymi wewnętrznymi)
- Agentic RAG (AI, która autonomicznie wykonuje zadania)
W centrum tej transformacji znajduje się:
Agentic RAG (Retrieval-Augmented Generation), który łączy dostęp do wiedzy przedsiębiorstwa, wnioskowanie AI oraz zautomatyzowane wykonywanie zadań.
Gdy organizacje osiągają ten etap, pojawia się kluczowa decyzja:
Czy powinniśmy zbudować własny system Agentic RAG, czy wdrożyć platformę taką jak elDoc?
Ewolucja: od czatu do działania. Faza 1: publiczna AI (izolowana inteligencja)
Wczesne wdrożenia AI w przedsiębiorstwach rozpoczęły się od publicznych narzędzi, takich jak Claude czy ChatGPT, które wprowadziły prosty model interakcji:
User → AI → AnswerTen etap przyniósł wyraźne korzyści, takie jak interakcja w języku naturalnym, szybkie odpowiedzi oraz wzrost indywidualnej produktywności. Jednak w środowiskach przedsiębiorstw szybko ujawniły się istotne ograniczenia.
1. Brak dostępu do danych przedsiębiorstwa
Publiczne systemy AI działają bez połączenia z wewnętrznymi systemami przedsiębiorstwa. Nie mają dostępu do:
- dokumentów wewnętrznych
- danych ustrukturyzowanych (systemy ERP, CRM, systemy finansowe)
- platform współpracy, takich jak Microsoft SharePoint
W rezultacie odpowiedzi są:
- ogólne zamiast dopasowanych do firmy
- nieoparte na rzeczywistych danych biznesowych
2. Zachowanie przypominające wyszukiwarkę zamiast rzeczywistej inteligencji
W praktyce wczesne wykorzystanie AI działa bardziej jak zaawansowana wyszukiwarka:
- wyszukuje i przetwarza znane informacje
- skutecznie podsumowuje treści
- brakuje mu głębokiego zrozumienia kontekstu przedsiębiorstwa
Oznacza to:
- brak świadomości procesów biznesowych
- brak zrozumienia zależności między danymi
👉 System „brzmi inteligentnie”, ale brakuje mu zrozumienia operacyjnego.
3. Brak zrozumienia danych historycznych i dynamicznych
Dane przedsiębiorstwa są:
- historyczne (transakcje, trendy, rejestry)
- dynamiczne (stale się zmieniają)
- rozproszone w wielu systemach
Publiczna AI nie potrafi:
- śledzić historycznej ewolucji danych
- analizować wzorców w ujęciu czasowym
- łączyć informacji w czasie rzeczywistym z danymi historycznymi
👉 Prowadzi to do odpowiedzi, które mogą być poprawne w izolacji, ale nie są zgodne z aktualną rzeczywistością biznesową.
4. Ryzyko ujawnienia danych w publicznych usługach AI
Kolejnym istotnym ograniczeniem publicznych usług AI jest sposób przetwarzania danych. W większości przypadków użytkownicy muszą przesyłać dokumenty lub wklejać treści do zewnętrznych platform w celu ich przetworzenia. Stwarza to znaczące ryzyko dla przedsiębiorstwa.
- Wrażliwe dokumenty (dane finansowe, umowy, dokumentacja HR) opuszczają kontrolowane środowisko organizacji
- Dane mogą być przetwarzane poza granicami zabezpieczeń korporacyjnych
- Potencjalne narażenie na dostęp systemów zewnętrznych lub niezamierzone przechowywanie danych
👉 Dla przedsiębiorstw oznacza to:
- ryzyko niezgodności z regulacjami
- obawy związane z wyciekiem danych
- naruszenia przepisów (np. dotyczących przetwarzania danych finansowych lub osobowych)
Publiczna AI nie została zaprojektowana z myślą o zarządzaniu danymi na poziomie enterprise jako kluczowym wymaganiu.
5. Brak kontroli dostępu i świadomości uprawnień
Publiczne usługi AI zazwyczaj nie rozumieją ani nie egzekwują mechanizmów kontroli dostępu stosowanych w przedsiębiorstwach.
W środowiskach przedsiębiorstw:
- dane są segmentowane według ról (HR, finanse, dział prawny)
- dostęp jest kontrolowany na poziomie dokumentu, folderu lub systemu
- uprawnienia są ściśle egzekwowane
Jednak w przypadku publicznej AI:
- po przesłaniu danych kontekst uprawnień zostaje utracony
- AI nie potrafi odróżnić danych, do których dostęp jest dozwolony, od tych, do których nie powinno być dostępu
- brak integracji z systemami tożsamości i mechanizmami dostępu opartymi na rolach
👉 Stwarza to poważne ryzyko:
Użytkownicy mogą nieświadomie ujawniać lub przetwarzać dane, do których nie powinni mieć dostępu.
6. Brak możliwości obsługi danych przedsiębiorstwa na dużą skalę
Dane przedsiębiorstwa nie są niewielkie ani proste. Często obejmują:
- duże repozytoria dokumentów (terabajty danych)
- zeskanowane obrazy i pliki PDF
- archiwa historyczne
- stale rosnące zbiory danych
Publiczne usługi AI napotykają praktyczne ograniczenia:
- ograniczenia rozmiaru plików
- ograniczenia dotyczące przesyłania danych
- brak możliwości efektywnego przetwarzania dużych wolumenów danych
- brak wsparcia dla ciągłych pipeline’ów ingestii danych
👉 Szczególnie w przypadku dokumentów skanowanych:
- wymagają przetwarzania OCR
- wymagają ustrukturyzowanych pipeline’ów
- nie mogą być obsługiwane za pomocą prostych interfejsów przesyłania danych
Faza 2: asystenci AI dla przedsiębiorstw (RAG i copilots – połączeni, lecz o ograniczonej inteligencji)
W miarę jak organizacje wychodziły poza publiczną AI, kolejnym krokiem było wdrożenie asystentów zintegrowanych z systemami przedsiębiorstwa, takich jak Microsoft Copilot czy Google Gemini.
Rozwiązania te wprowadziły koncepcję AI połączonej z danymi przedsiębiorstwa, często opartej na wczesnych możliwościach RAG (Retrieval-Augmented Generation).
User → Enterprise data (partial access) → AI → AnswerStanowiło to istotne ulepszenie w porównaniu z publiczną AI:
- dostęp do dokumentów wewnętrznych
- integrację z narzędziami przedsiębiorstwa (e-mail, dokumenty, platformy współpracy)
- lepsze odpowiedzi kontekstowe
Jednak pomimo tych postępów przedsiębiorstwa szybko napotkały ograniczenia o charakterze strukturalnym.
1. Fragmentaryczny dostęp do danych
Copiloty w środowisku enterprise są zazwyczaj połączone z określonymi ekosystemami, a nie z całym krajobrazem systemów przedsiębiorstwa.
- działają bardzo dobrze w obrębie własnej platformy (np. ekosystem Microsoft lub Google)
- mają ograniczony lub zerowy dostęp do systemów zewnętrznych
- trudności z integracją pomiędzy:
- systemami ERP
- platformami finansowymi
- starszymi (legacy) bazami danych
- aplikacjami zewnętrznymi
👉 W rezultacie:
AI widzi jedynie fragmentaryczny obraz danych przedsiębiorstwa
2. Model asystenta, a nie systemy operacyjne
Copiloty i Gemini działają przede wszystkim jako osobiste asystenty, a nie jako systemy operacyjne przedsiębiorstwa.
Oferują:
- wsparcie w tworzeniu treści, podsumowywaniu i wyszukiwaniu informacji
- odpowiadanie na zapytania w obrębie aplikacji
Jednak NIE:
- realizują procesów end-to-end
- przetwarzają dokumentów na dużą skalę
- automatyzują wieloetapowych procesów biznesowych
👉 Praca nadal pozostaje po stronie użytkownika.
3. Brak świadomości uprawnień między systemami
Chociaż narzędzia enterprise egzekwują uprawnienia w obrębie własnych ekosystemów, problemy pojawiają się, gdy:
- użytkownicy działają między działami
- dane obejmują wiele systemów
- wymagane są procesy międzydziałowe
Asystenci AI:
- nie zapewniają natywnego ujednolicenia uprawnień między systemami
- mają trudności z zapewnieniem spójnej kontroli dostępu w środowiskach wielosystemowych
- nie posiadają pełnej świadomości modeli tożsamości i autoryzacji w całym przedsiębiorstwie
👉 Sprawia to, że bezpieczeństwo i zarządzanie stają się kluczowym wyzwaniem
4. Brak natywnej obsługi pipeline’ów dokumentowych
W pracy z rzeczywistymi danymi przedsiębiorstwa, zwłaszcza takimi jak:
- dokumenty skanowane
- pliki PDF
- obrazy
organizacje nadal muszą budować:
- pipeline’y OCR
- procesy ingestii dokumentów
- workflowy ekstrakcji danych
Rozwiązania typu Copilot lub Gemini:
- nie zapewniają pełnych pipeline’ów przetwarzania dokumentów
- wymagają dodatkowych usług do OCR i ustrukturyzowanej ekstrakcji danych
👉 Obciążenie związane z integracją pozostaje po stronie organizacji
5. Wyzwania związane ze skalowaniem przy dużych wolumenach danych przedsiębiorstwa
Przedsiębiorstwa operują:
- terabajtami dokumentów
- archiwami historycznymi
- stale rosnącymi zbiorami danych
Systemy typu Copilot lub Gemini nie są zaprojektowane do:
- ingestii danych na dużą skalę
- wsadowego przetwarzania dokumentów
- ciągłego wykonywania pipeline’ów
👉 Są zoptymalizowane pod kątem interaktywnego użycia, a nie skali operacyjnej
6. Przejście od RAG do Agentic RAG
Być może najważniejsze ograniczenie ma charakter koncepcyjny.
Wczesne rozwiązania AI dla przedsiębiorstw koncentrowały się na:
RAG = wyszukaj i odpowiedz
Jednak obecnie przedsiębiorstwa potrzebują:
Agentic RAG = wyszukaj, analizuj i działaj
Wprowadza to nowe wymagania:
- wieloetapowe wnioskowanie
- orkiestrację między systemami
- zautomatyzowane wykonywanie działań
- walidację oraz podejmowanie decyzji
Asystenci typu Copilot:
- działają na niewielką skalę
- koncentrują się na pojedynczych zapytaniach
- nie posiadają rzeczywistych zdolności agentowych
👉 Nie wspierają automatyzacji procesów biznesowych end-to-end
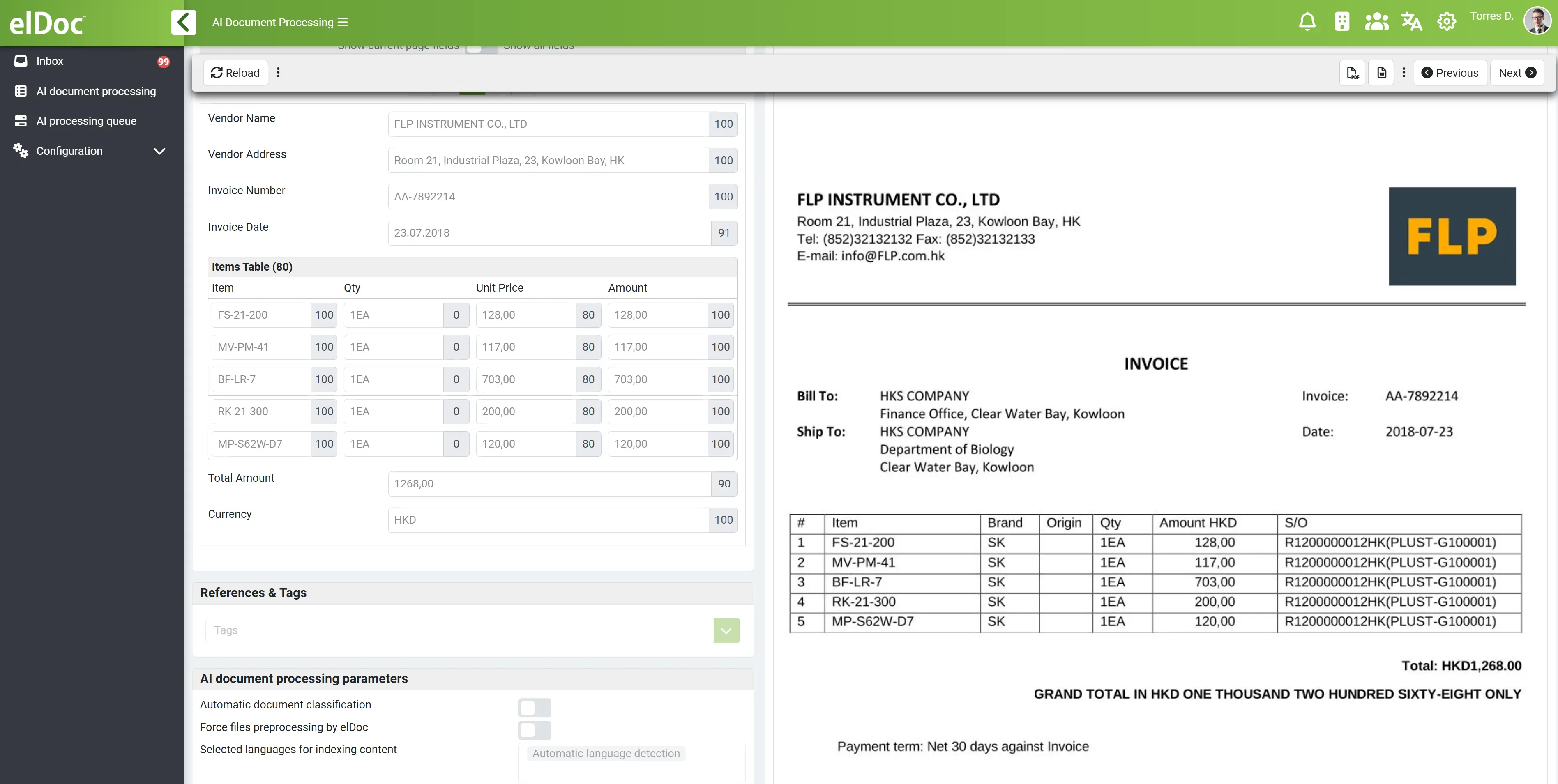
Decyzja strategiczna: budowa czy platforma (Agentic RAG z elDoc)
Na etapie Agentic RAG przedsiębiorstwa osiągają kluczowy moment zwrotny:
Czy powinniśmy samodzielnie zbudować pełny system Agentic RAG, czy wdrożyć platformę taką jak elDoc, która już zapewnia te możliwości?
Nie jest to już wyłącznie wybór techniczny, lecz decyzja strategiczna dotycząca szybkości wdrożenia, ryzyka, skalowalności i bezpieczeństwa.
W miarę jak organizacje przechodzą od AI opartej na czatach oraz wczesnych wdrożeń RAG, coraz bardziej widoczna staje się złożoność budowy i operacyjnego utrzymania systemów Agentic RAG. Przedsiębiorstwa nie mają już do czynienia z odizolowanymi przypadkami użycia, lecz z:
- wieloetapowymi workflowami
- rozproszonymi danymi w wielu systemach
- wrażliwymi i regulowanymi informacjami
- przetwarzaniem dokumentów na dużą skalę (często w terabajtach)
- ciągłymi operacjami w czasie rzeczywistym
👉 Wyzwanie nie polega wyłącznie na inteligencji, lecz na bezpiecznej orkiestracji tej inteligencji na dużą skalę.
Dlaczego Agentic RAG wymaga platformy takiej jak elDoc
Agentic RAG stanowi fundamentalną zmianę w obszarze AI dla przedsiębiorstw.
Nie chodzi już o izolowaną inteligencję ani nawet o połączoną wiedzę, lecz o osadzenie AI w warstwie wykonawczej przedsiębiorstwa.
W przeciwieństwie do tradycyjnych systemów AI, Agentic RAG wprowadza możliwości, które są z natury złożone i wzajemnie powiązane:
- wyszukiwanie danych w wielu systemach przedsiębiorstwa
- wnioskowanie kontekstowe z wykorzystaniem danych historycznych i dynamicznych
- wykonywanie działań (ekstrakcja danych, walidacja, aktualizacje systemów)
- ciągła automatyzacja workflowów oparta na zdarzeniach
Te możliwości nie mogą działać efektywnie w izolacji. Wymagają skoordynowanego, zintegrowanego środowiska.
Dlaczego podejście platformowe jest konieczne
Aby wspierać Agentic RAG na dużą skalę, organizacje potrzebują:
1. Ujednolicony dostęp do danych
- płynnego połączenia z dokumentami, bazami danych i systemami
- możliwości pozyskiwania zarówno danych ustrukturyzowanych, jak i nieustrukturyzowanych
2. Zintegrowane przetwarzanie dokumentów
- natywnej obsługi plików PDF, dokumentów skanowanych i obrazów
- wbudowanych pipeline’ów OCR
- ciągłej ingestii dużych wolumenów dokumentów
3. Wieloetapowe wnioskowanie i walidacja
- iteracyjnego wyszukiwania i analizy
- wnioskowania między dokumentami
- walidacji względem reguł biznesowych i danych historycznych
4. Orkiestracja workflowów
- koordynacja procesów wieloetapowych
- uruchamianie działań w oparciu o zdarzenia
- obsługa wyjątków oraz scenariuszy z udziałem człowieka (human-in-the-loop)
5. Rygorystyczne bezpieczeństwo i kontrola dostępu
- wyszukiwanie z uwzględnieniem uprawnień
- egzekwowanie dostępu opartego na rolach
- bezpieczne środowiska wykonawcze
- pełna audytowalność decyzji i działań
6. Skalowalność dla obciążeń klasy enterprise
- przetwarzanie tysięcy dokumentów dziennie
- obsługa terabajtów danych
- wsparcie dla przetwarzania równoległego oraz operacji w czasie rzeczywistym
7. Wdrożenie w pełni on-premise z izolowanymi środowiskami wykonawczymi
Dla wielu przedsiębiorstw, zwłaszcza w branżach regulowanych, takich jak finanse, opieka zdrowotna czy sektor publiczny, kontrola nad danymi i ich izolacja są absolutnie niezbędne.
Systemy Agentic RAG muszą nie tylko przetwarzać dane na dużą skalę, lecz także zapewniać, że:
- wrażliwe dane nigdy nie opuszczają organizacji
- środowiska są izolowane pomiędzy zespołami, klientami lub jednostkami biznesowymi
- wykonywanie działań jest kontrolowane, audytowalne i bezpieczne
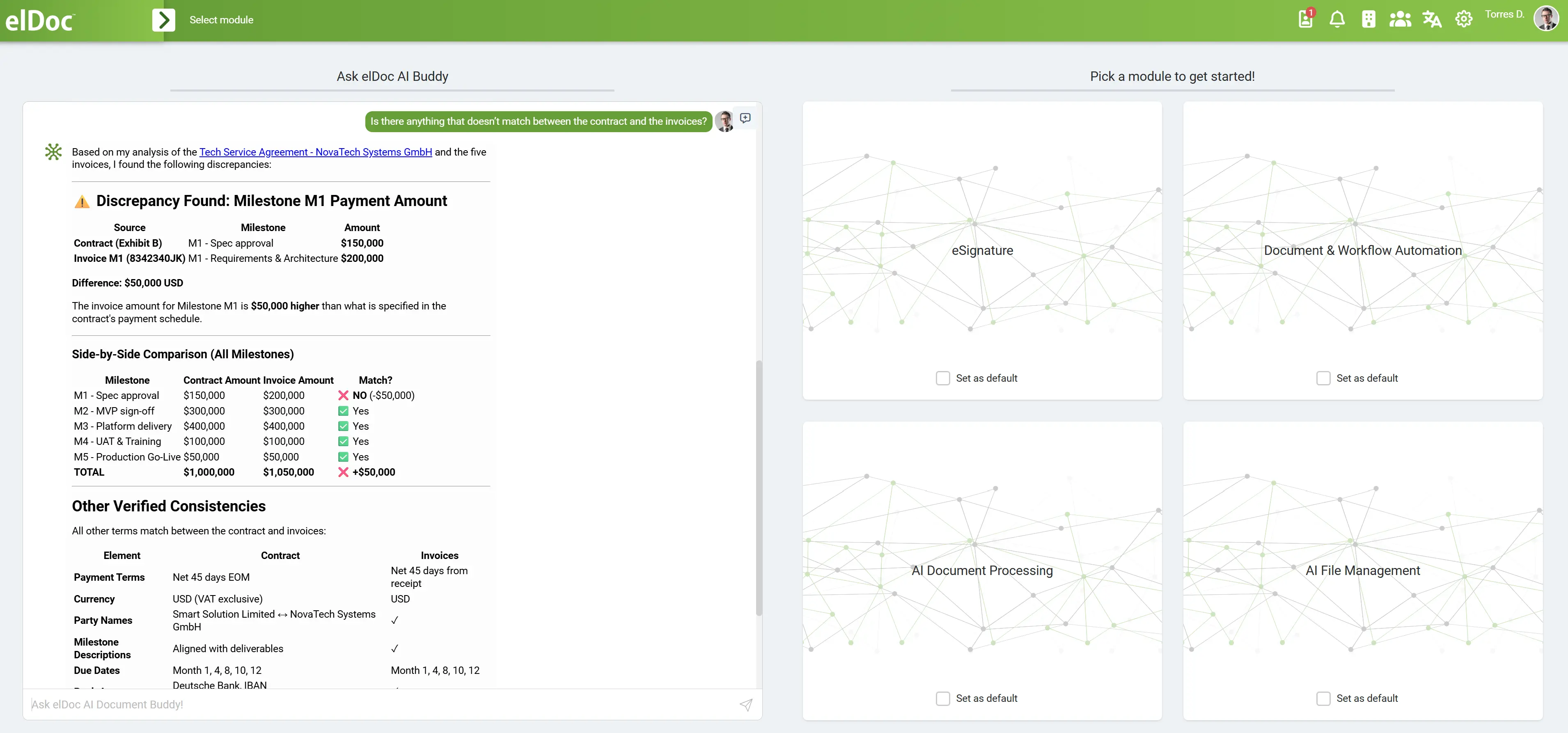
Gotowa architektura: jak działa Agentic RAG w elDoc
elDoc zapewnia w pełni zintegrowaną architekturę Agentic RAG, w której wszystkie wymagane komponenty są połączone w jednej platformie operacyjnej.
Kluczowe komponenty architektury
Pipeline AI w elDoc łączy:
- MongoDB – przechowywanie dokumentów i trwałość danych ustrukturyzowanych
- Apache Solr – wyszukiwanie pełnotekstowe dla zapytań opartych na słowach kluczowych
- Qdrant – wyszukiwanie wektorowe dla podobieństwa semantycznego i kontekstowego pozyskiwania danych
- Silniki OCR – ekstrakcja tekstu z dokumentów skanowanych i obrazów
- Modele LLM – wnioskowanie, interpretacja i generowanie
- Agenci AI – planowanie, orkiestracja i wykonywanie zadań
Kluczowym wymaganiem dla AI w przedsiębiorstwach jest swoboda wyboru i kontrola nad modelami językowymi (LLM). Zamiast uzależniać organizacje od jednego dostawcy, elDoc opiera się na architekturze niezależnej od modelu (model-agnostic), umożliwiając przedsiębiorstwom wybór, łączenie oraz zmianę wiodących modeli LLM w zależności od wydajności, kosztów i wymogów zgodności.
Obsługiwane modele obejmują:
- Claude
- ChatGPT
- DeepSeek
- Kimi
- a także inne modele klasy enterprise lub open source
Proces end-to-end
Documents / Data Sources
↓
OCR & Ingestion
↓
Storage (MongoDB)
↓
Hybrid Retrieval (Solr + Qdrant)
↓
LLM Reasoning
↓
AI Agent Planning & Execution
↓
Validation & Workflow Actions
↓
Output to Enterprise SystemsJak współpracują poszczególne komponenty
1. Ingestia i przetwarzanie
- dokumenty są pobierane z systemów przedsiębiorstwa
- OCR ekstrahuje tekst z plików skanowanych
- dane są przechowywane w MongoDB
2. Hybrydowe wyszukiwanie
- Apache Solr umożliwia precyzyjne wyszukiwanie słów kluczowych
- Qdrant umożliwia semantyczne wyszukiwanie wektorowe
👉 Razem zapewniają:
- precyzyjne wyszukiwanie
- zrozumienie kontekstowe
3. Warstwa wnioskowania
- modele LLM interpretują i analizują pozyskane dane
- wspierają wieloetapowe wnioskowanie między dokumentami
4. Wykonywanie agentowe
- agenci AI dynamicznie planują zadania
- decydują, jakie dane pobrać w kolejnym kroku
- wykonują działania (ekstrakcja, walidacja, aktualizacja systemów)
5. Walidacja i integracja workflowów
- wyniki są walidowane względem reguł biznesowych
- workflowy są uruchamiane
- wyjątki są kierowane do weryfikacji przez człowieka
6. Bezpieczne i kontrolowane działanie
- kontrola dostępu jest egzekwowana na etapie wyszukiwania
- przetwarzane są wyłącznie autoryzowane dane
- wszystkie działania są rejestrowane i podlegają audytowi
Przyspieszenie rozwoju AI w przedsiębiorstwie dzięki bezpiecznemu Agentic RAG
Budowa pipeline’u Enterprise RAG może być właściwym podejściem dla niektórych organizacji, jednak z natury jest to proces złożony, podatny na błędy i wymagający znaczących inwestycji w inżynierię, integrację, bezpieczeństwo oraz ciągłe dostrajanie. W miarę jak przedsiębiorstwa ewoluują w kierunku Agentic RAG, gdzie AI musi nie tylko pozyskiwać informacje, lecz także wnioskować, walidować i wykonywać workflowy na dużą skalę, wyzwania znacząco rosną, co sprawia, że rozwiązania tworzone wewnętrznie są trudne w utrzymaniu i zabezpieczeniu. W przeciwieństwie do tego elDoc oferuje gotowy, bezpieczny framework Agentic RAG, który umożliwia organizacjom wdrożenie AI klasy enterprise od pierwszego dnia, dzięki wbudowanej architekturze, mechanizmom zarządzania, skalowalności i elastyczności. Pozwala to przedsiębiorstwom skupić się na dostarczaniu realnych rezultatów biznesowych poprzez inteligentną i bezpieczną automatyzację, zamiast na budowie i utrzymaniu złożonych systemów.