La arquitectura de Agentic RAG en elDoc para la inteligencia documental empresarial

Las organizaciones empresariales no necesitan una IA que solo converse. Necesitan una IA que pueda comprender una tarea, buscar en documentos y datos, conectar información de diferentes fuentes, razonar sobre lo que encuentra y ayudar a completar trabajo real en un entorno seguro. Ahí es donde Agentic RAG se vuelve fundamental.
En elDoc, Agentic RAG no se trata solo de recuperar algunos fragmentos de texto relevantes y pedirle a un modelo de lenguaje que los resuma. Se trata de orquestar un flujo completo de IA en el que múltiples tecnologías trabajan juntas: almacenamiento de documentos, extracción de texto, búsqueda por palabras clave, búsqueda vectorial, modelos de razonamiento y agentes de IA capaces de planificar y ejecutar tareas de múltiples pasos. Esta combinación permite a elDoc ir más allá del acceso pasivo a documentos y avanzar hacia una inteligencia activa y orientada a tareas para el contenido empresarial.
Qué significa Agentic RAG en la práctica
La búsqueda documental tradicional ayuda a los usuarios a encontrar archivos. El chat básico con IA ayuda a los usuarios a hacer preguntas. El RAG básico mejora las respuestas al fundamentarlas en contenido recuperado.
Agentic RAG va un paso más allá: permite al sistema interpretar la solicitud del usuario, decidir cómo resolverla, realizar múltiples pasos de recuperación y razonamiento, validar lo que encuentra y construir un resultado final útil. En lugar de depender de un único paso de búsqueda y respuesta, el sistema puede seguir un proceso más cercano a cómo trabaja un analista experto:
Primero comprende la solicitud, determina qué información se necesita, identifica dónde es probable encontrarla, recupera la evidencia relevante, la analiza, verifica si es suficiente, realiza búsquedas adicionales cuando es necesario y, finalmente, genera una respuesta final, un resumen, un informe o un resultado listo para la acción.
Este es el núcleo de cómo funciona Agentic RAG en elDoc.
El pipeline de IA de elDoc
El poder de Agentic RAG en elDoc proviene de la forma en que varios componentes especializados trabajan juntos como un sistema coordinado. Cada componente tiene un rol distinto, y el valor surge de cómo se complementan entre sí.
MongoDB: almacenamiento de documentos
En la base del pipeline se encuentra MongoDB, que actúa como la capa de almacenamiento de documentos. Los entornos documentales empresariales rara vez son simples. Los documentos pueden provenir de diferentes formatos, departamentos y estructuras, con distintos campos de metadatos, estados del ciclo de vida y clasificaciones de seguridad. Una capa de almacenamiento flexible y escalable es esencial para gestionar esta complejidad.
MongoDB responde a esta necesidad proporcionando una estructura que permite almacenar no solo el documento en sí, sino también el contexto que lo hace útil para los flujos de trabajo de IA. Esto puede incluir metadatos como tipo de documento, departamento, autor, fecha, versión, referencia a procesos de negocio, controles de acceso, texto extraído, estructura de fragmentos, información de indexación y enlaces a registros relacionados.
Esto es importante porque Agentic RAG no opera únicamente sobre texto en bruto. También necesita contexto. Por ejemplo, cuando un usuario solicita identificar brechas en políticas, inconsistencias de cumplimiento, obligaciones contractuales o riesgos de procesos, el sistema puede necesitar saber no solo qué dice el texto, sino también qué versión del documento es la vigente, qué departamento es responsable, si el archivo está aprobado y cómo se relaciona con otros contenidos.
MongoDB proporciona la base de datos estructurados y semiestructurados que hace posibles estos flujos de trabajo más avanzados.
Apache Solr: búsqueda de texto completo
No todas las preguntas empresariales deben resolverse únicamente con búsqueda vectorial. En muchos escenarios reales, los términos exactos, nombres, códigos, referencias, fechas, identificadores, frases legales o terminología específica del dominio son fundamentales. Por eso Apache Solr desempeña un papel clave en el pipeline de elDoc.
Solr ofrece potentes capacidades de búsqueda de texto completo que permiten localizar documentos y fragmentos utilizando relevancia por palabras clave, coincidencia exacta de frases, filtrado, facetado, restricciones de metadatos y lógica de ranking. Esto es especialmente valioso en contextos empresariales donde los usuarios pueden buscar:
- números de contrato
- identificadores de facturas
- códigos de proyecto
- nombres de empleados
- términos de políticas
- cláusulas legales
- terminología técnica
- lenguaje específico de cada departamento
Por ejemplo, si un usuario solicita todas las referencias a un proveedor específico, un número de política o un requisito regulatorio, la búsqueda de texto completo puede ser el método más rápido y fiable. Solr ayuda al sistema a encontrar estas referencias explícitas con precisión. En Agentic RAG, esto es clave porque el agente puede decidir si la solicitud del usuario se resuelve mejor mediante recuperación por palabras clave, recuperación semántica o una combinación de ambas. Solr se convierte en una de las herramientas principales que el agente utiliza para fundamentar su trabajo en contenido altamente relevante.
Qdrant: búsqueda vectorial
Si bien la búsqueda de texto completo es excelente para coincidencias exactas, los usuarios empresariales suelen formular preguntas en lenguaje natural que no coinciden exactamente con el contenido almacenado en los documentos. Aquí es donde Qdrant, la capa de búsqueda vectorial, se vuelve esencial. La búsqueda vectorial permite a elDoc recuperar información basada en similitud semántica, no solo en coincidencias exactas de palabras. Esto significa que el sistema puede encontrar contenido relevante incluso cuando la redacción del documento difiere de la de la pregunta del usuario.
Por ejemplo, un usuario podría preguntar:
- «¿Cuáles son los principales riesgos de entrega en este contrato?»
- «¿Existen obligaciones ocultas para el proveedor?»
- «Muéstrame dónde las responsabilidades no están claras».
- «¿Qué políticas describen los límites de aprobación?»
Es posible que los documentos relevantes no utilicen exactamente estas frases. En su lugar, pueden contener términos relacionados como compromisos de servicio, cláusulas de responsabilidad, responsabilidades de escalamiento, autoridad delegada o requisitos de aprobación de excepciones. Una búsqueda basada únicamente en palabras clave podría pasar por alto información importante. La búsqueda vectorial ayuda a recuperar ese contexto.
En elDoc, Qdrant permite una recuperación semántica más profunda a través de fragmentos de documentos empresariales. Esto permite al sistema identificar pasajes significativamente relacionados y enriquecer el conjunto de evidencias que el agente analiza.
Esto es especialmente útil en casos de uso complejos como:
- análisis entre documentos
- revisión de políticas y cumplimiento
- inteligencia de contratos
- identificación de riesgos operativos
- debida diligencia
- descubrimiento de conocimiento
- preguntas y respuestas empresariales sobre contenido diverso
Motores OCR: extracción de texto
Antes de que los documentos puedan ser buscados, analizados o procesados mediante razonamiento, su contenido debe convertirse en texto legible por máquina. En entornos empresariales, esto no siempre es sencillo. Muchos documentos importantes se almacenan como PDF escaneados, archivos basados en imágenes, formularios firmados, archivos en papel o exportaciones con una estructura de texto deficiente. Sin extracción, estos archivos permanecen invisibles para la IA.
Por eso, los motores OCR son una parte fundamental del pipeline de IA de elDoc.
El OCR, o reconocimiento óptico de caracteres, permite a elDoc extraer texto de documentos escaneados o basados en imágenes para que el contenido pueda ser indexado, fragmentado, buscado y utilizado en los flujos de trabajo de IA posteriores. Este paso es mucho más importante de lo que parece. La calidad de la extracción de texto afecta directamente la calidad de la recuperación, el razonamiento y los resultados finales. Si el texto está incompleto, fragmentado, mal interpretado o mal segmentado, la IA tendrá evidencia más débil para trabajar.
En la práctica, el OCR permite a elDoc ampliar la cobertura de la IA sobre archivos empresariales reales, en lugar de limitar la inteligencia únicamente a archivos digitales. Ayuda a integrar registros históricos, flujos de trabajo en papel, documentos firmados, escaneos heredados y anexos operativos en una misma capa de conocimiento que puede ser buscada y analizada.
Esto se traduce en una recuperación más completa, mejor contexto y mayor valor para el negocio.
Modelos LLM: razonamiento y generación
Una vez que se ha encontrado la información relevante, el siguiente paso no es simplemente repetirla. El sistema debe interpretarla, compararla, sintetizarla, explicarla y generar una respuesta útil. Este es el rol de la capa LLM. Los modelos de lenguaje de gran escala en elDoc se utilizan para el razonamiento y la generación. Ayudan a transformar la evidencia recuperada en resultados comprensibles y accionables para ti.
Según la tarea, esto puede incluir:
- responder una pregunta basada en documentos recuperados
- resumir hallazgos a través de múltiples fuentes
- identificar inconsistencias o información faltante
- comparar cláusulas, políticas o versiones
- extraer obligaciones, riesgos, fechas o responsabilidades
- redactar un informe o un resultado estructurado
- explicar los resultados en lenguaje claro
El punto clave es que el modelo no opera de forma aislada. En Agentic RAG, el LLM se basa en el contenido recuperado y forma parte de un flujo de trabajo más amplio controlado por el agente.
Esto es importante porque los usuarios empresariales no necesitan generación de texto genérica. Necesitan resultados confiables basados en contenido autorizado y relevante. El LLM aporta capacidad de interpretación y lenguaje, mientras que las capas de recuperación y de agentes garantizan que el proceso de razonamiento esté fundamentado en evidencia.
Agentes de IA: planificación y ejecución de tareas
La capa que define Agentic RAG es el agente de IA. Un agente no se limita a responder a partir de un solo prompt. Funciona más como un coordinador inteligente. Interpreta tu objetivo, determina qué pasos son necesarios, selecciona las herramientas adecuadas, evalúa los resultados intermedios y decide si se requiere recuperación o análisis adicional antes de generar la respuesta final.
Esto es lo que transforma un sistema RAG estándar en un sistema Agentic RAG.
En elDoc, el agente puede orquestar múltiples etapas de trabajo, como:
- comprender la intención del usuario
- seleccionar estrategias de búsqueda
- combinar recuperación por palabras clave y recuperación semántica
- validar si la evidencia recuperada es suficiente
- activar búsquedas adicionales si persisten brechas
- agregar hallazgos entre documentos
- estructurar el resultado de acuerdo con la tarea
En lugar de una interacción de un solo paso, el sistema se convierte en un motor de flujos de trabajo guiados para tareas de conocimiento.
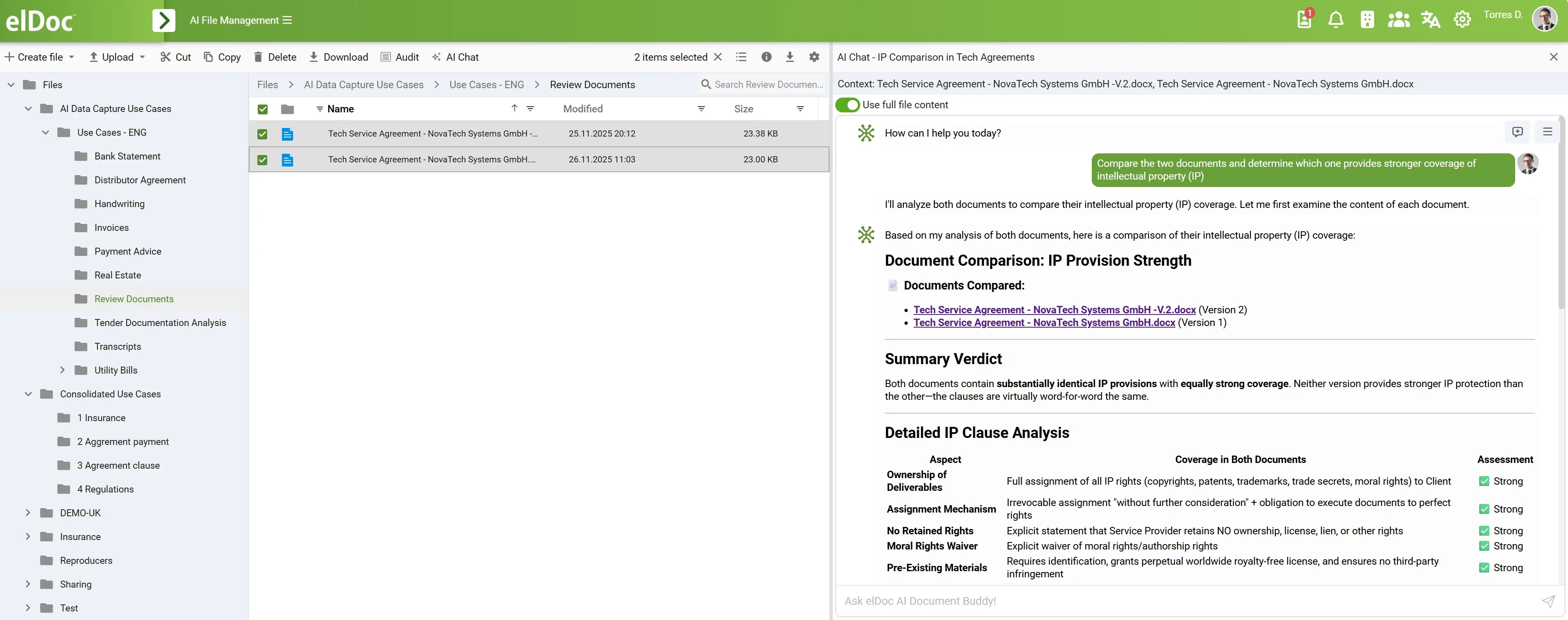
Esto es especialmente potente en casos de uso empresariales, donde las solicitudes rara vez son simples. Puedes necesitar identificar riesgos de procesos, comparar versiones de contratos, encontrar políticas en conflicto, analizar archivos de proveedores, detectar aprobaciones faltantes o resumir evidencia para un informe de gestión. Estas tareas requieren planificación, iteración y razonamiento contextual. El agente es lo que hace esto posible.
Por qué el razonamiento de múltiples pasos hace que Agentic RAG sea poderoso
La verdadera fortaleza de Agentic RAG radica en el razonamiento de múltiples pasos.
Muchas tareas empresariales no pueden resolverse de manera fiable con un solo prompt y un único paso de recuperación. La información importante puede estar dispersa en múltiples documentos. Los riesgos clave pueden estar implícitos en lugar de expresarse de forma explícita. La evidencia crítica puede volverse relevante solo después de que los primeros hallazgos apunten a otra fuente.
El razonamiento de múltiples pasos permite a elDoc abordar el problema de forma dinámica. En lugar de asumir que los primeros fragmentos recuperados son suficientes, el sistema puede analizar la tarea, recopilar evidencia por etapas, refinar su búsqueda y construir una respuesta más completa. Esto lo hace mucho más adecuado para trabajos de conocimiento complejos, como:
- análisis de cumplimiento
- revisión de contratos
- soporte de auditoría
- alineación de políticas
- debida diligencia
- análisis de procesos
- descubrimiento de conocimiento empresarial
- investigación basada en documentos
En otras palabras, Agentic RAG es poderoso porque permite que la IA se comporte menos como un chatbot estático y más como un asistente inteligente capaz de resolver problemas.
Agentic RAG debe ofrecer tanto eficiencia como seguridad; en elDoc, esto está integrado en la arquitectura
Si bien el razonamiento de múltiples pasos es lo que hace poderoso a Agentic RAG, también introduce un requisito crítico: seguridad en cada etapa del flujo de trabajo.
En elDoc, Agentic RAG está diseñado no solo para comprender, recuperar y razonar sobre documentos empresariales, sino para hacerlo estrictamente dentro de un entorno controlado y seguro.
Cada vez que envías una solicitud, el sistema no comienza a buscar de inmediato. Primero, elDoc verifica quién eres y a qué tienes permitido acceder. Esto garantiza que todas las acciones posteriores, como la recuperación, el análisis y la generación de respuestas, estén completamente alineadas con las políticas de acceso de la organización.
En el núcleo de este enfoque se encuentra el control de acceso basado en roles (RBAC), que define qué datos puede ver y utilizar cada usuario. Los agentes de IA en elDoc heredan estos permisos y operan estrictamente dentro de ellos. No pueden recuperar, analizar ni generar resultados basados en información a la que no estás autorizado a acceder.
Esto significa que:
- cada consulta tiene en cuenta los permisos
- cada recuperación está controlada por acceso
- cada respuesta se basa únicamente en contenido autorizado
Sin embargo, la seguridad en elDoc va mucho más allá del RBAC.
La plataforma incorpora un modelo de seguridad empresarial de múltiples capas que garantiza protección en identidad, datos, infraestructura y operaciones:
- Seguridad de identidad y acceso: la autenticación multifactor (MFA), las contraseñas de un solo uso (OTP) y la integración con sistemas de identidad empresarial garantizan que solo usuarios verificados puedan acceder a la plataforma
- Permisos y controles granulares: políticas de acceso detalladas hasta el nivel de documento y datos, con aplicación estricta en cada interacción con la IA
- Monitoreo, registro y auditabilidad: trazabilidad completa de las acciones del usuario, lo que permite transparencia, cumplimiento y gobernanza
- Opciones de despliegue seguro: soporte para entornos on-premise, nube privada o híbridos, lo que garantiza control total sobre dónde se almacenan y procesan los datos
- Entornos aislados: capacidad de ejecutar elDoc en infraestructuras completamente aisladas, lo cual es fundamental para organizaciones que manejan datos sensibles o confidenciales
- Alta disponibilidad y recuperación ante desastres: confiabilidad de nivel empresarial con una arquitectura resiliente que garantiza la continuidad de las operaciones impulsadas por IA
Este enfoque por capas garantiza que, a medida que la IA se vuelve más capaz mediante el razonamiento de múltiples pasos, no introduce riesgos adicionales.
En elDoc, la IA no elude la seguridad; la refuerza.
Desde el momento en que realizas una consulta hasta el resultado final generado, cada paso del flujo de trabajo de Agentic RAG se valida continuamente frente a las políticas empresariales. Esto garantiza que las organizaciones puedan aprovechar la IA avanzada en sus documentos y datos manteniendo el control total, el cumplimiento y la protección.