Intelligent Document Processing with LLM: No Templates, No Configuration – Just Intelligence

For the last few decades, there has been a continuous wave of new technologies promising to automate document processing from end to end — a discipline that became known as Intelligent Document Processing (IDP).
Dozens of vendors were born to solve this challenge, each claiming to achieve full automation across complex document types. Yet, none could reach true perfection.
Why? Because documents in the real world are highly diverse, unstructured, and unpredictable.
The key challenges of traditional IDP solutions built on OCR, AI, Machine Learning, and NLP included:
⚙️ Heavy configuration and template setup — every new document format required manual rule creation, zoning, and layout design.
🔁 Constant re-training — even small changes in a document’s structure or layout broke existing models, forcing teams to retrain again and again.
📄 Limited document coverage — most vendors specialized in just one or two domains (e.g., invoices, bills, ID cards, passports) and struggled with other document types.
⚠️ Accuracy and false positives — extracted data often contained errors or inconsistencies, creating serious financial and compliance risks for organizations.
🧑 High operational overhead — models required continuous training, monitoring, validation, and exception handling.
🚫 Human-in-the-loop dependency — despite all “automation” claims, true straight-through processing was rarely possible; a human always had to verify, correct, or approve results.
As a result, what was supposed to be intelligent document automation turned into a complex, maintenance-heavy ecosystem of templates, configurations, and re-training cycles — far from the simplicity and agility organizations were seeking.
How LLM Transforms Intelligent Document Processing
The emergence of Large Language Models (LLMs) has completely transformed the landscape of Intelligent Document Processing (IDP). While traditional IDP relied on OCR, Machine Learning, and Natural Language Processing, these technologies could only automate structured and semi-structured data leaving a huge gap when it came to understanding complex or unstructured documents.
Now, with LLM technology combined with OCR and Computer Vision, these missing gaps are finally closed.
LLMs bring human-like comprehension into document automation enabling systems to not only “see” the text but also understand the meaning, context, and intent behind it.
Here’s how LLMs revolutionize the entire IDP process:
🧩 No Need for Templates or Configuration
LLMs can instantly adapt to any document layout or structure — no zoning, rule creation, or template setup required.
🤖 No Machine Learning Training or Human Supervision Needed
Forget endless model retraining or human-in-the-loop corrections. LLMs work out of the box, understanding new document types without additional training cycles.
⚡ Instant Data Extraction
Information is extracted instantly with full context awareness — no pre-processing delays or complex data mapping required.
🎯 Greater Accuracy and Reliability
LLMs drastically reduce false positives by interpreting meaning and validating extracted data based on logical context, not just pattern recognition.
🔄 Complex Data Unification and Normalization
LLMs can automatically convert data formats — for example, transforming words into digits, currencies, or dates — eliminating the need for post-processing or manual normalization.
🧠 Semantic Understanding of Content
Beyond extraction, LLMs can read and comprehend unstructured text such as contracts, reports, or correspondence, identifying obligations, risks, and intent.
🌍 Any Document, Any Format
From handwritten notes to scanned contracts, invoices, financial statements, or emails — LLMs can process any structure or format, something that was impossible for decades.
In short, LLMs have turned IDP from rule-based automation into true intelligence. The combination of OCR + Computer Vision + LLM represents the ultimate convergence — where machines can finally “read, understand, and decide” just like humans.
How elDoc Leverages LLM for Intelligent Document Processing – and the Results It Delivers
At elDoc, we’ve fully embraced the new era of LLM-powered Intelligent Document Processing (IDP) — combining Large Language Models, OCR, and Computer Vision to deliver true document understanding, not just automation.
Unlike traditional systems that depend on rigid templates, manual setup, and human supervision, elDoc’s AI Document Employees work intelligently, adapting instantly to new document types, layouts, and formats. The result is seamless document comprehension — from data extraction to interpretation — without requiring any pre-training or configuration.
With LLM at its core, elDoc can read, reason, and make sense of information just like a human expert would. It doesn’t just extract text — it understands the context, relationships, and intent behind every document. Whether processing invoices, contracts, audit reports, or regulatory documents, elDoc intelligently interprets meaning, validates extracted data, and normalizes it into consistent formats ready for business use.
Zero Templates or Configuration
With elDoc, documents are processed instantly — regardless of their structure, layout, or format. You don’t need to create templates, define zones, or configure mappings. The only thing you specify is what data you want to capture — simply a list of the fields or values you’re interested in. Once the documents are uploaded, elDoc automatically performs OCR and Computer Vision, accurately recognizing every element on the page. Then, LLM intelligence takes over, interpreting the content, performing automatic indexing, and capturing the required data with precision — all without manual setup or intervention.
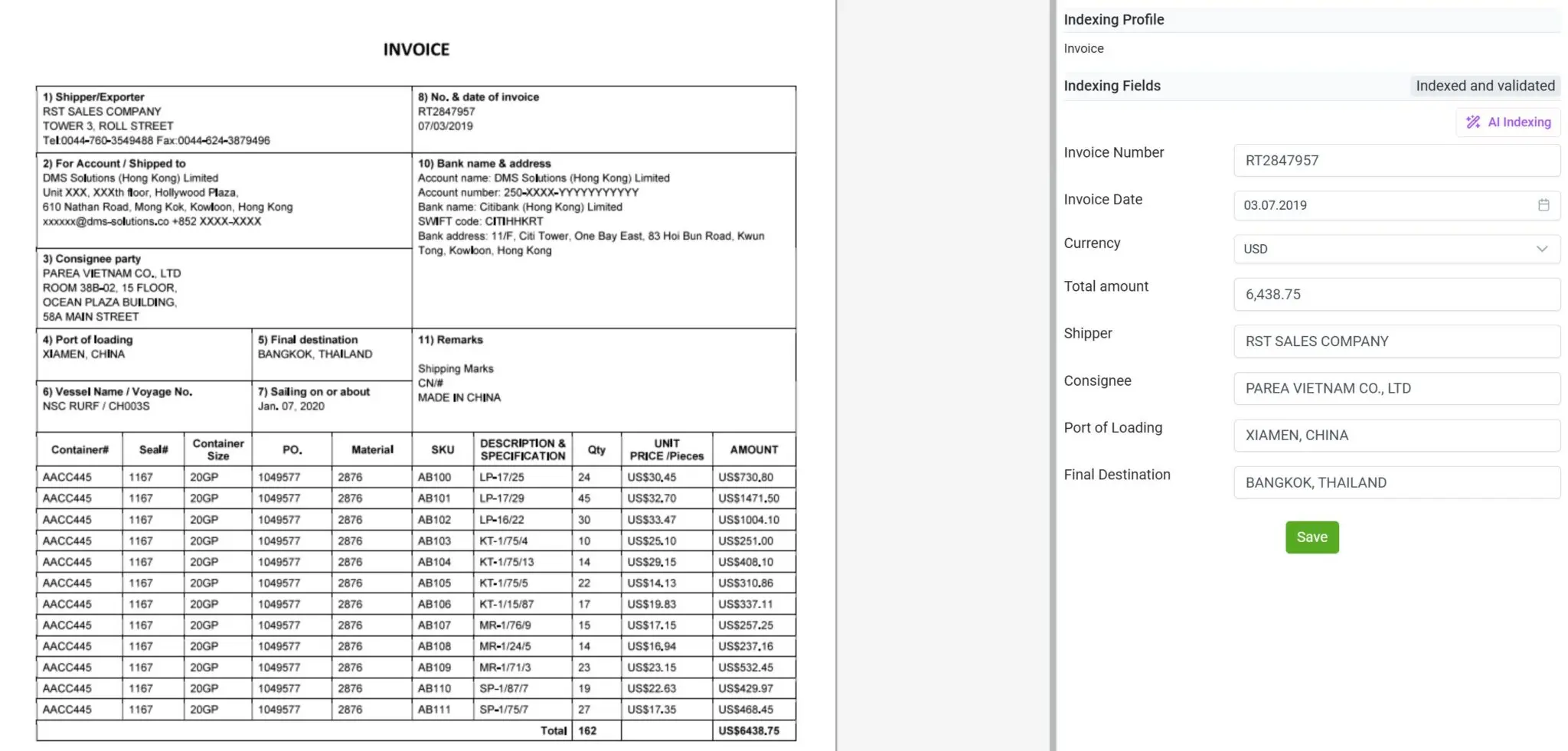
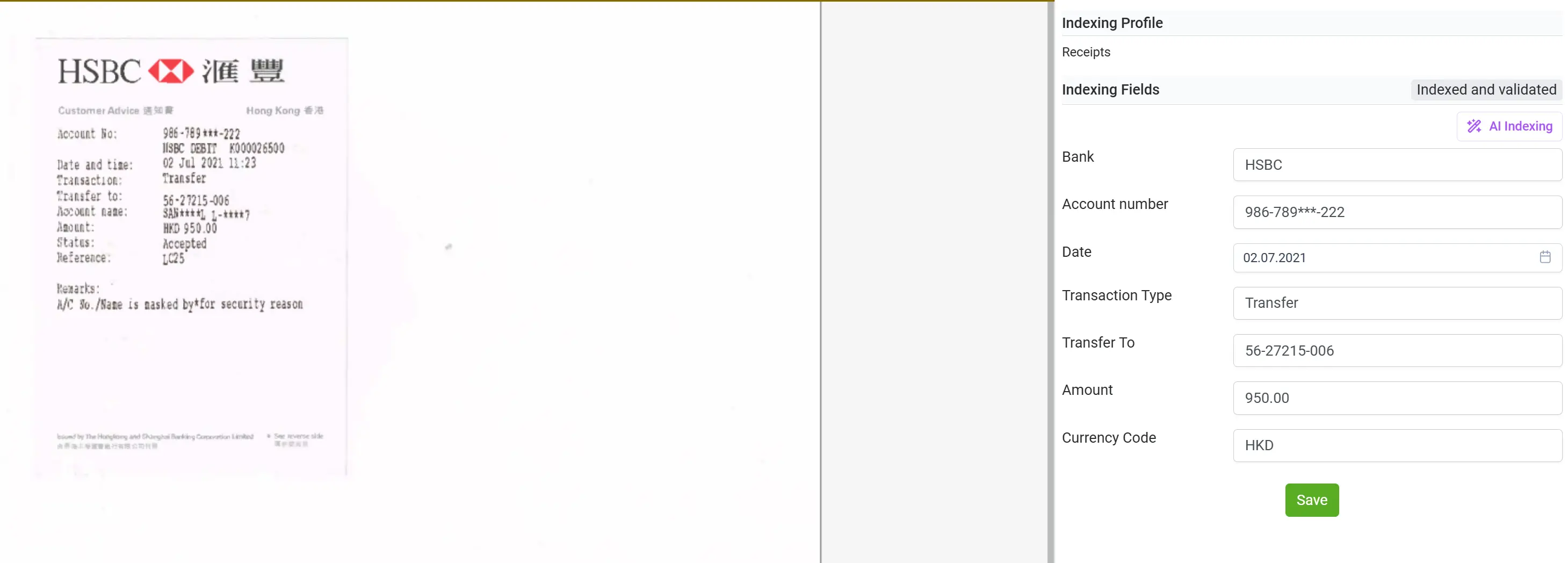
Handling a Wide Variety of Documents, not only Invoices
With elDoc, you’re no longer limited to processing only invoices or structured forms. The platform is designed to handle a broad spectrum of document types — including ATM receipts, utility bills, correspondence, contracts, purchase orders, bank statements, transcripts, and many more.
Whether the document is scanned, handwritten, or digitally generated, elDoc’s combination of OCR, Computer Vision, and LLM enables it to intelligently read, interpret, and extract relevant data with precision. This versatility allows organizations to centralize all document workflows within a single platform — eliminating the need for multiple specialized tools and achieving true end-to-end document intelligence across departments and use cases.
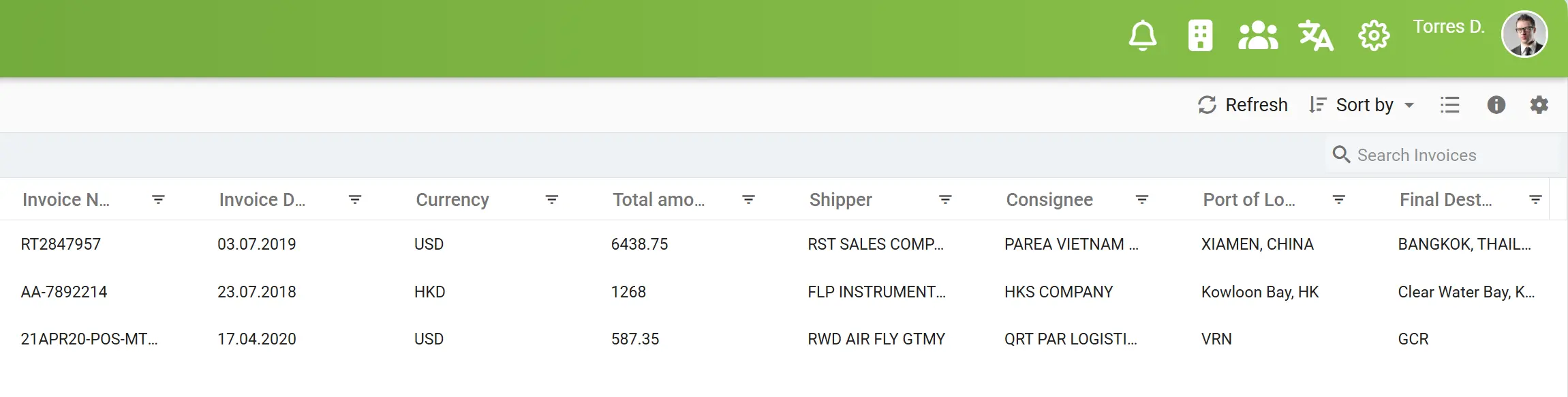
Automated Data Population
Once elDoc completes the data extraction process, all captured information is automatically populated into your centralized indexing panel. This panel acts as a smart, structured layer where extracted fields are instantly organized, categorized, and made available for further processing. The indexed data can then be used for powerful search, filtering, and cross-document analysis, allowing users to quickly locate information across large document sets.
This automation not only eliminates manual data entry and classification but also ensures that all information remains consistent, traceable, and ready for downstream workflows – whether for auditing, compliance checks, or advanced analytics. With elDoc, your previously unstructured data becomes a fully searchable, structured knowledge base, accessible in seconds.
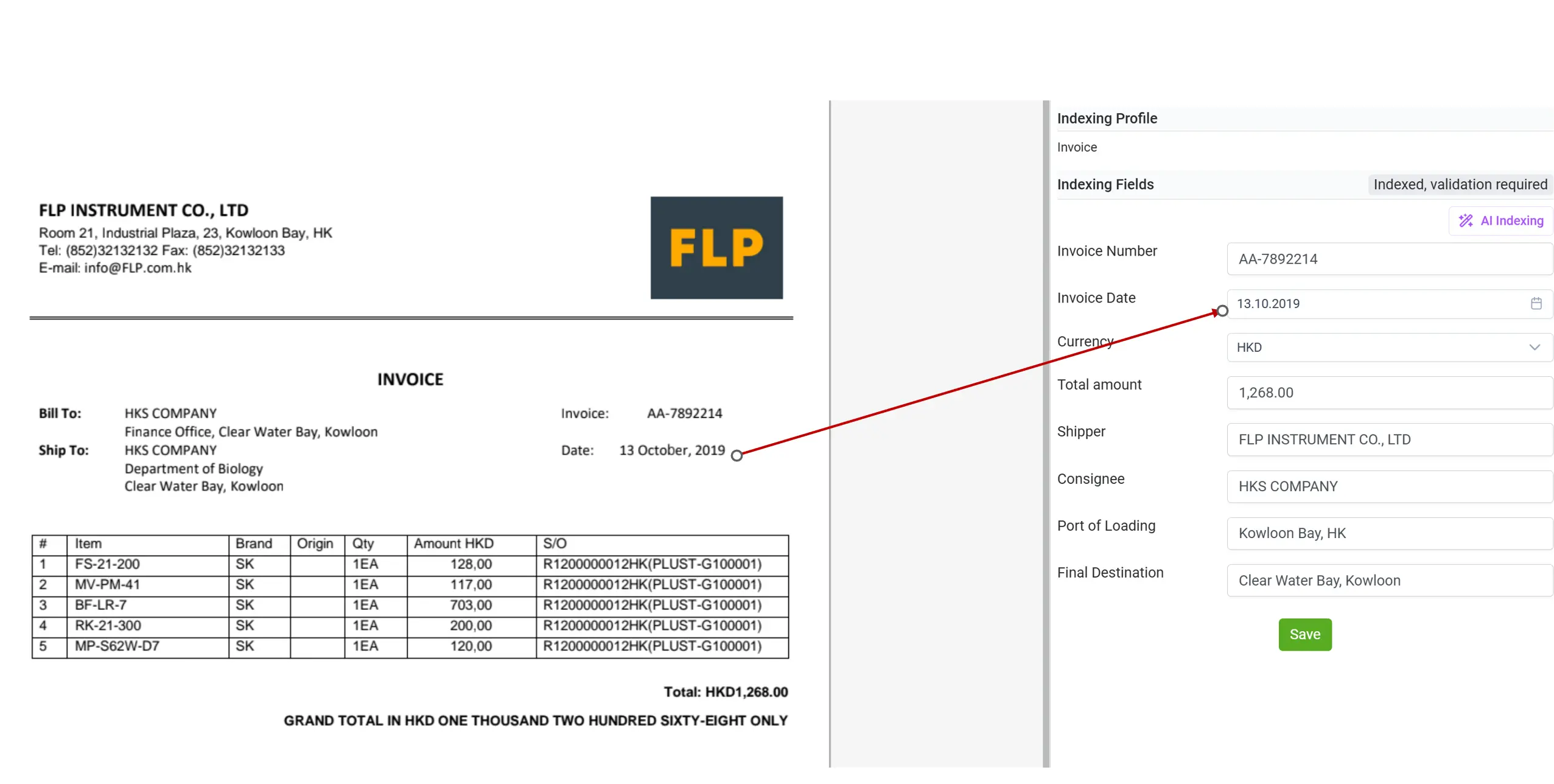
AI Data Post-Processing and Data Normalization
In the past, one of the biggest challenges in document processing was data normalization. Different document types and sources often represented the same data in inconsistent ways — for example, invoice dates written with dots, slashes, or even in words, or amounts displayed with varying currency symbols and spacing. These inconsistencies made automated processing, validation, and integration extremely difficult.
With elDoc’s AI-powered post-processing, this problem is eliminated. As elDoc performs AI indexing, it automatically recognizes, standardizes, and converts data into the required format — whether it’s transforming “10.03.2025” into “2025-03-10” or unifying currency and numeric formats across thousands of documents.
This intelligent normalization ensures that every piece of information extracted from your documents is clean, consistent, and ready for downstream use — without the need for manual corrections or additional post-processing scripts. elDoc turns messy, inconsistent data into a reliable, structured dataset your systems can trust.
Understanding Unstructured Data
With elDoc, you can now effortlessly process unstructured data such as contracts, reports, correspondence, or any multi-page document that previously required manual review. Whether your files are text-based or scanned images, elDoc automatically performs OCR to extract the raw text and visual elements.
Once the content is digitized, AI Indexing powered by LLMs analyzes and interprets the information with human-like understanding — identifying entities, relationships, and context across hundreds of pages. Even when data is written in natural language (for example, “payment due in thirty days from the invoice date”), elDoc can comprehend, interpret, and convert it into structured data such as exact dates, amounts, or terms. This advanced capability allows elDoc to read and understand documents as a human would, accurately capturing the meaning, intent, and relationships within unstructured content — and transforming it into structured, actionable insights instantly.

New Era of IDP Capabilities for Every Business Need
While LLM-powered IDP focuses on intelligent automation, there are still many practical and operational considerations that must be addressed to ensure enterprise-grade performance. elDoc is built to handle these seamlessly.
In cases where data validation is required, elDoc provides a dedicated Validation Station — an intuitive interface that allows users to review and confirm extracted data against expectations or business rules before finalizing results. This ensures maximum data accuracy and compliance, especially for critical documents such as financial statements, contracts, or regulatory filings.
Once validated, the data can be easily exported in multiple formats, such as JSON or CSV, for integration with downstream systems like ERP, CRM, or analytics platforms.
elDoc also offers full flexibility in processing workflows. Users can process documents individually, by simply prompting:
“Please extract and index data from this document,”
or handle enterprise-scale workloads, where thousands of files are uploaded in bulk for automated classification, extraction, and intelligent indexing.
This flexibility allows elDoc to fit both ad-hoc use cases and large-scale enterprise environments, adapting to the specific needs of every organization.
Consequently, elDoc opens a new era of Intelligent Document Processing — one that disrupts the limitations of legacy systems and finally delivers what businesses have always needed: speed, accuracy, adaptability, and true intelligence in every document workflow.