How to Extract Data from Invoices Using GenAI (OCR + LLM + CV + RAG) – elDoc Insight

Traditional invoice processing is slow, manual, and error-prone. Finance teams spend countless hours reading PDFs, capturing totals, checking suppliers, validating PO numbers, and entering data into ERP systems. And for decades, vendors promised they had “finally solved” invoice extraction. But the reality was very different. Most legacy solutions required one or more of the following:
- Template or layout setup for every supplier
- Continuous retraining as formats changed
- Custom development for special cases or non-standard documents
- Rigid ML/NLP models that performed well only on known layouts
- High false positives when invoices varied or quality degraded
- Frequent manual correction, making “automation” barely automated
Even the most advanced “AI OCR” tools of the past generation were still fundamentally limited — they could read text, but not understand it. They recognized characters but not meaning. They captured words but not context.
GenAI changes everything
Today, advanced AI OCR + LLM intelligence enables organizations to extract structured invoice data instantly — even from scanned, rotated, handwritten, multilingual, or poor-quality documents.
No templates.
No custom rules.
No layout configuration.
No endless model training cycles.
Just human-level understanding at superhuman speed. In this article, elDoc explains how modern Gen AI–powered invoice extraction works, which technologies make it possible, and why this new approach massively outperforms traditional OCR-only systems.
How elDoc Achieves Seamless Data Extraction From Invoices: The Full AI Stack Explained
Invoice processing in elDoc is powered by an integrated pipeline of OCR engines, computer vision modules, LLM reasoning, RAG-based contextual retrieval, semantic search, and high-performance databases. All these technologies are orchestrated to operate as a unified system, ensuring precise extraction, intelligent validation, and accurate classification across every invoice format — without templates or manual configuration.
🔤 OCR — Converting Images & PDFs Into Text
Most invoices arrive as scans, images, or non-searchable PDFs. OCR transforms them into machine-readable text so AI can actually “read” and interpret the content.
What this layer does:
- Extracts text from images and scans
- Makes PDFs searchable
- Enables downstream AI reasoning
- Handles multi-language and noisy inputs
OCR engines used by elDoc:
- Tesseract – open-source OCR for general extraction
- Google OCR API – high-accuracy cloud OCR for complex text
- Qwen3-VL – vision-language OCR with built-in layout understanding
- PaddleOCR – extremely fast, multilingual OCR for diverse formats
Depending on whether the solution is deployed on-premise or in the cloud, elDoc activates the most suitable OCR engine, all of which provide exceptional accuracy and robust text recognition performance.
🖼️ Computer Vision — Cleaning & Normalizing the Document
Before any AI model interprets an invoice, the Computer Vision layer optimizes it for accuracy.
What this layer performs:
- Deskewing & alignment of rotated pages
- Denoising & contrast enhancement
- Detection of tables, stamps, and signatures
- Page segmentation & layout recognition
- Normalization of low-quality scans
This ensures OCR delivers clean, structured text even for messy, old, or low-resolution invoices.
🧠 LLM — True Understanding of Content
The Large Language Model is the “brain” of elDoc’s intelligence layer. It reads invoices like a human — but at superhuman speed, depth, and consistency.
LLM capabilities:
- Understands meaning, context, and intent
- Recognizes document types & subtypes
- Interprets unstructured and messy text
- Extracts all key fields (totals, dates, VAT, supplier info, line items)
- Detects inconsistencies & anomalies
- Classifies documents without templates or rules
This is the breakthrough older ML/NLP systems could never achieve.
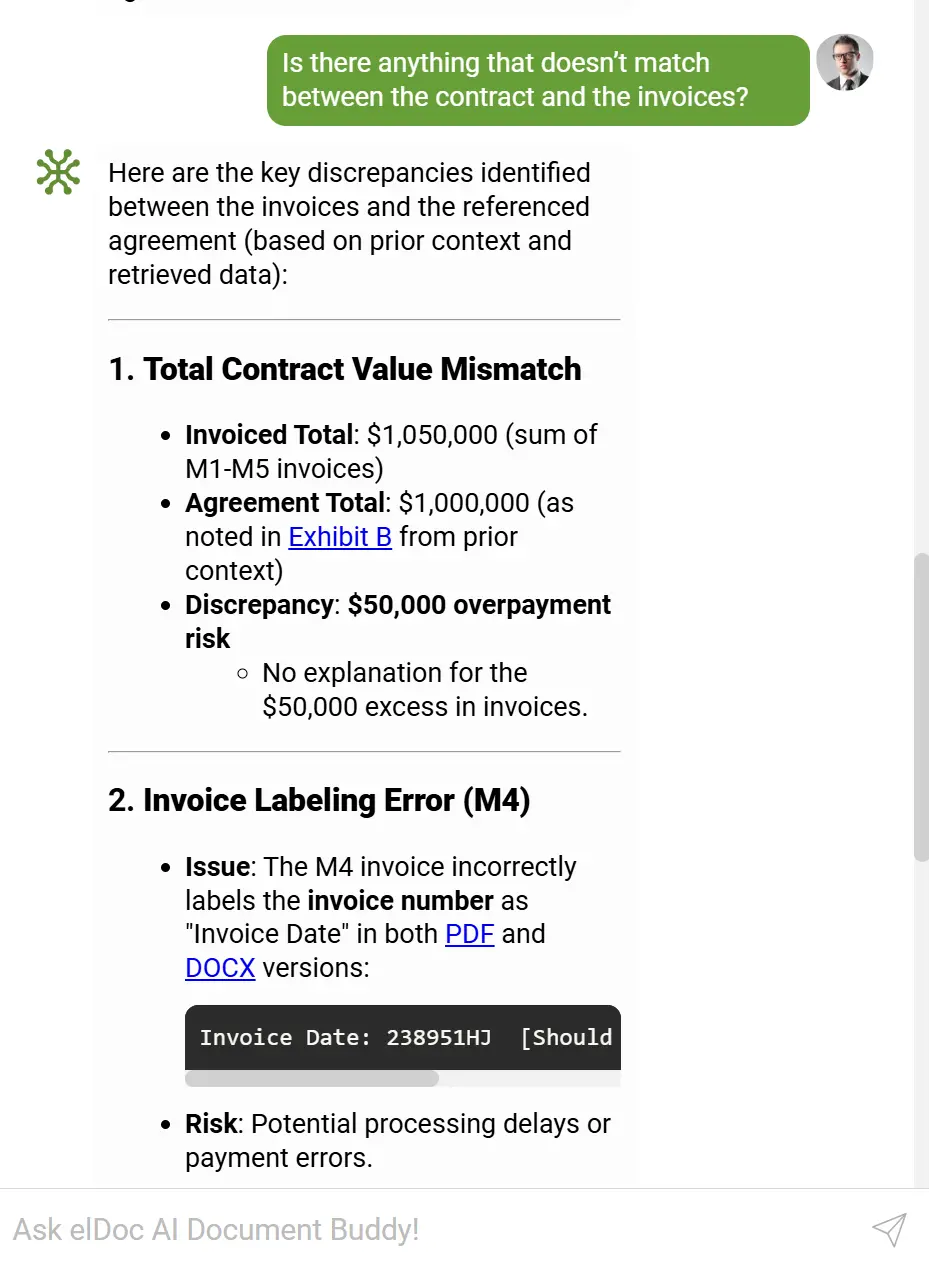
🔎 RAG — Connecting Context Across Documents
Retrieval-Augmented Generation (RAG) adds deep intelligence by connecting documents with each other.
RAG enables elDoc to:
- Find related invoices, POs, and contracts
- Perform cross-document validation
- Detect inconsistencies between documents
- Answer complex finance questions using multiple files
- Build a contextual memory of your document stack
RAG transforms your entire repository into a dynamic, interconnected knowledge base.
🔒 MongoDB — Scalable Document Storage
MongoDB serves as the primary storage engine for elDoc, handling both metadata and large files with exceptional efficiency.
Why MongoDB?
- Highly scalable for millions of invoices
- Flexible schema for unpredictable document structures
- Fast retrieval for real-time workflows
- Enterprise-grade reliability and performance
It forms the backbone of elDoc’s structured data layer.
🧭 Qdrant — Semantic Intelligence & Vector Search
Qdrant is elDoc’s vector database that gives documents true semantic understanding.
Qdrant makes elDoc able to:
- Understand content beyond keyword matches
- Find similar invoices & duplicates instantly
- Cluster related documents
- Match invoices to contracts or POs
- Support AI-powered semantic search
This is essential for intelligent validation and relationship mapping.
🔎 Apache Solr — High-Speed Full-Text Search
Solr adds enterprise-grade indexing and keyword search on top of AI and semantic layers.
Solr provides:
- Instant full-text search across millions of files
- Faceted & filtered navigation
- Advanced ranking and relevance scoring
- Massive indexing scalability
Together with Qdrant, Solr forms a hybrid search engine: keyword search + semantic search + AI reasoning.
elDoc Made GenAI for Everyone: The elDoc Community Edition
With elDoc’s Community Edition, anyone from independent professionals to small teams and mid-size companies can start using powerful GenAI-driven document automation immediately. All major components are already integrated and optimized, giving users a practical, real-world environment to explore AI OCR, LLM extraction, RAG, and semantic search without setup complexity or technical hurdles.
elDoc brings together GenAI, OCR, Computer Vision, RAG, semantic search, and high-performance data engines into one unified, intelligently coordinated pipeline. Instead of depending on a single model, static rules, or rigid templates, elDoc orchestrates each technology in the optimal sequence — starting with document cleanup, moving through text recognition, and ending with deep semantic understanding and validation and data storage and export. Every layer contributes a specific capability: OCR reads the content, Computer Vision normalize the document, LLMs understand meaning, and RAG connects context across your entire document library. Combined, this holistic architecture delivers truly reliable, template-free invoice extraction that works consistently across any document format, language, layout, or scan quality — even in the most complex real-world conditions.