Architektura Agentic RAG w elDoc dla inteligencji dokumentów w środowisku enterprise

Organizacje typu enterprise nie potrzebują AI, która tylko prowadzi rozmowy. Potrzebują AI, która potrafi zrozumieć zadanie, przeszukiwać dokumenty i dane w całym środowisku, łączyć informacje z różnych źródeł, wnioskować na podstawie znalezionych danych oraz pomagać w realizacji rzeczywistej pracy w bezpiecznym środowisku. Właśnie tutaj kluczową rolę odgrywa Agentic RAG.
W elDoc Agentic RAG to nie tylko pobieranie kilku istotnych fragmentów tekstu i proszenie modelu językowego o ich podsumowanie. To orkiestracja pełnego pipeline’u AI, w którym współdziałają różne technologie: przechowywanie dokumentów, ekstrakcja tekstu, wyszukiwanie słów kluczowych, wyszukiwanie wektorowe, modele rozumowania oraz agenci AI, którzy potrafią planować i realizować zadania wieloetapowe. Takie połączenie pozwala elDoc wyjść poza pasywny dostęp do dokumentów i przejść do aktywnej, zorientowanej na zadania inteligencji dla treści enterprise.
Co oznacza Agentic RAG w praktyce
Tradycyjne wyszukiwanie dokumentów pomaga użytkownikom znajdować pliki. Podstawowy czat AI pomaga użytkownikom zadawać pytania. Podstawowy RAG poprawia odpowiedzi, opierając je na odnalezionych treściach.
Agentic RAG idzie o krok dalej: umożliwia systemowi interpretację zapytania użytkownika, podjęcie decyzji, jak je rozwiązać, wykonanie wielu kroków wyszukiwania i rozumowania, walidację znalezionych informacji oraz złożenie użytecznego wyniku końcowego. Zamiast polegać na pojedynczym kroku wyszukiwania i odpowiedzi, system może realizować proces bliższy temu, jak pracuje doświadczony analityk:
Najpierw rozumie zapytanie, określa, jakie informacje są potrzebne, identyfikuje, gdzie mogą się one znajdować, pozyskuje odpowiednie dane, analizuje je, sprawdza, czy są wystarczające, w razie potrzeby przeprowadza dodatkowe wyszukiwania, a następnie tworzy końcową odpowiedź, podsumowanie, raport lub wynik gotowy do działania.
To stanowi istotę działania Agentic RAG w elDoc.
Pipeline AI w elDoc
Siła Agentic RAG w elDoc wynika ze sposobu, w jaki kilka wyspecjalizowanych komponentów współpracuje jako jeden skoordynowany system. Każdy komponent pełni inną rolę, a wartość wynika z tego, jak wzajemnie się uzupełniają.
MongoDB: przechowywanie dokumentów
U podstaw pipeline’u znajduje się MongoDB, które pełni rolę warstwy przechowywania dokumentów. Środowiska dokumentowe w organizacjach enterprise rzadko są proste. Dokumenty mogą występować w różnych formatach, pochodzić z różnych działów oraz mieć odmienne struktury, pola metadanych, stany cyklu życia i klasyfikacje bezpieczeństwa. Elastyczna i skalowalna warstwa przechowywania jest niezbędna do zarządzania tą złożonością.
MongoDB odpowiada na tę potrzebę, oferując strukturę, która pozwala przechowywać nie tylko sam dokument, ale także kontekst, który czyni go użytecznym w workflow AI. Może on obejmować metadane, takie jak typ dokumentu, dział, autor, data, wersja, odniesienie do procesu biznesowego, kontrola dostępu, wyodrębniony tekst, struktura chunków, informacje o indeksowaniu oraz powiązania z innymi rekordami.
Jest to istotne, ponieważ Agentic RAG nie operuje wyłącznie na surowym tekście. Potrzebuje również kontekstu. Na przykład gdy użytkownik pyta o luki w politykach, niespójności zgodności, zobowiązania kontraktowe lub ryzyka procesowe, system musi wiedzieć nie tylko, co zawiera tekst, ale także która wersja dokumentu jest aktualna, który dział jest za niego odpowiedzialny, czy plik został zatwierdzony oraz jak jest powiązany z innymi treściami.
MongoDB zapewnia fundament danych strukturalnych i półstrukturalnych, który umożliwia realizację bardziej zaawansowanych workflow.
Apache Solr: wyszukiwanie pełnotekstowe
Nie każde zapytanie w środowisku enterprise powinno być rozwiązywane wyłącznie za pomocą wyszukiwania wektorowego. W wielu rzeczywistych scenariuszach biznesowych ogromne znaczenie mają dokładne terminy, nazwy, kody, odniesienia, daty, identyfikatory, sformułowania prawne czy terminologia specyficzna dla danej domeny. Dlatego Apache Solr odgrywa kluczową rolę w pipeline’ie elDoc.
Solr oferuje zaawansowane możliwości wyszukiwania pełnotekstowego, które umożliwiają odnajdywanie dokumentów i fragmentów na podstawie trafności słów kluczowych, dopasowania dokładnych fraz, filtrowania, facetingu, ograniczeń metadanych oraz logiki rankingowej. Jest to szczególnie wartościowe w środowiskach enterprise, gdzie użytkownicy mogą wyszukiwać:
- numery umów
- identyfikatory faktur
- kody projektów
- nazwiska pracowników
- zapisy polityk
- klauzule prawne
- terminologię techniczną
- język specyficzny dla działu
Na przykład, gdy użytkownik pyta o wszystkie odniesienia do konkretnego dostawcy, numeru polityki lub wymogu regulacyjnego, wyszukiwanie pełnotekstowe może być najszybszą i najbardziej niezawodną metodą pozyskania danych. Solr pomaga systemowi precyzyjnie odnajdywać takie jednoznaczne odniesienia. W kontekście Agentic RAG ma to znaczenie, ponieważ agent może zdecydować, czy dane zapytanie najlepiej obsłużyć poprzez precyzyjne wyszukiwanie słów kluczowych, wyszukiwanie semantyczne, czy ich połączenie. Solr staje się jednym z kluczowych narzędzi, które agent wykorzystuje, aby oprzeć swoje działania na wysoce trafnych danych.
Qdrant: wyszukiwanie wektorowe
Chociaż wyszukiwanie pełnotekstowe doskonale sprawdza się w przypadku dokładnych dopasowań, użytkownicy enterprise często zadają pytania w języku naturalnym, które nie odpowiadają dokładnie sformułowaniom zapisanym w dokumentach. Właśnie tutaj kluczową rolę odgrywa Qdrant jako warstwa wyszukiwania wektorowego. Wyszukiwanie wektorowe umożliwia elDoc pozyskiwanie informacji na podstawie podobieństwa semantycznego, a nie tylko zgodności słów. Oznacza to, że system potrafi odnaleźć istotne treści nawet wtedy, gdy sformułowania w dokumencie różnią się od tych użytych w pytaniu użytkownika.
Na przykład użytkownik może zapytać:
- „Jakie są główne ryzyka realizacji w tej umowie?”
- „Czy istnieją ukryte zobowiązania dla dostawcy?”
- „Pokaż miejsca, w których zakres odpowiedzialności jest niejasny.”
- „Które polityki określają limity zatwierdzeń?”
Odpowiednie dokumenty mogą nie zawierać dokładnie tych samych sformułowań. Zamiast tego mogą używać powiązanych terminów, takich jak zobowiązania usługowe, klauzule odpowiedzialności, obowiązki eskalacyjne, delegowanie uprawnień czy wymogi zatwierdzania wyjątków. Wyszukiwanie oparte wyłącznie na słowach kluczowych może pominąć istotne informacje. Wyszukiwanie wektorowe pozwala odzyskać ten kontekst.
W elDoc Qdrant wspiera głębsze wyszukiwanie semantyczne w fragmentach dokumentów enterprise. Pozwala to systemowi odnajdywać znaczeniowo powiązane fragmenty i wzbogacać zestaw danych, który analizuje agent.
Jest to szczególnie przydatne w złożonych scenariuszach użycia, takich jak:
- analiza między dokumentami
- przegląd polityk i zgodności
- analiza kontraktów
- identyfikacja ryzyk operacyjnych
- due diligence
- odkrywanie wiedzy
- zapytania i odpowiedzi w środowisku enterprise dla zróżnicowanych treści
Silniki OCR: ekstrakcja tekstu
Zanim dokumenty mogą być przeszukiwane, analizowane lub poddawane rozumowaniu, ich treść musi zostać przekształcona do formy czytelnej dla maszyn. W środowiskach enterprise nie zawsze jest to proste. Wiele istotnych dokumentów przechowywanych jest jako skanowane pliki PDF, obrazy, podpisane formularze, archiwa papierowe lub eksporty dokumentów o słabej strukturze tekstu. Bez ekstrakcji pliki te pozostają niewidoczne dla AI.
Dlatego silniki OCR stanowią kluczowy element pipeline’u AI w elDoc.
OCR, czyli optyczne rozpoznawanie znaków, umożliwia elDoc ekstrakcję tekstu ze skanów i plików graficznych, tak aby treść mogła zostać zindeksowana, podzielona na fragmenty, przeszukiwana i wykorzystana w dalszych etapach workflow AI. Ten krok ma znacznie większe znaczenie, niż mogłoby się wydawać. Jakość ekstrakcji tekstu bezpośrednio wpływa na jakość wyszukiwania, rozumowania i wyników końcowych. Jeśli tekst jest niekompletny, zniekształcony, błędnie odczytany lub źle podzielony, system AI będzie dysponował słabszymi danymi do analizy.
W praktyce OCR umożliwia elDoc rozszerzenie zakresu działania AI na rzeczywiste archiwa enterprise, zamiast ograniczać inteligencję wyłącznie do plików cyfrowych. Pozwala włączyć do jednej warstwy wiedzy możliwej do przeszukiwania i analizy archiwalne dokumenty, procesy oparte na papierze, podpisane formularze, starsze skany oraz załączniki operacyjne.
Oznacza to pełniejsze wyszukiwanie, lepszy kontekst i większą wartość biznesową.
Modele LLM: rozumowanie i generowanie
Po odnalezieniu istotnych informacji kolejnym krokiem nie jest jedynie ich powtórzenie. System musi je zinterpretować, porównać, syntetyzować, wyjaśnić i wygenerować użyteczną odpowiedź. To właśnie rola warstwy LLM. Duże modele językowe w elDoc są wykorzystywane do rozumowania i generowania. Pomagają przekształcić pozyskane dane w wyniki, które są zrozumiałe i możliwe do wykorzystania przez użytkowników.
W zależności od zadania może to obejmować:
- odpowiadanie na pytania na podstawie odnalezionych dokumentów
- podsumowywanie wniosków z wielu źródeł
- identyfikowanie niespójności lub brakujących informacji
- porównywanie klauzul, polityk lub wersji
- wyodrębnianie zobowiązań, ryzyk, dat lub zakresów odpowiedzialności
- przygotowywanie raportów lub ustrukturyzowanych wyników
- wyjaśnianie wyników prostym, zrozumiałym językiem
Kluczowe jest to, że model nie działa w izolacji. W podejściu Agentic RAG model LLM jest osadzony w pozyskanych danych i stanowi część szerszego workflow zarządzanego przez agenta.
Ma to znaczenie, ponieważ użytkownicy enterprise nie potrzebują ogólnego generowania tekstu. Potrzebują wiarygodnych wyników opartych na autoryzowanych i istotnych danych. LLM zapewnia interpretację i zdolności językowe, natomiast warstwy wyszukiwania i agentów gwarantują, że proces rozumowania opiera się na konkretnych danych.
Agenci AI: planowanie i realizacja zadań
Warstwą definiującą Agentic RAG jest agent AI. Agent nie odpowiada jedynie na podstawie pojedynczego zapytania. Działa raczej jak inteligentny koordynator. Interpretuje cel użytkownika, określa wymagane kroki, dobiera odpowiednie narzędzia, ocenia wyniki pośrednie i decyduje, czy przed wygenerowaniem końcowej odpowiedzi konieczne jest dodatkowe wyszukiwanie lub analiza.
To właśnie przekształca standardowy system RAG w system Agentic RAG.
W elDoc agent może orkiestruje wiele etapów pracy, takich jak:
- rozumienie intencji użytkownika
- dobór strategii wyszukiwania
- łączenie wyszukiwania słów kluczowych i semantycznego
- weryfikacja, czy pozyskane dane są wystarczające
- inicjowanie dodatkowych wyszukiwań, jeśli pozostają luki
- agregowanie wniosków z wielu dokumentów
- strukturyzowanie wyników w sposób dopasowany do zadania
Zamiast jednorazowej interakcji system staje się sterowanym silnikiem workflow dla zadań opartych na wiedzy.
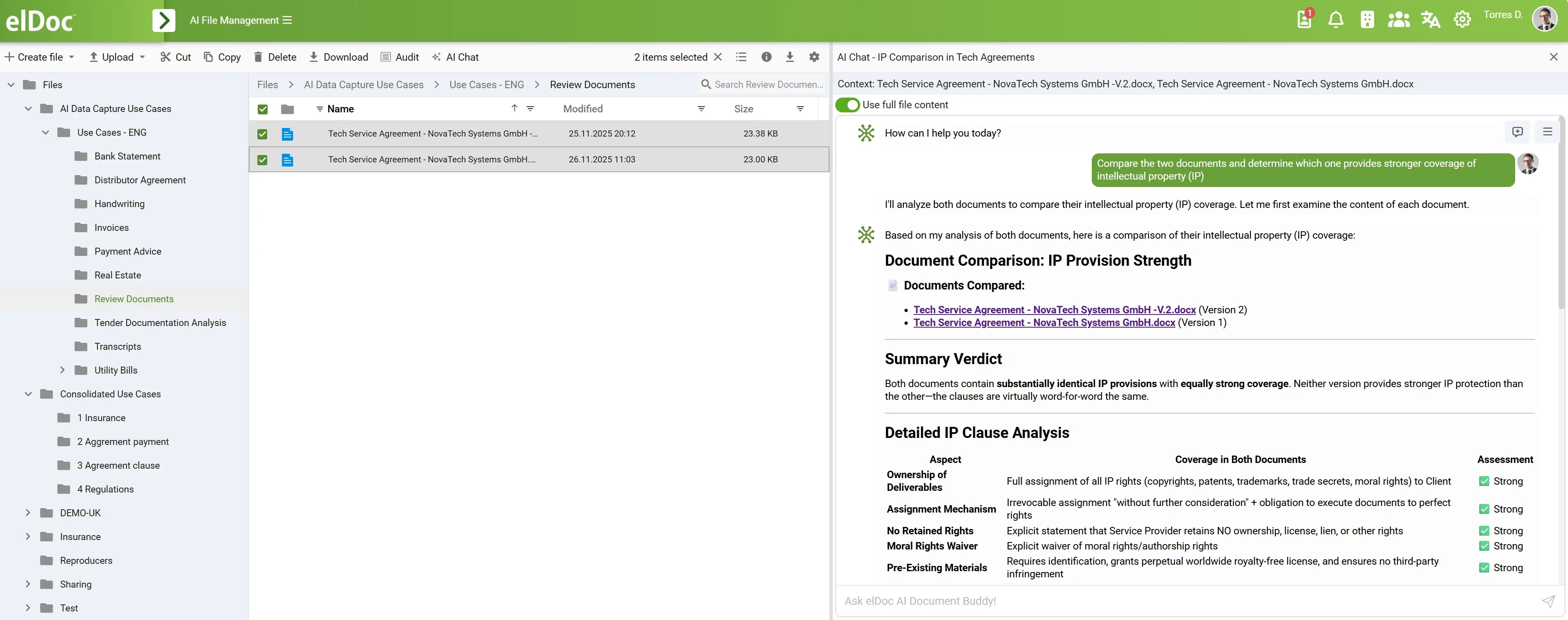
Jest to szczególnie istotne w zastosowaniach enterprise, gdzie zapytania rzadko są proste. Użytkownik może chcieć zidentyfikować ryzyka procesowe, porównać wersje umów, znaleźć sprzeczne polityki, przeanalizować dokumentację dostawcy, wykryć brakujące zatwierdzenia lub podsumować dane na potrzeby raportu zarządczego. Zadania te wymagają planowania, iteracji oraz rozumowania uwzględniającego kontekst. To agent umożliwia ich realizację.
Dlaczego wieloetapowe rozumowanie wzmacnia Agentic RAG
Rzeczywista siła Agentic RAG wynika z wieloetapowego rozumowania.
Wiele zadań w środowisku enterprise nie może być wiarygodnie rozwiązanych za pomocą pojedynczego zapytania i jednego kroku wyszukiwania. Istotne informacje mogą być rozproszone w wielu dokumentach. Kluczowe ryzyka mogą być sugerowane, a nie wyrażone wprost. Krytyczne dane mogą stać się istotne dopiero wtedy, gdy wstępne ustalenia wskażą na inne źródła.
Wieloetapowe rozumowanie pozwala elDoc dynamicznie podejść do problemu. Zamiast zakładać, że pierwsze odnalezione fragmenty są wystarczające, system może przeanalizować zadanie, gromadzić dane etapami, doprecyzowywać wyszukiwanie i budować pełniejszą odpowiedź. Dzięki temu znacznie lepiej sprawdza się w złożonych zadaniach opartych na wiedzy, takich jak:
- analiza zgodności
- przegląd umów
- wsparcie audytu
- ujednolicanie polityk
- due diligence
- analiza procesów
- odkrywanie wiedzy w środowisku enterprise
- analiza oparta na dokumentach
Innymi słowy, Agentic RAG jest skuteczny, ponieważ pozwala AI działać mniej jak statyczny chatbot, a bardziej jak inteligentny asystent, który potrafi przeprowadzić analizę problemu krok po kroku.
Agentic RAG musi zapewniać zarówno efektywność, jak i bezpieczeństwo; w elDoc jest to wbudowane w architekturę
Chociaż wieloetapowe rozumowanie stanowi o sile Agentic RAG, wprowadza ono również kluczowy wymóg: bezpieczeństwo na każdym etapie workflow.
W elDoc Agentic RAG został zaprojektowany nie tylko do rozumienia, wyszukiwania i wnioskowania w całym środowisku dokumentów enterprise, ale także do działania wyłącznie w kontrolowanym i bezpiecznym środowisku.
Za każdym razem, gdy użytkownik wysyła zapytanie, system nie rozpoczyna od razu wyszukiwania. Najpierw elDoc weryfikuje, kim jest użytkownik i do jakich danych ma dostęp. Zapewnia to, że wszystkie kolejne działania — wyszukiwanie, analiza i generowanie odpowiedzi — są w pełni zgodne z politykami dostępu obowiązującymi w organizacji.
Podstawą tego podejścia jest kontrola dostępu oparta na rolach (RBAC), która określa, jakie dane każdy użytkownik może przeglądać i z którymi może pracować. Agenci AI w elDoc dziedziczą te uprawnienia i działają ściśle w ich ramach. Nie mogą wyszukiwać, analizować ani generować wyników na podstawie informacji, do których użytkownik nie ma uprawnień.
Oznacza to, że:
- każde zapytanie uwzględnia uprawnienia
- każde wyszukiwanie jest kontrolowane pod względem dostępu
- każda odpowiedź opiera się wyłącznie na autoryzowanych danych
Jednak bezpieczeństwo w elDoc wykracza daleko poza RBAC.
Platforma wykorzystuje wielowarstwowy model bezpieczeństwa klasy enterprise, zapewniający ochronę w obszarach tożsamości, danych, infrastruktury i operacji:
- Bezpieczeństwo tożsamości i dostępu: uwierzytelnianie wieloskładnikowe (MFA), hasła jednorazowe (OTP) oraz integracja z systemami tożsamości w organizacji zapewniają, że dostęp do platformy mają wyłącznie zweryfikowani użytkownicy
- Szczegółowe uprawnienia i kontrola: precyzyjne polityki dostępu na poziomie dokumentów i danych, rygorystycznie egzekwowane podczas każdej interakcji z AI
- Monitorowanie, rejestrowanie i audytowalność: pełna identyfikowalność działań użytkowników, zapewniająca przejrzystość, zgodność i nadzór
- Bezpieczne opcje wdrożenia: wsparcie dla środowisk on-premise, chmury prywatnej oraz hybrydowej, zapewniające pełną kontrolę nad miejscem przechowywania i przetwarzania danych
- Izolowane środowiska: możliwość uruchamiania elDoc w całkowicie odseparowanych infrastrukturach, co jest kluczowe dla organizacji przetwarzających dane wrażliwe lub poufne
- Wysoka dostępność i odtwarzanie po awarii: niezawodność klasy enterprise dzięki odpornej architekturze, zapewniająca ciągłość działania procesów opartych na AI
Takie wielowarstwowe podejście zapewnia, że wraz ze wzrostem możliwości AI dzięki wieloetapowemu rozumowaniu nie pojawia się dodatkowe ryzyko.
W elDoc AI nie omija zabezpieczeń — egzekwuje je.
Od momentu zadania pytania aż po końcowy wynik każdy etap workflow Agentic RAG jest nieustannie weryfikowany pod kątem polityk obowiązujących w organizacji. Gwarantuje to, że przedsiębiorstwa mogą wykorzystywać zaawansowane AI w całym środowisku swoich dokumentów i danych, zachowując pełną kontrolę, zgodność i bezpieczeństwo.