企業級 Agentic RAG:自建還是採用現成方案(自研 vs elDoc)

企業在採用 AI 的方式上正快速演進。從最初對公開 AI 工具的試驗,已轉變為邁向企業級 AI 系統的策略性轉型。這一發展歷程通常分為三個階段:
- 公開 AI(以聊天為基礎的助理)
- 企業級 RAG(連接內部資料)
- Agentic RAG(能自主執行工作的 AI)
這一轉型的核心在於:
Agentic RAG(檢索增強生成),結合企業知識存取、AI 推理與自動化執行能力。
當企業發展至此階段時,會面臨一項關鍵決策:
應該自行建立 Agentic RAG 系統,還是採用像 elDoc 這樣的平台?
演進歷程:從對話到行動,第 1 階段:公開 AI(孤立式智慧)
企業對 AI 的早期採用始於 Claude、ChatGPT 等公開工具,並引入了簡單的互動模式:
User → AI → Answer此階段帶來了明顯的優勢,如自然語言互動、快速回應以及提升個人生產力。然而,當應用於企業環境時,其限制也迅速顯現。
1. 缺乏企業資料存取能力
公開 AI 系統在運作時未連接企業內部系統,因此無法存取:
- 內部文件
- 結構化資料(ERP、CRM、財務系統)
- 協作平台,例如 Microsoft SharePoint
因此,其回應通常是:
- 通用內容,而非企業專屬
- 未基於實際業務資料
2. 類搜尋行為,而非真正智慧
在實際應用中,早期 AI 更像是一種進階搜尋引擎:
- 擷取並重組既有資訊
- 有效進行內容摘要
- 缺乏對企業情境的深度理解
這意味著:
- 無法理解業務流程
- 無法理解資料之間的關聯性
👉 系統「看似智慧」,但缺乏實際運作層面的理解。
3. 缺乏對歷史與動態資料的理解
企業資料具有以下特性:
- 具歷史性(交易、趨勢、記錄)
- 具動態性(持續變動)
- 分散於多個系統之中
公開 AI 無法:
- 追蹤資料的歷史演變
- 對時間序列模式進行推理
- 結合即時與歷史資訊
👉 這將導致回應在單一情境下可能正確,但與當前業務實際情況不一致。
4. 公開 AI 服務中的資料外洩風險
公開 AI 服務的另一項關鍵限制在於資料處理方式。在多數情況下,使用者必須將文件上傳或將內容貼至外部平台進行處理,這將帶來重大的企業風險。
- 敏感文件(如財務資料、合約、人資紀錄)會離開企業受控環境
- 資料可能在企業安全邊界之外被處理
- 可能暴露於第三方系統或被非預期地保留
👉 對企業而言,這將帶來:
- 合規風險
- 資料外洩疑慮
- 法規違規風險(例如財務或個人資料處理)
公開 AI 在設計之初並未將企業級資料治理作為核心需求。
5. 缺乏存取控制與權限感知能力
公開 AI 服務通常無法理解或執行企業的存取控制機制。
在企業環境中:
- 資料依角色劃分(人資、財務、法務)
- 存取權限在文件、資料夾或系統層級受到控制
- 權限受到嚴格執行
然而,在公開 AI 中:
- 一旦資料被上傳,權限脈絡即會遺失
- AI 無法區分授權與未授權資料
- 未與身份系統或基於角色的存取控制整合
👉 這將產生重大風險:
使用者可能在無意間暴露或處理本不應存取的資料。
6. 無法處理大規模企業資料
企業資料並非小規模或簡單,通常包括:
- 大型文件庫(資料量達 TB 級)
- 掃描影像與 PDF 文件
- 歷史檔案
- 持續增長的資料集
公開 AI 服務面臨實際限制:
- 檔案大小限制
- 上傳限制
- 無法高效處理大量資料
- 不支援持續性資料導入管線
👉 尤其針對掃描文件:
- 需要 OCR 處理
- 需要結構化處理管線
- 無法透過簡單上傳介面完成處理
第 2 階段:企業級 AI 助理(RAG 與 Copilot,已連接但智慧仍有限)
隨著企業逐步超越公開 AI,下一步是採用企業整合型助理,例如 Microsoft Copilot 與 Google Gemini。
這些解決方案引入了企業連接型 AI 的概念,通常由早期的 RAG(檢索增強生成)能力所驅動。
User → Enterprise data (partial access) → AI → Answer相較於公開 AI,這代表了顯著的提升:
- 可存取內部文件
- 與企業工具整合(電子郵件、文件、協作平台)
- 提供更具上下文的回應
然而,儘管有這些進展,企業很快仍面臨結構性限制。
1. 資料存取碎片化
企業 Copilot 通常僅連接特定生態系統,而非整個企業環境。
- 在自身平台內表現強大(例如 Microsoft 或 Google 生態)
- 對外部系統的存取有限或無法存取
- 在以下系統之間整合困難:
- ERP 系統
- 財務平台
- 傳統資料庫
- 第三方應用程式
👉 結果是:
AI 僅能看到企業資料的部分視圖
2. 助理模式,而非營運系統
Copilot 與 Gemini 主要作為個人助理運作,而非企業級營運系統。
它們可以:
- 協助使用者撰寫、摘要或搜尋
- 在應用程式內回應查詢
但它們無法:
- 執行端到端工作流程
- 大規模處理文件
- 自動化多步驟業務流程
👉 工作仍需由使用者主導。
3. 缺乏跨系統的權限感知能力
雖然企業工具會在自身生態系統中執行權限控制,但在以下情況下會出現挑戰:
- 使用者跨部門流動
- 資料跨越多個系統
- 需要跨職能工作流程
AI 助理:
- 無法原生統一跨系統權限
- 在多系統環境中難以維持一致的存取控制
- 缺乏對企業整體身份與授權模型的完整理解
👉 這使得安全性與治理成為關鍵議題
4. 缺乏原生文件處理管線能力
在處理真實企業資料時,尤其是:
- 掃描文件
- PDF 文件
- 影像
企業仍需自行建立:
- OCR 處理管線
- 文件導入流程
- 資料擷取工作流程
類似 Copilot 或 Gemini 的解決方案:
- 未提供完整的文件處理管線
- 需額外整合服務以完成 OCR 與結構化擷取
👉 整合負擔依然存在
5. 面對企業資料規模的擴展挑戰
企業通常處理:
- TB 級文件資料
- 歷史檔案
- 持續增長的資料集
類似 Copilot 或 Gemini 的系統並非為以下需求設計:
- 大規模資料導入
- 批次文件處理
- 持續性管線運行
👉 其設計重點在互動使用,而非營運規模
6. 從 RAG 轉向 Agentic RAG
或許最重要的限制在於概念層面。
早期企業 AI 著重於:
RAG,即檢索並回應
然而,企業如今需要的是:
Agentic RAG,即檢索、推理並執行行動
這帶來新的需求:
- 多步推理
- 跨系統協同
- 自動化執行
- 驗證與決策能力
類 Copilot 的助理:
- 僅在小規模場景中運作
- 著重單一查詢
- 缺乏真正的 Agentic 能力
👉 無法支援端到端的業務流程自動化
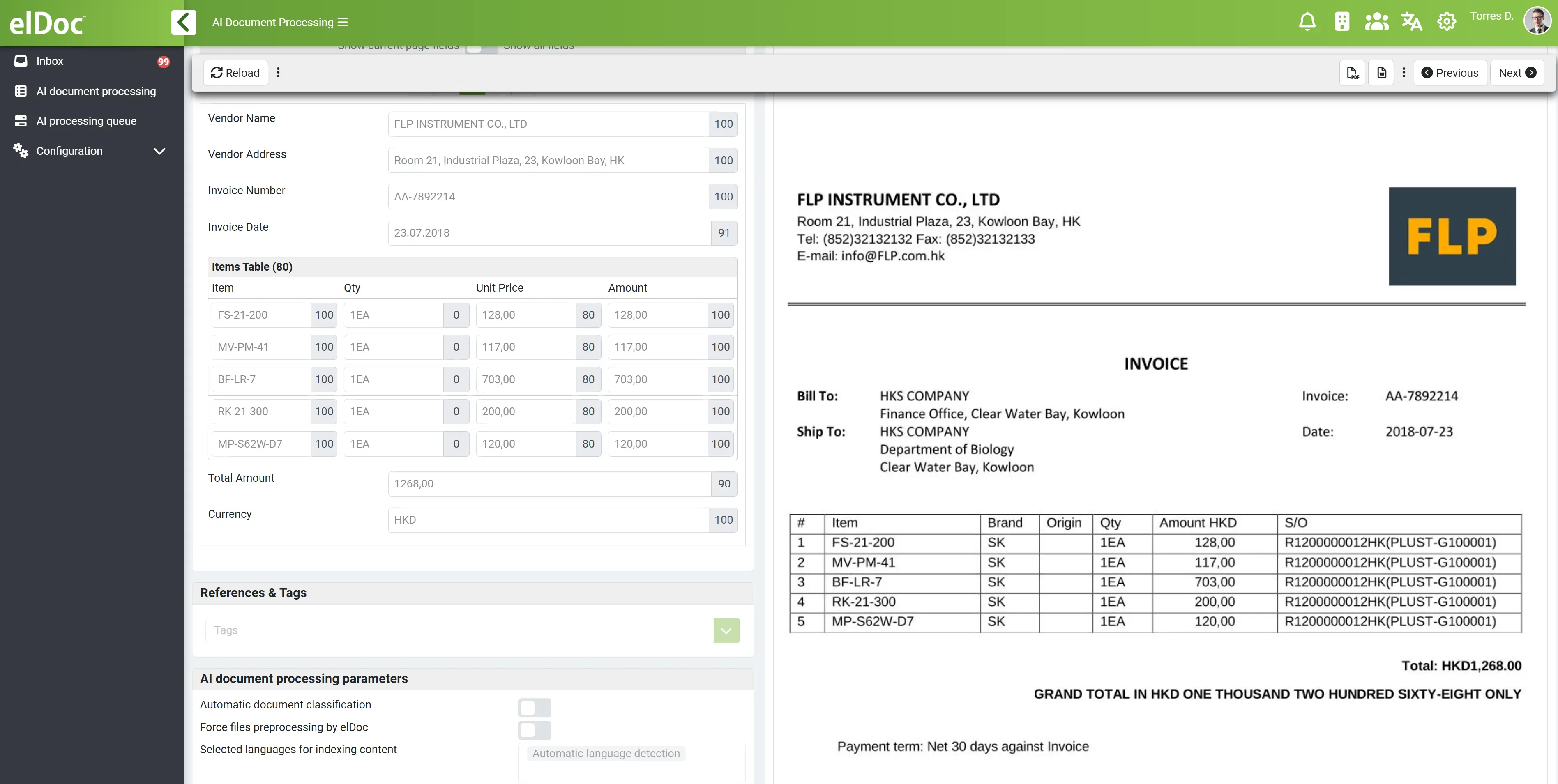
策略性決策:自建還是採用平台,選擇 elDoc 的 Agentic RAG
在 Agentic RAG 階段,企業會面臨關鍵轉折點:
我們應該自行建立完整的 Agentic RAG 系統,還是採用如 elDoc 這樣已具備完整能力的平台?
這已不再只是技術選擇,而是關乎速度、風險、可擴展性與安全性的策略性決策。
隨著企業從聊天式 AI 與早期 RAG 實作邁向更進階階段,建構與運營 Agentic RAG 系統的複雜性愈發明顯。企業不再處理單一應用場景,而是面對:
- 多步驟工作流程
- 跨系統分散的資料
- 敏感與受監管的資訊
- 大規模文件處理,通常達 TB 級
- 持續且即時的運作
👉 挑戰不僅在於智慧能力,而在於如何安全且可擴展地協同運作這些智慧能力。
為何 Agentic RAG 需要像 elDoc 這樣的平台
Agentic RAG 代表企業 AI 的根本性轉變。
它不再只是孤立的智慧或已連接的知識,而是將 AI 深度嵌入企業的執行層。
不同於傳統 AI 系統,Agentic RAG 引入了本質上高度複雜且彼此相互關聯的能力:
- 跨多個企業系統進行檢索
- 結合歷史與動態資料進行上下文推理
- 執行行動,例如資料擷取、驗證與系統更新
- 持續且由事件驅動的工作流程自動化
這些能力無法在孤立環境中有效運作,必須依賴協同且整合的運作環境。
為何平台化方法至關重要
為了在大規模環境中支援 Agentic RAG,企業需要:
1. 統一的資料存取
- 無縫連接文件、資料庫與各類系統
- 能夠同時檢索結構化與非結構化資料
2. 整合式文件處理
- 原生支援 PDF、掃描文件與影像處理
- 內建 OCR 處理管線
- 持續導入大量文件資料
3. 多步推理與驗證
- 迭代式檢索與分析
- 跨文件推理
- 依據業務規則與歷史資料進行驗證
4. 工作流程協同
- 協調多步驟流程
- 根據事件觸發行動
- 處理例外情況與人機協作場景
5. 嚴格的安全性與存取控制
- 基於權限的檢索
- 執行基於角色的存取控制
- 安全的執行環境
- 對決策與行動提供完整可審計性
6. 支援企業級工作負載的可擴展性
- 每日處理數千份文件
- 處理 TB 級資料
- 支援平行執行與即時運作
7. 完全本地部署與隔離式執行環境
對許多企業而言,特別是在金融、醫療與政府等受監管產業中,資料控制與隔離是不可妥協的要求。
Agentic RAG 系統不僅需要大規模處理資料,還必須確保:
- 敏感資料絕不離開企業內部
- 執行環境在團隊、客戶或業務單位之間保持隔離
- 執行過程可控、可審計且安全
即用型架構:Agentic RAG 在 elDoc 中的運作方式
elDoc 提供完整整合的 Agentic RAG 架構,將所有必要組件統一於單一運作平台之中。
核心架構組件
elDoc AI 管線整合以下組件:
- MongoDB:文件儲存與結構化資料持久化
- Apache Solr:基於關鍵字的全文搜尋
- Qdrant:用於語意相似度與上下文檢索的向量搜尋
- OCR 引擎:從掃描文件與影像中擷取文字
- LLM 模型:推理、解讀與生成
- AI 代理:規劃、協同與任務執行
對企業 AI 而言,一項關鍵需求是對大型語言模型的選擇自由與控制能力。elDoc 採用模型無關的架構設計,不會將企業鎖定於單一供應商,使企業能根據效能、成本與合規需求,自由選擇、組合並切換各類領先的 LLM。
支援的模型包括:
- Claude
- ChatGPT
- DeepSeek
- Kimi
- 以及其他企業級或開源模型
端到端流程
Documents / Data Sources
↓
OCR & Ingestion
↓
Storage (MongoDB)
↓
Hybrid Retrieval (Solr + Qdrant)
↓
LLM Reasoning
↓
AI Agent Planning & Execution
↓
Validation & Workflow Actions
↓
Output to Enterprise Systems各組件如何協同運作
1. 導入與處理
- 文件從企業系統中導入
- OCR 從掃描文件中擷取文字
- 資料儲存於 MongoDB
2. 混合式檢索
- Apache Solr 提供精準的關鍵字搜尋
- Qdrant 提供語意向量搜尋
👉 二者結合可提供:
- 準確檢索
- 上下文理解
3. 推理層
- LLM 模型對檢索資料進行解讀與分析
- 支援跨文件的多步推理
4. Agentic 執行
- AI 代理動態規劃任務
- 決定下一步需檢索的資料
- 執行行動,例如擷取、驗證與系統更新
5. 驗證與工作流程整合
- 根據業務規則對結果進行驗證
- 觸發工作流程
- 將例外情況交由人工審核
6. 安全且可控的運作
- 在檢索階段即執行存取控制
- 僅處理已授權資料
- 所有操作皆被記錄並可審計
透過安全的 Agentic RAG 加速企業 AI 發展
對部分企業而言,自行建立企業級 RAG 管線可能是一種可行方式,但其本質上高度複雜、易出錯,且需要在工程、整合、安全與持續優化方面投入大量資源。隨著企業邁向 Agentic RAG,AI 不僅需要檢索資訊,還需在大規模環境下進行推理、驗證並執行工作流程,相關挑戰顯著增加,使自建方案在維護與安全性上更加困難。相較之下,elDoc 提供即用型且安全的 Agentic RAG 框架,使企業能從第一天起採用企業級 AI,並具備內建架構、治理能力、可擴展性與靈活性。這使企業能將重心從建構與維護複雜系統,轉向透過智慧且安全的自動化實現實際業務成果。