Архітектура Agentic RAG в elDoc для інтелектуального аналізу корпоративних документів

Для корпоративних організацій недостатньо ШІ, який лише веде діалоги. Їм потрібен ШІ, здатний розуміти завдання, здійснювати пошук у документах і даних, поєднувати інформацію з різних джерел, аналізувати знайдене та допомагати виконувати реальні робочі задачі в безпечному середовищі. Саме тут ключову роль відіграє Agentic RAG.
Agentic RAG в elDoc — це не просто пошук кількох релевантних фрагментів тексту з подальшим їх узагальненням мовною моделлю. Це оркестрація повноцінного AI-процесу, в якому взаємодіють різні технології: зберігання документів, екстракція тексту, пошук за ключовими словами, векторний пошук, моделі логічного аналізу та AI-агенти, здатні планувати й виконувати багатоетапні завдання. Така комбінація дозволяє elDoc перейти від пасивного доступу до документів до активного, орієнтованого на завдання інтелектуальної обробки корпоративного контенту.
Що означає Agentic RAG на практиці
Традиційний пошук документів допомагає користувачам знаходити файли. Базовий AI-чат дозволяє ставити запитання. Базовий RAG покращує відповіді, спираючись на знайдений контент.
Agentic RAG іде на крок далі: він дозволяє системі інтерпретувати запит користувача, визначати спосіб його вирішення, виконувати кілька етапів пошуку та аналізу, перевіряти знайдену інформацію та формувати корисний фінальний результат. Замість одного кроку «пошук і відповідь» система працює за логікою, близькою до підходу досвідченого аналітика:
Спочатку вона розуміє запит, визначає, яка інформація потрібна, встановлює, де її можна знайти, отримує релевантні дані, аналізує їх, перевіряє достатність інформації, за потреби виконує додаткові пошуки, а потім формує остаточну відповідь, резюме, звіт або результат, готовий до використання.
Це і є основа роботи Agentic RAG в elDoc.
Процес обробки даних elDoc AI
Ефективність Agentic RAG в elDoc полягає в узгодженій роботі кількох спеціалізованих компонентів як єдиної системи. Кожен компонент виконує свою роль, а цінність виникає завдяки їх взаємодоповнюваності.
MongoDB: зберігання документів
Основою системи є MongoDB, яка виконує роль шару зберігання документів. Корпоративні середовища документів рідко бувають простими. Документи можуть мати різні формати, походити з різних підрозділів, відрізнятися структурою, метаданими, етапами життєвого циклу та рівнями доступу. Для управління такою складною системою потрібен гнучкий і масштабований рівень зберігання.
MongoDB задовольняє цю потребу, надаючи структуру, яка дозволяє зберігати не лише сам документ, а й супутній контекст, необхідний для ефективної роботи AI-процесів. Це може включати метадані, такі як тип документа, підрозділ, автор, дата, версія, прив’язка до бізнес-процесу, права доступу, витягнутий текст, структура фрагментів, інформація про індексацію та посилання на пов’язані записи.
Це важливо, оскільки Agentic RAG працює не лише із «сирим» текстом, а й із контекстом. Наприклад, коли користувач запитує про прогалини в політиках, невідповідності вимогам, договірні зобов’язання або ризики процесів, системі потрібно знати не тільки зміст документа, а й те, яка його версія є актуальною, який підрозділ за нього відповідає, чи погоджений файл і як він пов’язаний з іншими матеріалами.
MongoDB забезпечує основу структурованих і напівструктурованих даних, що робить можливими такі розширені сценарії роботи.
Apache Solr: повнотекстовий пошук
Не всі завдання підприємства можна вирішити лише за допомогою векторного пошуку. У багатьох реальних бізнес-сценаріях вирішальне значення мають точні терміни, назви, коди, посилання, дати, ідентифікатори, юридичні формулювання або галузева термінологія. Саме тому Apache Solr відіграє ключову роль у роботі elDoc.
Solr забезпечує потужні можливості повнотекстового пошуку, що дозволяють знаходити документи та їх фрагменти за релевантністю ключових слів, точним збігом фраз, фільтрацією, фасетною навігацією, обмеженнями за метаданими та логікою ранжування. Це особливо важливо в корпоративних сценаріях, де користувачі можуть шукати:
- номери договорів
- ідентифікатори рахунків
- коди проєктів
- імена співробітників
- положення політик
- юридичні положення
- технічну термінологію
- специфічну лексику підрозділів
Наприклад, якщо користувач шукає всі згадки про конкретного постачальника, номер політики або регуляторну вимогу, повнотекстовий пошук може виявитися найшвидшим і найнадійнішим способом отримання результату. Solr допомагає системі точно знаходити такі явні згадки. У контексті Agentic RAG це особливо важливо, оскільки агент може визначити, чи краще використовувати точний пошук за ключовими словами, семантичний пошук або їх поєднання. Таким чином Solr стає одним із ключових інструментів, який допомагає агенту працювати з максимально релевантним контентом.
Qdrant: векторний пошук
Хоча повнотекстовий пошук ідеально підходить для точних збігів, користувачі в корпоративному середовищі часто формулюють запити природною мовою, які не збігаються буквально з формулюваннями в документах. Саме тут стає незамінним Qdrant як шар векторного пошуку. Векторний пошук дозволяє elDoc знаходити інформацію на основі семантичної подібності, а не лише точного збігу слів. Це означає, що система може виявляти релевантний контент навіть тоді, коли формулювання в документі відрізняється від формулювання запиту користувача.
Наприклад, користувач може запитати:
- «Які основні ризики постачання передбачені в цьому договорі?»
- «Чи є приховані зобов’язання для постачальника?»
- «Покажи, де відповідальність визначена нечітко».
- «У яких політиках описані ліміти погодження?»
Відповідні документи можуть не містити саме таких формулювань. Натомість у них можуть використовуватися подібні поняття, такі як зобов’язання щодо надання послуг, положення про відповідальність, ескалація відповідальності, делегування повноважень або вимоги до погодження винятків. Пошук лише за ключовими словами може пропустити важливу інформацію. Векторний пошук допомагає відтворити цей контекст.
Qdrant у elDoc забезпечує глибший семантичний пошук у масивах корпоративних документів. Це дозволяє системі знаходити змістовно пов’язані фрагменти та розширювати набір даних, які аналізує агент.
Це особливо корисно в складних сценаріях, таких як:
- міждокументний аналіз
- аналіз політик і перевірка відповідності
- інтелектуальний аналіз договорів
- виявлення операційних ризиків
- комплексна перевірка (due diligence)
- виявлення нової інформації
- корпоративні Q&A-сценарії для різнорідного контенту
Механізми OCR: вилучення тексту
Перш ніж документи можна буде шукати, аналізувати чи використовувати для логічного опрацювання, їхній текст має стати придатним для машинного зчитування. У корпоративному середовищі це не завжди просто. Багато важливих документів зберігаються у вигляді сканованих PDF-файлів, зображень, підписаних форм, паперових архівів або експортованих документів із поганою структурою тексту. Без вилучення тексту такі файли залишаються «невидимими» для ШІ.
Саме тому механізми OCR є критично важливою частиною AI-пайплайна elDoc.
OCR (Optical Character Recognition) дозволяє elDoc витягувати текст зі сканованих або графічних документів, щоб цей контент можна було індексувати, розбивати на фрагменти, шукати та використовувати в подальших AI-процесах. Цей етап значно важливіший, ніж може здатися. Якість вилучення тексту безпосередньо впливає на якість пошуку, аналізу та фінальних результатів. Якщо текст неповний, пошкоджений, неправильно розпізнаний або некоректно сегментований, подальші AI-процеси працюватимуть із менш надійною базою даних.
На практиці OCR дозволяє elDoc розширити охоплення ШІ на реальні корпоративні архіви, а не обмежуватися лише цифровими файлами. Це дає змогу інтегрувати архівні записи, паперові процеси, підписані документи, застарілі скани та операційні вкладення в єдиний шар знань, доступний для ведення пошуку й аналізу.
Це означає повніший пошук, кращий контекст і більшу користь для бізнесу.
LLM-моделі: аналіз і генерація
Після того як відповідна інформація знайдена, наступним кроком є не просто її відтворення. Система має інтерпретувати, порівнювати, узагальнювати, пояснювати та формувати корисну відповідь. Саме це і є завданням рівня LLM. Великі мовні моделі в elDoc використовуються для аналізу та генерації, допомагаючи перетворювати знайдені дані на результати, зрозумілі та придатні до використання користувачами.
Залежно від завдання це може включати:
- надання відповіді на основі знайдених документів
- узагальнення інформації з кількох джерел
- виявлення невідповідностей або відсутньої інформації
- порівняння положень, політик або версій документів
- витяг зобов’язань, ризиків, дат або зон відповідальності
- підготовка звітів або структурованих результатів
- пояснення результатів простою, зрозумілою мовою
Ключовим моментом є те, що модель не працює ізольовано. У підході Agentic RAG LLM спирається на знайдений контент і стає частиною ширшого процесу, яким керує агент.
Це важливо, оскільки корпоративним користувачам не потрібна узагальнена генерація тексту. Їм потрібні надійні результати на основі авторизованого та релевантного контенту. LLM забезпечує інтерпретацію та мовні можливості, тоді як рівні пошуку та агентів гарантують, що процес аналізу ґрунтується на перевірених даних.
AI-агенти: планування та виконання завдань
Ключовим рівнем у Agentic RAG є AI-агент. Агент не просто відповідає на окремий запит. Він працює скоріше як інтелектуальний координатор: інтерпретує ціль користувача, визначає необхідні кроки, обирає відповідні інструменти, оцінює проміжні результати та вирішує, чи потрібні додатковий пошук або аналіз, перш ніж сформувати остаточну відповідь.
Саме це перетворює стандартну RAG-систему на Agentic RAG.
У elDoc агент може координувати кілька етапів роботи, зокрема:
- розуміння наміру користувача
- вибір стратегії пошуку
- поєднання пошуку за ключовими словами та семантичного пошуку
- перевірка достатності знайдених даних
- ініціювання додаткових пошуків у разі виявлення прогалин
- агрегування результатів із різних документів
- структуризація результату відповідно до завдання
Замість одноразової взаємодії система перетворюється на керований механізм виконання завдань, пов’язаних зі знаннями.
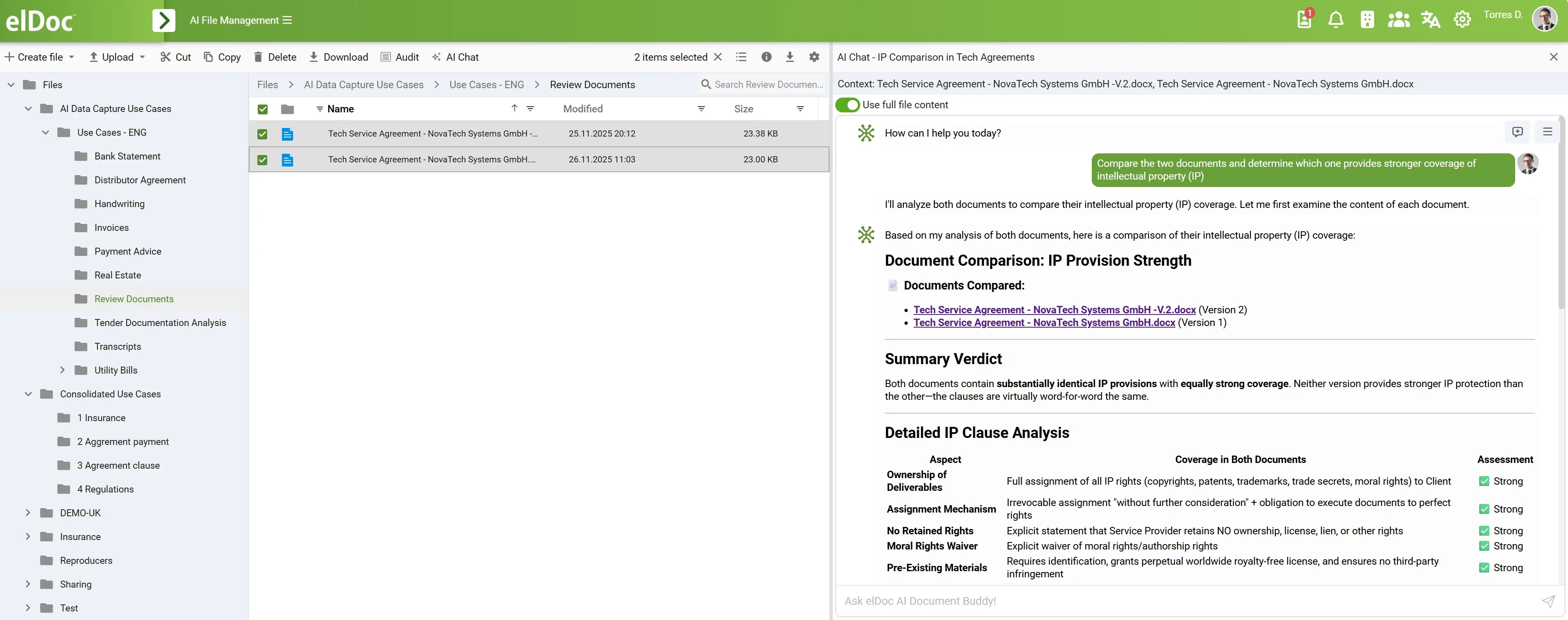
Це особливо важливо для корпоративних сценаріїв, де запити рідко бувають простими. Користувач може попросити виявити ризики процесу, порівняти версії договорів, знайти суперечливі політики, проаналізувати досьє постачальника, визначити відсутні погодження або узагальнити дані для управлінського звіту. Такі завдання потребують планування, ітерацій і контекстного аналізу. Саме агент робить це можливим.
Чому багатоетапний аналіз робить Agentic RAG таким потужним
Справжня сила Agentic RAG полягає в багатоетапному аналізі.
Багато корпоративних завдань неможливо надійно вирішити за допомогою одного запиту та одного етапу пошуку. Важлива інформація може бути розпорошена в різних документах. Ключові ризики можуть бути неявними, а критичні дані можуть стати релевантними лише після того, як початкові висновки вкажуть на інше джерело.
Багатоетапний аналіз дозволяє elDoc динамічно підходити до вирішення завдань. Замість того щоб вважати перші знайдені фрагменти достатніми, система може послідовно опрацьовувати задачу, збирати дані поетапно, уточнювати пошук і формувати більш повну відповідь. Це робить її значно ефективнішою для складних інтелектуальних завдань, таких як:
- аналіз відповідності
- аналіз договорів
- підтримка аудиту
- узгодження політик
- комплексна перевірка (due diligence)
- аналіз процесів
- виявлення корпоративних знань
- розслідування на основі документів
Іншими словами, Agentic RAG є потужним інструментом, оскільки дозволяє ШІ діяти не як статичний чат-бот, а як інтелектуальний асистент, здатний послідовно працювати над вирішенням задачі.
Agentic RAG має забезпечувати як ефективність, так і безпеку — в elDoc це закладено на рівні архітектури
Хоча багатокроковий аналіз і робить Agentic RAG потужним інструментом, він також висуває критично важливу вимогу: безпека на кожному етапі процесу.
У elDoc Agentic RAG розроблено не лише для розуміння, пошуку та аналізу на основі корпоративних документів, а й для виконання цих дій виключно в контрольованому та безпечному середовищі.
Кожного разу, коли користувач надсилає запит, система не просто запускає пошук. Спочатку elDoc перевіряє, хто є користувач і до яких даних він має доступ. Це гарантує, що всі подальші дії — пошук, аналіз і генерація відповіді — повністю відповідають корпоративним політикам доступу.
В основі цього підходу лежить рольова модель контролю доступу (RBAC), яка визначає, які дані кожен користувач може переглядати та обробляти. AI-агенти в elDoc наслідують ці дозволи та працюють виключно в їхніх межах. Вони не можуть знаходити, аналізувати чи генерувати результати на основі інформації, до якої користувач не має доступу.
Це означає, що:
- кожен запит враховує права доступу
- кожен пошук контролюється відповідно до доступів
- кожна відповідь базується лише на авторизованому контенті
Однак безпека в elDoc виходить далеко за межі RBAC.
Платформа реалізує багаторівневу модель корпоративної безпеки, що забезпечує захист на рівні ідентифікації, даних, інфраструктури та операцій:
- Безпека ідентифікації та доступу: багатофакторна автентифікація (MFA), одноразові паролі (OTP) та інтеграція з корпоративними системами ідентифікації гарантують, що доступ до платформи мають лише підтверджені користувачі
- Гранулярні дозволи та контроль: детальні політики доступу на рівні документів і даних із суворим дотриманням під час кожної взаємодії з ШІ
- Моніторинг, ведення логів та можливість аудиту: повна простежуваність дій користувачів, що забезпечує прозорість, відповідність вимогам і контроль
- Безпечні варіанти розгортання: підтримка локальних, приватних хмарних або гібридних середовищ, що забезпечує повний контроль над зберіганням і обробкою даних
- Ізольовані середовища: можливість розгортання elDoc в повністю ізольованій інфраструктурі, що є критично важливим для організацій, які працюють із чутливими або конфіденційними даними
- Висока доступність і відновлення після збоїв: надійність корпоративного рівня завдяки відмовостійкій архітектурі, що забезпечує безперервність операцій на основі штучного інтелекту
Такий багаторівневий підхід гарантує, що зі зростанням можливостей ШІ завдяки багатоетапному аналізу не виникають додаткові ризики.
ШІ в elDoc не обходить заходи безпеки, а забезпечує їх дотримання.
Від моменту постановки запиту до фінального результату кожен етап процесу Agentic RAG постійно перевіряється на відповідність корпоративним політикам. Це гарантує, що організації можуть ефективно використовувати передові можливості ШІ у роботі з документами та даними, зберігаючи при цьому повний контроль, відповідність вимогам і захист.