Ekstrakcja danych z wykorzystaniem LLM: dostępna on-premise lub w chmurze

Od ponad dekady ekstrakcja danych pozostaje najbardziej pożądaną funkcjonalnością w rozwiązaniach Intelligent Document Processing (IDP). Na rynku pojawiło się wielu dostawców, z których każdy obiecywał automatyzację opartą na AI, zdolną do wyodrębniania kluczowych danych z dokumentów. Jednak większość z nich nie spełniła obietnicy prawdziwie inteligentnej automatyzacji. Systemy nadal wymagały niekończących się konfiguracji szablonów, ręcznego trenowania oraz sztywnych ustawień dla każdego nowego typu dokumentu, od faktur i umów po wyciągi i formularze.
Nowoczesne przedsiębiorstwa potrzebują czegoś więcej niż tradycyjnego OCR czy silników opartych na regułach, potrzebują prawdziwego zrozumienia treści. Wraz z pojawieniem się Large Language Models (LLM) ekstrakcja danych wkroczyła w nową erę. LLM potrafią czytać, interpretować i wyodrębniać ustrukturyzowane informacje z praktycznie każdego dokumentu, bez kruchych szablonów, wstępnego trenowania czy ręcznej konfiguracji. Niezależnie od tego, czy chodzi o faktury, umowy, wyciągi bankowe, polisy czy rozbudowaną korespondencję, modele LLM rozumieją kontekst, zależności oraz znaczenie danych.
Dla wielu organizacji, szczególnie w branżach regulowanych i środowiskach korporacyjnych, prywatność danych oraz pełna kontrola nie podlegają negocjacjom. Zespoły chcą korzystać z mocy LLM i AI, lecz w ramach własnej infrastruktury i pod pełnym nadzorem organizacji. Właśnie tutaj pojawia się elDoc. elDoc dostarcza pełną moc ekstrakcji danych opartej na LLM, zapewniając swobodę wdrożenia w modelu w 100% on-premise lub bezpiecznie w chmurze, z zachowaniem tej samej inteligencji, wydajności i możliwości automatyzacji. W tym artykule wyjaśniamy, jak działa ekstrakcja oparta na LLM, czym różni się od tradycyjnych rozwiązań IDP oraz jak wdrożyć ją w sposób bezpieczny, niezależnie od tego, czy w modelu on-premise, chmurowym czy hybrydowym.
Dlaczego ekstrakcja oparta na LLM?
W elDoc kierujemy się innowacyjnością oraz misją wprowadzania najbardziej zaawansowanych technologii do realnej automatyzacji procesów biznesowych. Wraz z pojawieniem się Large Language Models stało się jasne, że modele te mogą całkowicie zmienić sposób ekstrakcji i rozumienia danych. Tradycyjne systemy OCR i rozwiązania oparte na regułach potrafiły odczytywać znaki, lecz nie rozumiały kontekstu. LLM natomiast czytają, analizują i rozumieją treść, otwierając nową erę prawdziwie inteligentnego rozumienia dokumentów.
W przeciwieństwie do systemów legacy, które opierają się na sztywnych szablonach i długotrwałych cyklach konfiguracji, ekstrakcja oparta na LLM w elDoc działa natychmiastowo w przypadku szerokiej gamy typów dokumentów, nawet gdy zmienia się układ, język lub format. Rozwiązanie dynamicznie dostosowuje się do każdego dokumentu, rozumiejąc intencję, zależności oraz znaczenie treści.
Oto dlaczego ekstrakcja oparta na LLM redefiniuje granice możliwości:
- Bez szablonów: działa bezproblemowo w różnych układach, u różnych dostawców i w wielu formatach, w tym PDF, skanach, obrazach i wiadomościach e-mail, bez ręcznej konfiguracji i bez definiowania stałych stref danych.
- Struktura i semantyka: wykracza poza warstwę tekstową i rzeczywiście rozumie dokument, wyodrębniając pary klucz–wartość oraz znaczenie kontekstowe, na przykład identyfikując rozbieżności między warunkami faktury a zapisami umowy.
- Szybkie osiągnięcie wartości biznesowej: przejście od pilotażu do środowiska produkcyjnego w ciągu dni, a nie miesięcy. Bez długotrwałego trenowania i bez złożonej konfiguracji, liczą się realne rezultaty.
- Skalowalność wbudowana w architekturę: łatwe dodawanie nowych pól, typów dokumentów lub reguł biznesowych przy użyciu prostych instrukcji w języku naturalnym. Model natychmiast rozumie Twoją intencję.
Łącząc LLM, Retrieval-Augmented Generation (RAG) oraz zaawansowany framework document intelligence elDoc, organizacje wreszcie otrzymują to, co branża obiecywała od lat, czyli prawdziwą automatyzację, która czyta, rozumie i wyodrębnia dane tak jak człowiek, lecz z ponadludzką szybkością.
Kluczowe możliwości elDoc w zakresie ekstrakcji danych
W elDoc ekstrakcja danych to nie tylko rozpoznawanie tekstu, lecz przede wszystkim jego zrozumienie. Platforma łączy technologię Computer Vision, OCR, inteligencję LLM oraz mechanizmy wnioskowania oparte na RAG w jednym, spójnym procesie przetwarzania, zapewniając rzeczywiście inteligentne rozumienie dokumentów. Poniżej przedstawiamy kluczowe komponenty, które to umożliwiają:
🧠 1. Wstępne przetwarzanie z wykorzystaniem Computer Vision
Zanim rozpocznie się ekstrakcja danych, elDoc wykorzystuje zaawansowaną technologię Computer Vision do normalizacji obrazów dokumentów.
Jeśli dokument zostanie przesłany w niewłaściwej orientacji, jest przekrzywiony lub zawiera artefakty wizualne, takie jak cienie czy smugi, elDoc automatycznie je wykrywa i koryguje.
Dzięki temu proces ekstrakcji danych rozpoczyna się od możliwie najczystszej i najbardziej precyzyjnej reprezentacji wizualnej, co znacząco zwiększa dokładność działania OCR i LLM.
🔍 2. OCR (optyczne rozpoznawanie znaków)
Po normalizacji obrazu technologia OCR przekształca go w tekst możliwy do odczytu maszynowego. elDoc obsługuje zarówno tekst drukowany, jak i odręczny, umożliwiając bezproblemową ekstrakcję danych ze skanów, plików PDF, paragonów, formularzy oraz obrazów. Ten etap przekształca dane wizualne w ustrukturyzowaną treść cyfrową gotową do inteligentnego przetwarzania i interpretacji przez model LLM.

🧩 3. LLM – warstwa rozumienia na poziomie zbliżonym do ludzkiego
Model językowy Large Language Model (LLM) stanowi serce procesu ekstrakcji w elDoc. Nie tylko „czyta”, ale rozumie kontekst, zależności i znaczenie danych zawartych w dokumentach. LLM identyfikuje kluczowe pola, encje i wzorce, takie jak kwoty łączne, daty, numery IBAN, nazwy firm czy klauzule, nawet gdy struktura różni się w zależności od dostawcy lub formatu dokumentu. Umożliwia również wnioskowanie między dokumentami, na przykład weryfikację, czy warunki płatności na fakturze są zgodne z odpowiednią umową lub polityką.
Poza samą ekstrakcją inteligencja oparta na LLM w elDoc automatycznie standaryzuje i normalizuje dane. Dokumenty często zawierają niespójności, takie jak różne formaty dat, waluty, konwencje nazewnictwa czy sposoby prezentacji pól, zależne od dostawców, regionów lub typów dokumentów.
Dzięki elDoc ten chaos zamienia się w spójność. Model LLM rozumie kontekst i znaczenie informacji, co pozwala mu interpretować oraz przekształcać różnorodne formaty w jednolity, ustrukturyzowany standard.
Na przykład:
- Formaty dat, takie jak „01/02/2025”, „Feb 1, 2025” czy „2025-02-01”, są rozpoznawane jako ta sama data i automatycznie standaryzowane.
- Pola walutowe, takie jak „USD 1,000”, „1,000$” czy „US Dollars – One Thousand”, są normalizowane do spójnego formatu.
Taka normalizacja gwarantuje, że wyodrębnione dane są zawsze spójne, uporządkowane i gotowe do analizy, niezależnie od pochodzenia czy układu dokumentu.
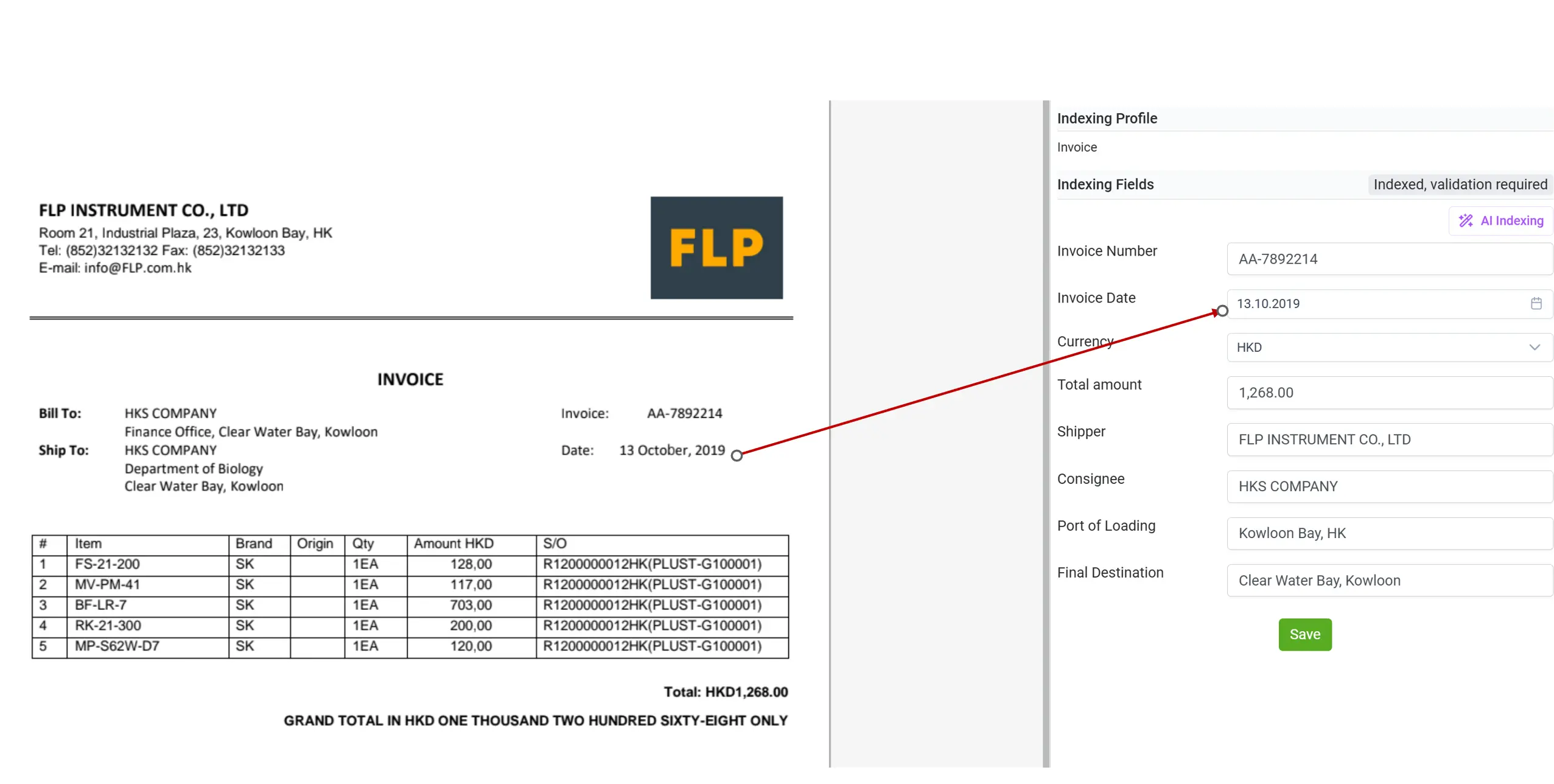
🔗 4. RAG – zaawansowane wnioskowanie i łączenie dokumentów
elDoc integruje technologię Retrieval-Augmented Generation (RAG), aby jeszcze bardziej rozszerzyć możliwości modeli LLM. RAG umożliwia systemowi wyszukiwanie odpowiednich stron, klauzul lub dokumentów pomocniczych w celu osadzenia odpowiedzi w kontekście źródłowym i dostarczania wniosków opartych na faktach. Na przykład możesz zapytać elDoc:
„Potwierdź, czy warunki płatności na tej fakturze są zgodne z umową ramową (Master Service Agreement)”.
RAG odnajduje odpowiednią klauzulę w umowie i porównuje ją z danymi z faktury, dostarczając kontekstową i zweryfikowaną odpowiedź.
Połączenie mechanizmu wyszukiwania i wnioskowania wprowadza zaawansowaną inteligencję dokumentową, wykraczającą daleko poza podstawową ekstrakcję danych.
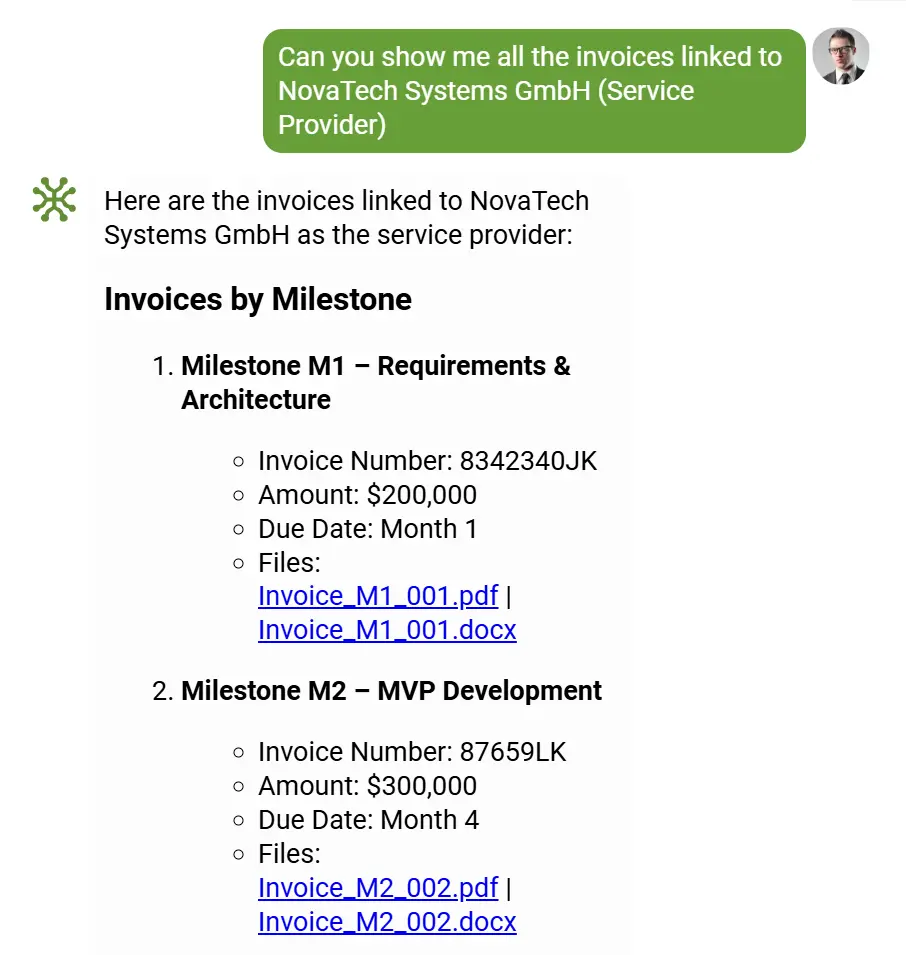
👩💻 5. Weryfikacja Human-in-the-Loop (HITL)
Nawet przy imponującej dokładności ekstrakcji opartej na LLM elDoc uznaje, że weryfikacja przez człowieka nadal odgrywa kluczową rolę, szczególnie w środowiskach regulowanych lub o wysokim poziomie odpowiedzialności. Dlatego elDoc oferuje jako opcjonalną funkcję intuicyjny interfejs Human-in-the-Loop (HITL), zaprojektowany tak, aby łączyć efektywność automatyzacji z precyzją eksperckiego nadzoru.
W ramach tego interfejsu użytkownicy mogą:
- Natychmiast zobaczyć porównanie oryginalnego dokumentu i wyodrębnionych danych obok siebie.
- Zweryfikować, skorygować lub zatwierdzić dowolne pole za pomocą kilku kliknięć.
- Dodać brakujące informacje lub oznaczyć szczególne przypadki wymagające logiki specyficznej dla danego biznesu.
Każda interakcja jest rejestrowana w celu zapewnienia pełnej identyfikowalności, zgodności z regulacjami oraz gotowości do audytu.
W przypadku organizacji przetwarzających złożone lub wrażliwe dokumenty, takie jak sprawozdania finansowe, umowy prawne czy raporty zgodności, HITL gwarantuje, że żadna kluczowa decyzja nie zostanie podjęta bez potwierdzenia przez człowieka, przy jednoczesnym zachowaniu szybkości i skalowalności AI. W skrócie, HITL w elDoc zapewnia to, co najlepsze z obu światów: 1) osąd i nadzór ekspercki człowieka oraz 2) szybkość i inteligencję automatyzacji.
📤 6. Eksport i inteligentne przechowywanie danych – od statycznych dokumentów do żywej bazy wiedzy
Po przetworzeniu, zweryfikowaniu i zatwierdzeniu dokumentów elDoc przekształca wyodrębnione informacje w ustrukturyzowane, gotowe do wykorzystania dane. Dane te mogą następnie płynnie trafiać do dowolnego systemu docelowego, warstwy analitycznej lub workflow. Za pomocą jednego kliknięcia lub automatycznego wyzwalacza procesu elDoc umożliwia natychmiastowy eksport w wielu formatach, takich jak CSV, JSON czy Excel, albo poprzez integrację API z istniejącymi systemami, niezależnie od tego, czy jest to ERP, CRM, system księgowy czy hurtownia danych. Oznacza to, że wyodrębnione dane mogą od razu zasilać procesy biznesowe, raporty i dashboardy bez jakiejkolwiek ręcznej ingerencji czy dodatkowego formatowania.
elDoc wykracza jednak daleko poza sam eksport danych. Wszystkie wyodrębnione i zweryfikowane informacje są automatycznie zapisywane w inteligentnym repozytorium danych elDoc – bezpiecznej, ustrukturyzowanej i przeszukiwalnej warstwie wiedzy zaprojektowanej z myślą o ciągłej analizie AI oraz inteligencji międzydokumentowej.
W tej inteligentnej przestrzeni danych Twoja organizacja może:
- 🔎 Wykonywać zapytania oparte na AI w języku naturalnym, na przykład „Znajdź wszystkie faktury powyżej 5 000 € wystawione przez dostawcę A w ostatnim kwartale”.
- 🔗 Prowadzić wyszukiwanie i analizę dokumentów z wykorzystaniem RAG, pobierając powiązane strony, umowy lub odniesienia w celu dostarczania wniosków opartych na faktach.
- 📊 Realizować analizy między dokumentami, takie jak porównywanie warunków płatności w wielu umowach czy identyfikowanie powtarzających się niespójności danych.
- 🧠 Przeprowadzać dodatkowe wnioskowanie z wykorzystaniem LLM, na przykład prosząc elDoc o „wyświetlenie wszystkich faktur, w których stawka VAT nie odpowiada warunkom umowy” lub „zidentyfikowanie dostawców z podwójnymi pozycjami rozliczeniowymi”.
Ta inteligentna warstwa przechowywania przekształca wcześniej statyczne dokumenty w żywe, wzajemnie powiązane zasoby wiedzy, które są zawsze dostępne, przeszukiwalne i gotowe do pogłębionej analizy lub automatyzacji.
Co więcej, zarządzanie danymi i zgodność z regulacjami są wbudowane w każdy etap procesu:
- Wszystkie przechowywane dane są szyfrowane, objęte kontrolą dostępu oraz wersjonowane.
- Każda zmiana, eksport czy żądanie dostępu są w pełni rejestrowane na potrzeby audytu i zgodności.
- Administratorzy mogą definiować polityki retencji danych, zasady dostępu oraz uprawnienia do eksportu w zależności od roli lub działu.
W istocie elDoc nie tylko wyodrębnia i przechowuje dane, lecz wynosi je na wyższy poziom wartości biznesowej.
Dane dokumentowe stają się stale rosnącą, inteligentną bazą wiedzy, która wspiera zarówno ludzi, jak i systemy AI w podejmowaniu szybszych, trafniejszych i bardziej świadomych decyzji biznesowych.
🔒 Ekstrakcja danych z wykorzystaniem LLM w elDoc – dostępna on-premise i w chmurze
Rozwój Generative AI (GenAI) oraz Large Language Models (LLM) zrewolucjonizował świat przetwarzania dokumentów. Organizacje mogą dziś wyodrębniać, rozumieć i analizować dane z inteligencją zbliżoną do ludzkiej oraz świadomością kontekstu. Mimo ogromnego potencjału nie każda organizacja chce przekazywać poufne dokumenty do zewnętrznych systemów chmurowych i jest to w pełni uzasadnione. Przedsiębiorstwa z sektorów finansów, administracji publicznej, ochrony zdrowia czy prawa przetwarzają wysoce wrażliwe informacje, takie jak umowy, zestawienia, raporty zgodności czy dane osobowe, w przypadku których suwerenność danych, bezpieczeństwo i prywatność nie podlegają negocjacjom. Dla tych organizacji pytanie nie brzmi, czy AI może pomóc, lecz jak wykorzystać ją bezpiecznie we własnej infrastrukturze.
Właśnie tutaj elDoc wyraźnie się wyróżnia. Platforma zapewnia rzeczywistą ekstrakcję danych opartą na LLM oraz inteligencję dokumentową GenAI w pełni dostępną w modelu on-premise, bez opuszczania danych poza Twoje środowisko. Otrzymujesz te same zaawansowane możliwości AI, zdolności wnioskowania i wydajność co w wersji chmurowej, lecz wdrożone w Twojej własnej, bezpiecznej infrastrukturze i pozostające pod pełną kontrolą organizacji.
Z elDoc On-Premise możesz:
- 🏢 Uruchamiać wszystkie procesy LLM i RAG lokalnie, bezpośrednio na własnych serwerach lub w prywatnej chmurze, mając pewność, że żaden dokument, tekst ani metadane nie są przekazywane na zewnątrz.
- 🔐 Zachować pełną kontrolę nad lokalizacją danych, kluczami szyfrowania oraz zarządzaniem dostępem.
- ⚙️ Korzystać z preferowanego modelu LLM, open source, dostrojonego lub klasy enterprise, w pełni zintegrowanego z inteligentnym procesem przetwarzania dokumentów elDoc.
- 🚀 Doświadczać identycznej wydajności jak w środowisku chmurowym dzięki zoptymalizowanej orkiestracji GPU i CPU oraz lekkiej architekturze inferencji.
- 🧩 Łączyć podejście hybrydowe, wykorzystując środowisko on-premise do przetwarzania wrażliwych danych, a chmurę do analityki na dużą skalę lub obsługi mniej poufnych typów dokumentów.
Takie podejście łączy to, co najlepsze z obu światów: moc Generative AI oraz pewność pełnej lokalnej kontroli nad danymi.
W praktyce wdrożenie elDoc w modelu on-premise umożliwia przedsiębiorstwom:
- Wdrażanie inteligencji dokumentowej opartej na LLM za zaporą sieciową organizacji.
- Bezpieczną integrację z wewnętrznymi systemami ERP, CRM oraz innymi systemami.
- Zapewnienie zgodności z rygorystycznymi regulacjami, takimi jak GDPR, HIPAA, SOC 2 czy ISO 27001.
- Jednoczesne korzystanie z szybkiego, zbliżonego do ludzkiego rozumienia i ekstrakcji danych z dowolnego formatu dokumentu.
Niezależnie od tego, czy wybierzesz wdrożenie on-premise, w chmurze czy w modelu hybrydowym, elDoc gwarantuje identyczną funkcjonalność, skalowalność i precyzję działania. Różnica jest prosta: to Ty decydujesz, gdzie przechowywane są Twoje dane. Prawdziwa inteligentna automatyzacja nie powinna odbywać się kosztem prywatności danych, a z elDoc nigdy tak się nie dzieje.