Data Extraction with LLM: Available On-Premise or in the Cloud

For more than a decade, data extraction has been the most in-demand capability within Intelligent Document Processing (IDP) solutions. Many vendors emerged, each promising AI-driven automation that could extract key data from documents. However, most failed to deliver on the promise of true intelligent automation. Systems still required endless template configurations, manual training, and rigid setups for every new document type from invoices and contracts to statements and forms.
Modern enterprises need more than traditional OCR or rule-based engines – they need true understanding. With the emergence of Large Language Models (LLMs), data extraction has entered a new era. LLMs can read, interpret, and extract structured information from virtually any document – without brittle templates, pre-training, or manual setup. Whether dealing with invoices, contracts, bank statements, policies, or even long-form correspondence, LLMs understand the context, relationships, and meaning behind the data.
And for many organizations especially in regulated industries and corporate environments — data privacy and control are non-negotiable. Teams want the power of LLMs and AI, but within their own infrastructure, fully under their governance. That’s exactly where elDoc comes in. elDoc delivers the full power of LLM-powered data extraction, giving you the freedom to deploy it 100% on-premise or securely in the cloud — with the same intelligence, performance, and automation capabilities. This post explains how LLM-powered extraction works, why it’s different from legacy IDP, and how to deploy it securely — whether on-premise, in the cloud, or in a hybrid setup.
Why LLM-Powered Extraction?
At elDoc, we are always driven by innovation and the mission to bring the most advanced technologies into real-world business automation. With the emergence of Large Language Models (LLMs), it became evident that these models can completely transform how data is extracted and understood. Traditional OCR and rule-based systems could read characters, but not context. LLMs, on the other hand, read, reason, and comprehend — enabling a new era of true intelligent document understanding.
Unlike legacy systems that rely on rigid templates or long configuration cycles, LLM-powered extraction in elDoc works instantly across a wide variety of document types, even when layouts, languages, or formats change. It adapts dynamically to each document — understanding the intent, relationships, and meaning behind the text.
Here’s why LLM-powered extraction redefines what’s possible:
- Template-Free: Works effortlessly across layouts, vendors, and formats — including PDFs, scans, images, and emails — without any manual setup or predefined zones.
- Structure + Semantics: Goes beyond surface text to truly understand the document, extracting key–value pairs and contextual meaning — for example, identifying discrepancies between invoice terms and a contract clause.
- Rapid Time-to-Value: Move from pilot to production in days, not months. No lengthy training, no complex configuration — just results.
- Extensible by Design: Easily add new fields, document types, or business rules using simple natural-language instructions. The model learns your intent instantly.
By combining LLMs, Retrieval-Augmented Generation (RAG), and elDoc’s advanced document intelligence framework, organizations finally get what the industry has long promised — true automation that reads, understands, and extracts data just like a human would, but at superhuman speed.
Core Capabilities of elDoc for Data Extraction
At elDoc, data extraction is not just about recognizing text — it’s about understanding it. elDoc combines Computer Vision, OCR, LLM intelligence, and RAG-driven reasoning within a single, cohesive pipeline to deliver truly intelligent document understanding. Below are the core components that make this possible:
🧠 1. Computer Vision Pre-Processing
Before any extraction begins, elDoc uses advanced computer vision technology to normalize document images.
If a document is uploaded at the wrong rotation, skewed, or contains visual artifacts such as shadows or smudges — elDoc automatically detects and corrects them.
This ensures that the data extraction process starts from the cleanest and most accurate visual representation possible, improving overall OCR and LLM accuracy dramatically.
🔍 2. OCR (Optical Character Recognition)
Once the image is normalized, OCR technology converts it into machine-readable text. elDoc supports both printed and handwritten text, enabling seamless extraction from scanned documents, PDFs, receipts, forms, and images. This step transforms visual data into structured digital content ready for intelligent processing and understanding by the LLM.

🧩 3. LLM — The Human-Like Understanding Layer
The Large Language Model (LLM) is the heart of elDoc’s extraction pipeline. It doesn’t just “read” — it understands context, relationships, and semantics within your documents. LLM identifies key fields, entities, and patterns such as totals, dates, IBANs, company names, or clauses — even when the structure changes between vendors or formats. It’s capable of cross-document reasoning, such as verifying if an invoice’s payment terms match the corresponding contract or policy.
Beyond extraction, elDoc’s LLM-powered intelligence can also standardize and normalize your data automatically. Documents often come with inconsistencies — different date formats, currencies, naming conventions, or field representations depending on vendors, regions, or document types.
With elDoc, this chaos becomes consistency. The LLM understands context and meaning, enabling it to interpret and convert diverse formats into a unified and structured standard.
For example:
- Date formats like “01/02/2025”, “Feb 1, 2025”, or “2025-02-01” are recognized as the same date and standardized automatically.
- Currency fields such as “USD 1,000”, “1,000$”, or “US Dollars – One Thousand” are normalized into a consistent format.
This normalization ensures that your extracted data is always consistent, clean, and analytics-ready, regardless of the document’s origin or layout.
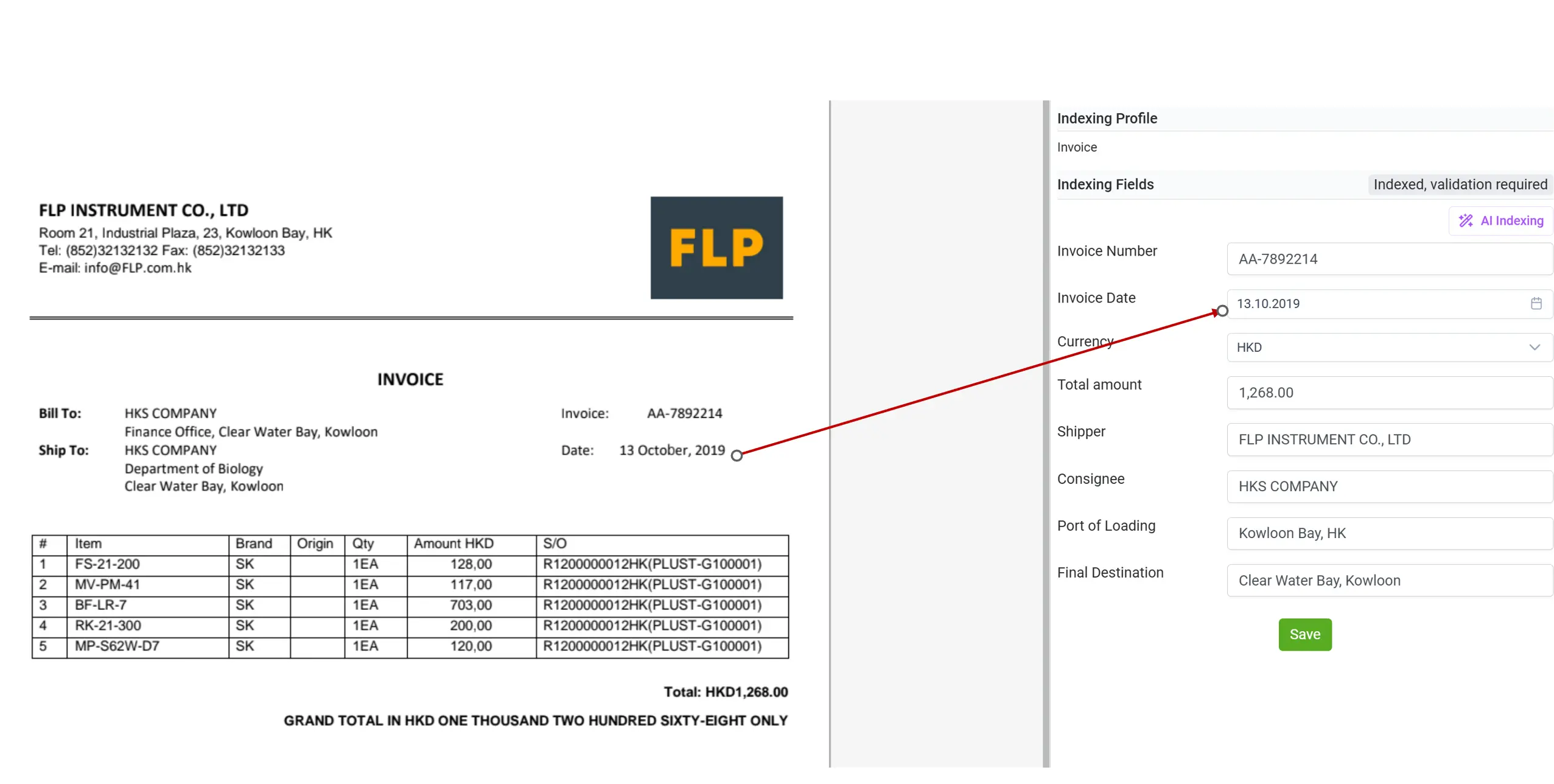
🔗 4. RAG — Deep Reasoning and Document Linking
elDoc integrates Retrieval-Augmented Generation (RAG) to extend LLM capabilities even further. RAG enables the system to retrieve relevant pages, clauses, or supporting documents to ground its understanding and provide fact-based insights. For instance, you can ask elDoc:
“Confirm whether the payment terms in this invoice match the Master Service Agreement.”
RAG finds the relevant clause in the contract and compares it with the invoice data — providing a contextual, verified answer.
This combination of retrieval and reasoning introduces deep document intelligence — far beyond basic extraction.
👩💻 5. Human-in-the-Loop (HITL) Review
Even with the remarkable accuracy of LLM-powered extraction, elDoc recognizes that human validation still plays a vital role – especially in high-stakes or regulated environments. That’s why elDoc provides as optional feature an intuitive Human-in-the-Loop (HITL) interface, designed to combine the efficiency of automation with the precision of expert oversight.
Within this interface, users can:
- Instantly see side-by-side comparisons between the original document and the extracted data.
- Validate, adjust, or approve any field in just a few clicks.
- Add missing information or annotate special cases that require business-specific logic.
Each interaction is logged for full traceability, ensuring compliance and audit readiness.
For organizations handling complex or sensitive documents (such as financial statements, legal contracts, or compliance reports), HITL ensures that no critical decision is made without human assurance, while still benefiting from AI speed and scalability. In short, elDoc’s HITL gives you the best of both worlds: 1) The judgment and oversight of human expertise and 2) The speed and intelligence of automation, and
📤 6. Export & Intelligent Data Storage — From Static Documents to Living Knowledge
Once your documents have been processed, validated, and approved, elDoc transforms extracted information into structured, actionable data. This data can then flow seamlessly into any downstream system, analytics layer, or workflow. With just one click or automated workflow trigger, elDoc enables instant export in multiple formats such as CSV, JSON, Excel, or via API integration to your existing systems — whether that’s your ERP, CRM, accounting platform, or data warehouse. This means extracted data can immediately power your business processes, reports, and dashboards without any manual intervention or reformatting.
But elDoc goes far beyond simple export. All extracted and validated data is automatically stored in elDoc’s intelligent data repository — a secure, structured, and queryable knowledge layer designed for continuous AI analysis and cross-document intelligence.
Within this intelligent data space, your organization can:
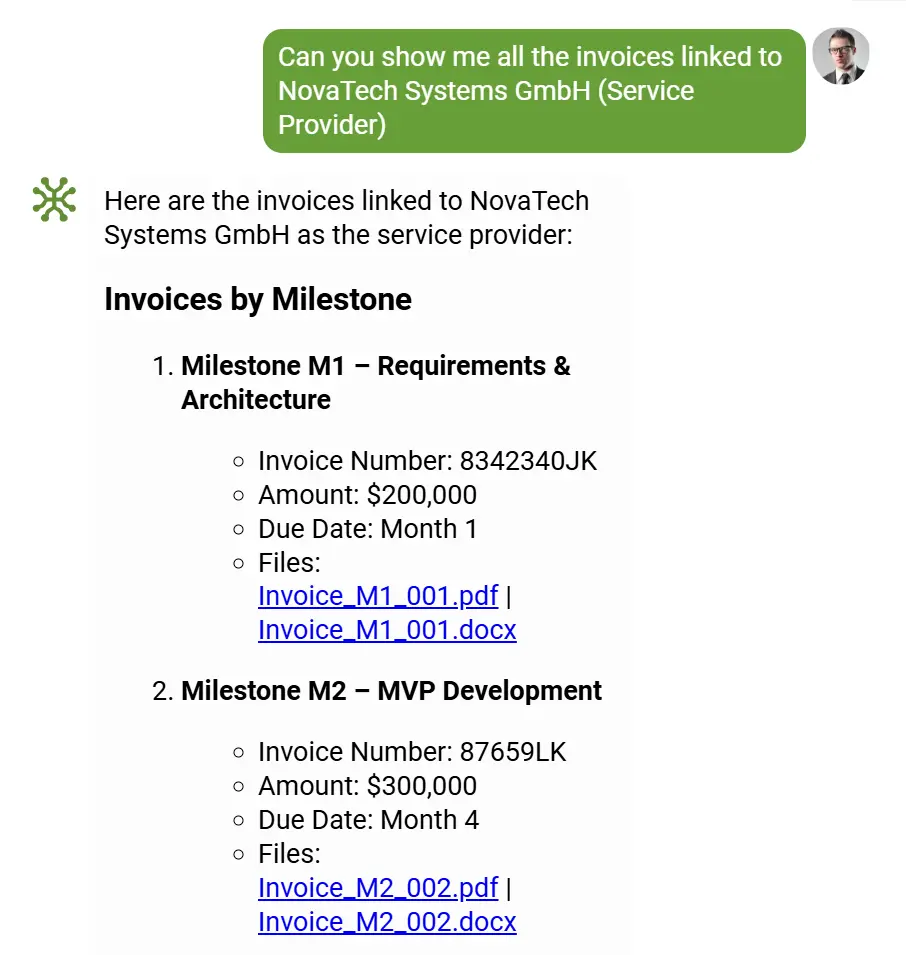
- 🔎 Perform AI-driven queries using natural language (e.g., “Find all invoices above €5,000 issued by Vendor A last quarter”).
- 🔗 Run RAG-powered document search and analysis, retrieving related pages, contracts, or references to provide factual, grounded insights.
- 📊 Execute cross-document analytics — such as comparing payment terms across multiple agreements or finding recurring data inconsistencies.
- 🧠 Conduct further LLM-based reasoning, like asking elDoc to “show all invoices where VAT rate does not match contract terms” or “identify suppliers with duplicate billing entries.”
This intelligent storage layer effectively turns your once-static documents into living, interconnected knowledge assets — always accessible, searchable, and ready for deeper analysis or automation.
Moreover, data governance and compliance are built into every step:
- All stored data is encrypted, access-controlled, and versioned.
- Every change, export, or access request is fully traceable for audit and compliance purposes.
- Administrators can define retention policies, access rules, and export rights per role or department.
In essence, elDoc doesn’t just extract and store your data — it elevates it.
Your document data becomes a continuously growing intelligent knowledge base, empowering both humans and AI to make faster, smarter, and more confident business decisions.
🔒 LLM Data Extraction with elDoc – Available On-Premise and in Cloud
The rise of Generative AI (GenAI) and Large Language Models (LLMs) has transformed the world of document processing. Organizations can now extract, understand, and analyze data with human-like intelligence and context awareness. However, while the potential is extraordinary, not every organization is comfortable sending their confidential documents to third-party cloud systems — and rightfully so. Enterprises in finance, government, healthcare, and legal sectors handle highly sensitive information — contracts, statements, compliance reports, and personal data — where data sovereignty, security, and privacy are non-negotiable. For these organizations, the question is not whether AI can help, but how to use it securely within their own infrastructure.
That’s exactly where elDoc stands apart. elDoc delivers true LLM-powered data extraction and GenAI document intelligence — fully available on-premise, with no data ever leaving your environment. You get the same advanced AI capabilities, reasoning power, and performance as in the cloud version, but deployed within your own secure infrastructure, under your full control.
With elDoc On-Premise, you can:
- 🏢 Run all LLM and RAG processes locally — directly on your servers or private cloud, ensuring that no document, text, or metadata is transmitted externally.
- 🔐 Maintain full control over your data residency, encryption keys, and access management.
- ⚙️ Use your preferred LLM — open-source, fine-tuned, or enterprise-grade — fully integrated with elDoc’s intelligent document processing pipeline.
- 🚀 Experience identical performance to cloud deployments thanks to optimized GPU/CPU orchestration and lightweight inference design.
- 🧩 Combine hybrid intelligence — use on-premise for sensitive workloads while connecting to cloud for large-scale analytics or less confidential document types.
This approach brings the best of both worlds — the power of Generative AI with the confidence of full local governance.
In practice, elDoc’s on-premise deployment empowers enterprises to:
- Deploy LLM-based document intelligence behind their firewall,
- Integrate with internal ERPs, CRMs, ystems securely,
- Ensure compliance with strict regulatory requirements (GDPR, HIPAA, SOC2, ISO 27001),
- And still enjoy fast, human-like understanding and data extraction from any document format.
Whether you choose to deploy on-premise, in the cloud, or hybrid, elDoc guarantees identical functionality, scalability, and precision. The difference is simple: you decide where your data lives. Because true intelligent automation shouldn’t come at the cost of your data privacy — and with elDoc, it never does.