How to Classify and Organize Documents with AI / LLM?

In today’s data-heavy world, organizations handle thousands of documents every day: contracts, invoices, HR files, policies, orders, reports, emails, and more. For years, businesses of all sizes from large global enterprises to small companies and even individual professionals have been dreaming of a solution that could manage this chaos automatically.
Why?
Because handling documents manually is slow, repetitive, not intelligent, and often overwhelming. Sorting, naming, tagging, filing, validating, and organizing documents consumes hours of productive time while still being prone to human error. It’s costly, inefficient, and nearly impossible to scale.
The good news?
Modern AI and LLM-powered document intelligence systems like elDoc finally make this dream achievable by automating classification, organization, and data structuring with exceptional speed and accuracy.
This blog explains how AI/LLM technology transforms document classification and organization and why elDoc’s AI-native approach is a game-changer for any document-heavy organization looking to eliminate manual work and embrace true intelligent automation.
Why This Was Not Possible Before?
For decades, many vendors tried to automate document processing using a mix of OCR, AI, machine learning, and especially NLP technologies. And while these tools brought partial improvements, they never fully solved the core problem. Even with all these technologies combined, traditional AI stacks still lacked true intelligence.
They required:
- endless template creation,
- continuous model training,
- manual annotations,
- rigid rules, and
- constant maintenance.
The systems could not truly “understand” documents the way humans do. If a document layout changed, if the text was unstructured, if formatting was inconsistent, or if the content was long and complex — the automation broke instantly. This is why organizations were stuck with manual reviews, manual sorting, and manual validation for years.
LLMs Changed Everything
The emergence of Large Language Models completely transformed what machines can comprehend.
LLMs can now:
- understand context,
- interpret meaning,
- read unstructured text,
- extract insights,
- compare related documents,
- and reason across long content — almost like a human.
What was impossible for OCR-, ML-, or NLP-based systems suddenly became achievable. With LLMs, the ability to analyze, classify, and organize documents is no longer dependent on templates or training. The system understands the document’s intent, semantics, and structure instantly even if it’s messy, inconsistent, scanned, or unstructured. This breakthrough is what makes modern AI platforms like elDoc capable of delivering true intelligent document processing today.
What You Still Need to Achieve True AI Classification & Sorting?
Even though LLMs revolutionized document understanding, real AI-driven classification still requires a coordinated tech ecosystem. Each layer plays a key role in turning raw, messy documents into structured, searchable, intelligently organized knowledge.
🔤 1. OCR — Converting Images & PDFs into Text
Most documents arrive as scans, images, or non-searchable PDFs. OCR converts them into machine-readable text so AI can actually “read” the content.
✔ Extracts text from images
✔ Makes PDFs searchable
✔ Enables further AI processing
🖼️ 2. Computer Vision — Cleaning & Normalizing the document
Before AI interprets anything, Computer Vision prepares the document:
✔ Deskews and aligns pages
✔ Enhances low-quality scans
✔ Detects tables, signatures, stamps
✔ Understands layout and structure
This step ensures accuracy even for messy, rotated, or noisy documents.
🧠 3. LLM — True Understanding of Content
The Large Language Model is the “brain” behind intelligent classification:
✔ Understands meaning and context
✔ Recognizes document types
✔ Interprets unstructured text
✔ Extracts key information
✔ Classifies documents like a human
This is the intelligence old ML/NLP systems could never achieve.
🔎 4. RAG — Connecting Context Across Documents
Retrieval-Augmented Generation (RAG) boosts intelligence by using your actual documents as a knowledge base.
✔ Finds related documents
✔ Performs cross-document analysis
✔ Detects inconsistencies (e.g., invoice vs contract)
✔ Answers complex queries using multiple files
RAG turns your document library into a dynamic knowledge system.
🗄️ 5. Structured Storage — Metadata and Files
Document-Oriented Database (e.g. MongoDB) as primary storage engine
✔ Stores large files with exceptional efficiency
✔ Manages all associated metadata seamlessly
This handles massive datasets (multiple terabytes) with stable and predictable behavior.
🧭 6. Vector Database — Semantic Understanding & Similarity
A vector database (e.g., Qdrant) is essential for modern AI search and clustering.
✔ Semantic search (“find similar documents”)
✔ Duplicate detection
✔ Grouping and similarity scoring
✔ Linking related files automatically
This is what allows AI to organize documents intelligently not just alphabetically.
📁 7. Document Collaboration Suite — Where Everything Comes Together
Finally, all these technologies must operate within a unified platform where users can:
✔ View, search, and organize files
✔ Validate extracted data (HITL)
✔ Share documents securely
✔ Run workflows
✔ Manage versions & permissions
✔ Perform AI searches and analysis
Build Everything from Scratch Or Use elDoc for Instant AI Classification & Organization?
Achieving true AI-powered document classification and organization requires a complex ecosystem of technologies: OCR, Computer Vision, LLMs, RAG, structured storage, vector search, workflow engines, audit trails, security, and a full collaboration suite. Building all of this on your own is not only time-consuming but extremely costly and technically demanding.
This is exactly what elDoc was designed for
With decades of experience in delivering robust Intelligent Document Processing solutions, elDoc already includes every essential pillar needed for modern AI-driven document automation. Its architecture is purposely designed to meet today’s AI and LLM demands – ready from day one, with no templates, no training, and no complex setup.
elDoc brings together, in a single seamless platform:
🔒 MongoDB
A highly scalable, document-oriented database designed to store large volumes of structured and semi-structured data extracted from documents. It ensures fast retrieval, flexible schema evolution, and reliable performance even when processing millions of files simultaneously.
🧭 Qdrant
A high-performance vector database that transforms document intelligence from keyword-based to semantic. Qdrant enables elDoc to:
- understand content beyond exact matches
- find similar documents instantly
- cluster related files
- match invoices to contracts
- detect duplicates and near-duplicates
- support semantic AI search
This creates true “intelligent document navigation,” not just filtering.
🔤 Multiple OCR Engines
To handle every document type and quality level, elDoc uses several OCR engines, choice is yours.
- Tesseract – open-source OCR for general extraction
- Google OCR API – high-accuracy cloud OCR for complex text
- Qwen3-VL – vision-language OCR for AI-powered layout understanding
- PaddleOCR – extremely fast, multilingual OCR engine
This multi-engine approach ensures maximum accuracy across scanned PDFs, photos, multi-language documents, and low-quality images.
🔎 Apache Solr
A proven enterprise search engine used for high-speed indexing and keyword-based retrieval.
Solr supports:
- instant full-text search
- faceted (filter-based) navigation
- advanced ranking and relevance
- massive indexing scalability
Combined with AI and vector search, it forms a hybrid search system: keyword + semantic + AI deep search.
🖼️ Computer Vision Layer
Before AI reads and understands a document, Computer Vision prepares and normalizes it.
This layer performs:
- deskewing of rotated scans
- denoising and contrast correction
- detection of tables, stamps, signatures, and diagrams
- page layout recognition
- segmentation of complex multi-section documents
This dramatically improves OCR quality and LLM accuracy.
🧠 Built-in LLM Intelligence
The heart of elDoc’s document understanding capabilities.
LLMs enable:
- human-level comprehension of unstructured content
- intelligent document classification
- contextual data extraction
- semantic grouping and sorting
- interpretation of long and complex files
- natural-language interaction with documents
elDoc supports multiple LLM providers, sizes, and deployment modes including fully on-premise setups for sensitive environments.
🔍 RAG (Retrieval-Augmented Generation)
RAG transforms single-document processing into multi-document intelligence.
With RAG, elDoc can:
- link documents together
- detect inconsistencies across files
- connect contracts with invoices, reports, or emails
- perform cross-document Q&A
- build context-aware insights
This enables superhuman-level document reasoning.
🗂️ Metadata Management
Every document uploaded to elDoc automatically receives intelligent metadata enrichment.
The system captures and organizes:
- document type
- vendor/client information
- dates, totals, identifiers
- project or department tags
- classification categories
- AI-generated labels and summaries
This metadata powers filtering, analytics, automation, and search.
📁 Secure File Repository & Collaboration Suite
elDoc is not just an AI engine — it is a full document operations platform.
It provides:
- secure storage with access controls
- permission-based sharing
- real-time collaboration
- editing and annotation
- review and approval workflows
- audit trails
- version control
- activity logs and governance features
Users can organize, manage, analyze, and collaborate on documents — all in one place, without switching systems.
Designed for True AI Workflows – Not Legacy Automation
elDoc’s architecture is LLM-ready by design, supporting large-scale unstructured data processing, multi-document reasoning, and deep semantic understanding. Everything is already orchestrated to work together, without requiring users to connect or maintain different tools. Where other systems require configuration, training, and manual rules, elDoc works straight out of the box.
You Simply Ask — and Your AI Document Employee Does the Rest
Instead of spending hours manually sorting, naming, grouping, or validating documents, elDoc allows you to manage everything through natural language:
- “Organize these documents by type and year.”
- “Group contracts by renewal date.”
- “Identify all documents related to this supplier.”
- “Compare the contract with all connected invoices and find discrepancies.”
Your AI Document Employee performs the work instantly, intelligently, and with superhuman accuracy turning what was once a manual burden into an effortless command.
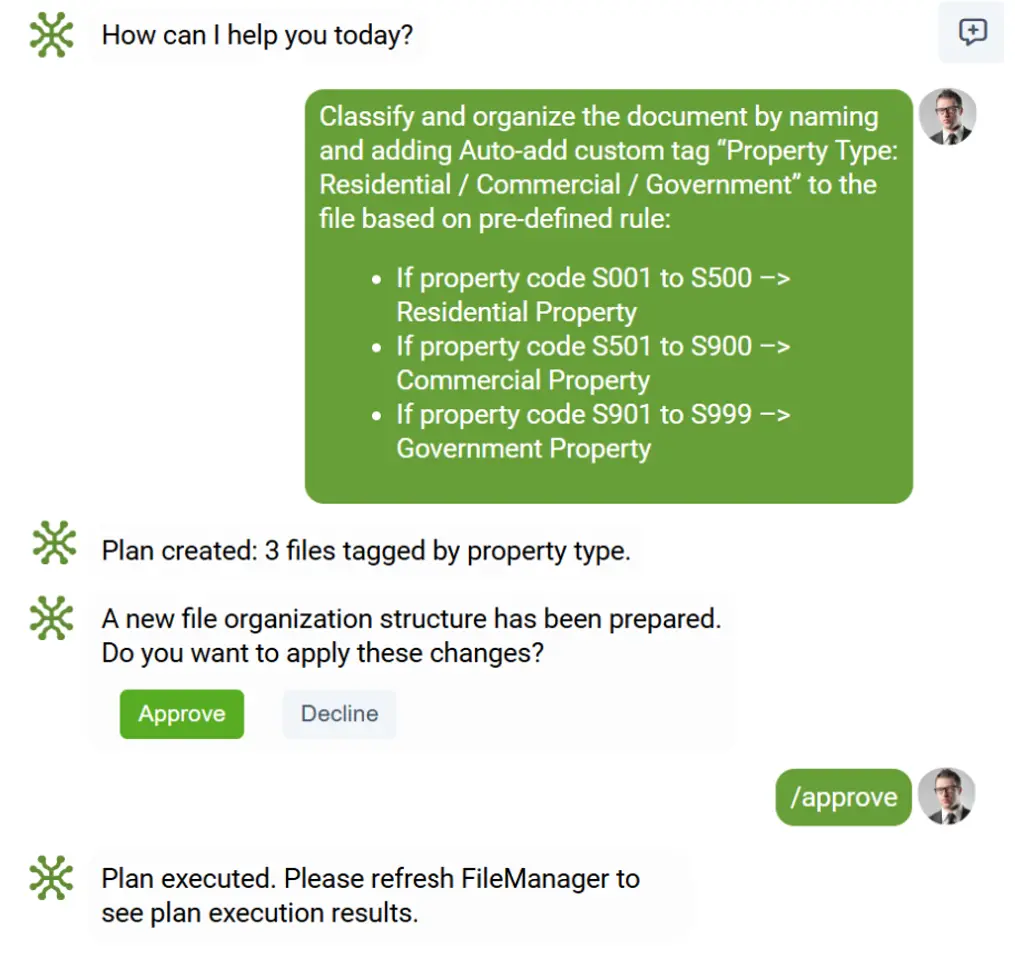
elDoc Makes AI Document Classification & Sorting a Reality
With elDoc, intelligent document classification and sorting are no longer distant promises – they are practical, accessible, and effortless realities. There is nothing to worry about when you need to organize, structure, or make sense of your files. You simply log in, upload your documents, and let your AI Document Employee – your always-available digital assistant handle the hard work for you. Once everything is organized, you can collaborate on your files, share them securely, manage versions, edit, review, and approve documents seamlessly. All of this happens inside one unified platform designed to simplify your workflow and elevate your document processes with true AI intelligence.