Hardware Requirements for Deploying LLMs On-Premise with elDoc

As enterprise adoption of Generative AI continues to accelerate, organizations are increasingly looking beyond public cloud AI services toward secure on-premise AI deployments.
For industries such as government, banking, healthcare, insurance, legal services, and regulated enterprises, data privacy, compliance, latency, and infrastructure control are becoming critical requirements.
This is where on-premise LLM deployment becomes essential.
Why Organizations Are Moving Toward On-Premise LLM Deployments
Cloud-based AI services provide fast experimentation, but many enterprises eventually encounter limitations:
- Sensitive documents cannot leave internal environments
- Compliance regulations require local processing
- AI governance policies restrict third-party data exposure
- Operational costs increase with large-scale AI usage
- Organizations need full control over models, workflows, and integrations
Modern enterprise AI platforms such as elDoc enable organizations to deploy Generative AI securely within private infrastructure while maintaining enterprise-grade automation and governance.
elDoc fully supports:
- On-premise LLM deployment
- Private cloud deployment
- Air-gapped environments
- Hybrid AI architectures
- Multi-model AI orchestration
- Enterprise AI governance
Hardware Requirements Depend on AI Workload Complexity
One of the most common misconceptions is that every AI deployment requires massive GPU clusters. In reality, infrastructure requirements depend entirely on the type of AI processing being performed.
Typical infrastructure planning usually falls into three categories:
1. Light AI Processing
Suitable for:
- Basic chat interfaces
- Internal document Q&A
- Small-scale retrieval augmented generation (RAG)
- Department-level AI assistants
- Lightweight automation
Typical Infrastructure:
- Mac Studio
- Single GPU server
- NVIDIA RTX series GPUs
- 32GB–128GB RAM
- Small vector database infrastructure
This deployment model is ideal for organizations starting their AI journey or deploying isolated AI assistants.
It offers:
- Lower infrastructure costs
- Fast deployment
- Simplified operations
- Minimal power consumption
Many modern open-source LLMs can already perform exceptionally well under this category.
2. Standard AI Processing
Suitable for:
- Enterprise document automation
- Intelligent data capture
- KYC processing
- Legal document understanding
- Workflow automation
- AI-powered classification
- Multi-user AI operations
Typical Infrastructure:
- Multi-GPU server
- NVIDIA L40S / A100 / H100 class GPUs
- 128GB–512GB RAM
- Dedicated vector database infrastructure
- High-speed NVMe storage
This category represents the most common enterprise AI deployment model. Organizations operating enterprise workflows with thousands of documents per day typically fall into this segment.
elDoc is designed specifically for this level of enterprise AI processing.
The platform combines:
- Agentic RAG
- Intelligent document processing
- Human-in-the-loop approvals and verification
- Workflow orchestration
- Enterprise integrations
- AI governance
- Multi-model routing
- AI agents for specific tasks
- Secure document collaboration
within a single operational AI platform.
3. High-Performance AI Processing
Suitable for:
- Large-scale enterprise AI operations
- Multi-department AI workloads
- High-volume document processing with verification checks
- AI factories
- Large-scale legal analysis
- Real-time AI processing
- Enterprise-wide AI personal assistants
- Running GenAI Hub
Typical Infrastructure:
- GPU clusters
- NVIDIA HGX infrastructure
- Multiple H100/H200/B200 GPUs
- Distributed inference architecture
- High-speed enterprise storage
- Kubernetes orchestration
- Enterprise AI networking
This category is typically used by:
- Governments
- Financial institutions
- National-scale enterprises
- Large BPO operations
- Telecommunications providers
- AI service providers
Such deployments often process from several hundred thousand to millions of pages, documents, and AI-driven requests per month across multiple departments and enterprise workflows. Such deployments often process millions of pages and requests per month.
Enterprise On-Premise AI Architecture with elDoc
elDoc provides a production-ready enterprise architecture for deploying Generative AI and Large Language Models fully on-premise or within private cloud environments.
The platform is designed not simply as an AI chatbot layer, but as a complete operational AI infrastructure supporting:
- Agentic RAG
- Intelligent document processing
- AI agents
- OCR pipelines
- Enterprise search
- Workflow automation
- Multi-model orchestration
- Secure enterprise framework
The architecture allows organizations to connect several different LLM models simultaneously depending on the business task and document type being processed.
For example, enterprises may use:
- Chat models for conversational AI
- Agent models for workflow execution
- Vision-language models (VL) for document understanding
- Embedding models for semantic search and RAG
- Reranking models for improving retrieval accuracy
This multi-model architecture enables organizations to optimize both performance and infrastructure costs while significantly improving AI accuracy for enterprise workflows.
The elDoc architecture also integrates:
- MongoDB for operational data management
- Full-text indexing databases for enterprise search
- Vector databases for semantic retrieval and RAG
- OCR services for scanned document processing
- Additional enterprise services and workflow execution
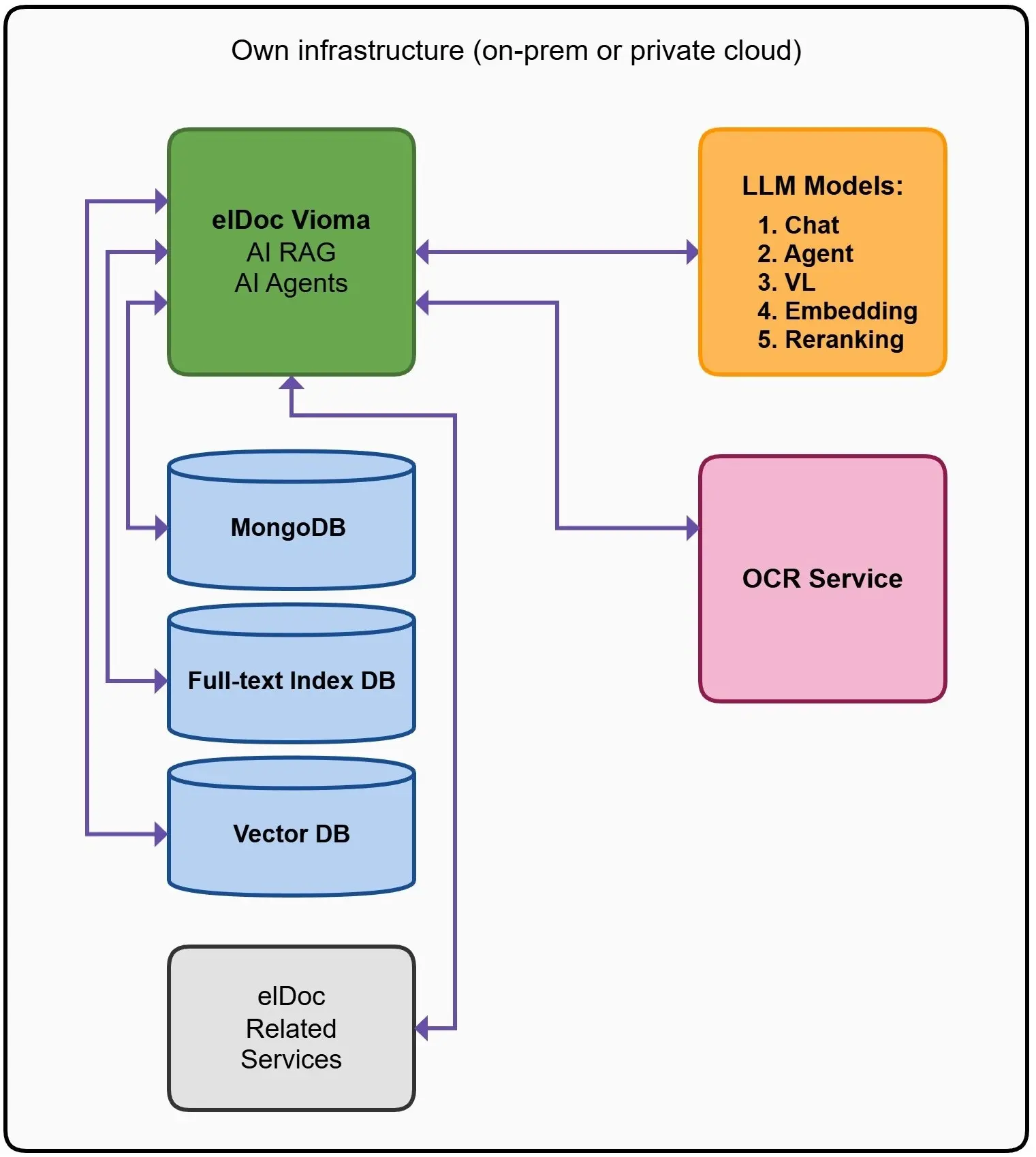
All components operate securely within the organization’s own infrastructure.
This architecture is particularly important for enterprises handling:
- Sensitive documents
- Regulated data
- Government information
- Financial records
- Legal documentation
- Healthcare information
- Internal enterprise knowledge
Unlike isolated AI tools, elDoc delivers end-to-end enterprise AI operations with secure orchestration between document processing, retrieval systems, AI models, and business workflows.
The platform is designed for scalable enterprise deployment and can support environments ranging from lightweight AI processing to high-performance enterprise AI clusters handling hundreds of thousands to millions of pages and AI-driven requests per month.
Hardware Planning and Deployment Guidance
Choosing the right infrastructure depends on several factors:
- Number of concurrent connections (users)
- Expected AI workload
- Document and Data volume
- Concurrent processing requirements
- Model size
- Response time expectations
- Security requirements
- Integration complexity
Detailed hardware deployment recommendations for different deployment sizes can be found here: elDoc Hardware Requirements Guide
Strategic Infrastructure Planning for Enterprise GenAI
Deploying Large Language Models on-premise is not only a technology decision — it is also an infrastructure and operational investment decision. Proper hardware planning is one of the most important factors for building successful enterprise AI environments.
Infrastructure sizing directly impacts:
- AI performance
- User experience
- Scalability
- Operational costs
- Future expansion capabilities
- Energy consumption
- Long-term ROI
Many organizations initially overestimate or underestimate the hardware required for enterprise AI deployments. Working with experienced AI infrastructure specialists can help organizations significantly optimize deployment costs while still achieving high AI performance and operational efficiency.
The right architecture approach can reduce unnecessary infrastructure spending while ensuring that enterprise AI systems remain scalable, secure, and production-ready.
Schedule a Discovery Call
Schedule a discovery call with the elDoc team to better understand hardware requirements, deployment scenarios, infrastructure optimization strategies, and how to build cost-efficient enterprise GenAI environments tailored to your organization’s needs.