Inteligentne przetwarzanie dokumentów z LLM: bez szablonów, bez konfiguracji – czysta inteligencja AI

W ciągu ostatnich kilku dekad obserwujemy nieprzerwaną falę nowych technologii obiecujących pełną, kompleksową automatyzację przetwarzania dokumentów – dziedzinę, która zyskała nazwę Intelligent Document Processing (IDP).
Dziesiątki dostawców pojawiły się na rynku, aby rozwiązać to wyzwanie, deklarując pełną automatyzację przetwarzania złożonych typów dokumentów. Jednak żadnemu nie udało się osiągnąć rzeczywistej perfekcji.
Dlaczego? Ponieważ dokumenty w rzeczywistym świecie są niezwykle zróżnicowane, nieustrukturyzowane i nieprzewidywalne.
Kluczowe wyzwania tradycyjnych rozwiązań IDP opartych na OCR, AI, Machine Learning oraz NLP obejmowały:
⚙️ Rozbudowaną konfigurację i tworzenie szablonów – każdy nowy format dokumentu wymagał ręcznego definiowania reguł, wyznaczania stref oraz projektowania układu.
🔁 Ciągłe ponowne trenowanie modeli – nawet niewielkie zmiany w strukturze lub układzie dokumentu powodowały błędy w działaniu istniejących modeli i zmuszały zespoły do ich ponownego uczenia.
📄 Ograniczony zakres obsługiwanych dokumentów – większość dostawców specjalizowała się w jednym lub dwóch obszarach (np. faktury, rachunki, dowody osobiste, paszporty) i miała trudności z obsługą innych typów dokumentów.
⚠️ Dokładność i fałszywe trafienia – wyodrębnione dane często zawierały błędy lub niespójności, generując poważne ryzyko finansowe i regulacyjne dla organizacji.
🧑 Wysokie koszty operacyjne – modele wymagały stałego trenowania, monitorowania, walidacji oraz obsługi wyjątków.
🚫 Zależność od udziału człowieka – mimo deklaracji pełnej „automatyzacji”, rzeczywiste przetwarzanie bez udziału człowieka było rzadkością; zawsze konieczna była weryfikacja, korekta lub zatwierdzenie wyników.
W rezultacie to, co miało być inteligentną automatyzacją dokumentów, przekształciło się w złożony, wymagający stałego utrzymania ekosystem szablonów, konfiguracji i cykli ponownego trenowania – daleki od prostoty i elastyczności, których oczekiwały organizacje.
Jak LLM przekształca Intelligent Document Processing
Pojawienie się Large Language Models (LLM) całkowicie zmieniło krajobraz Intelligent Document Processing (IDP). Podczas gdy tradycyjne IDP opierało się na OCR, Machine Learning oraz Natural Language Processing, technologie te pozwalały automatyzować jedynie dane ustrukturyzowane i częściowo ustrukturyzowane, pozostawiając ogromną lukę w zakresie rozumienia dokumentów złożonych i nieustrukturyzowanych.
Obecnie, dzięki połączeniu technologii LLM z OCR i Computer Vision, te luki zostały wreszcie zamknięte.
LLM wprowadzają do automatyzacji dokumentów zdolność rozumienia zbliżoną do ludzkiej, umożliwiając systemom nie tylko „widzenie” tekstu, lecz także rozumienie jego znaczenia, kontekstu oraz intencji.
Oto, w jaki sposób LLM rewolucjonizują cały proces IDP:
🧩 Brak konieczności tworzenia szablonów i konfiguracji
LLM potrafią natychmiast dostosować się do dowolnego układu lub struktury dokumentu, bez potrzeby definiowania stref, tworzenia reguł czy konfigurowania szablonów.
🤖 Bez trenowania modeli i nadzoru człowieka
Koniec z niekończącym się ponownym trenowaniem modeli i ręcznymi korektami. LLM działają od razu po wdrożeniu, rozumiejąc nowe typy dokumentów bez dodatkowych cykli uczenia.
⚡ Natychmiastowa ekstrakcja danych
Informacje są wyodrębniane natychmiast, z pełnym uwzględnieniem kontekstu, bez opóźnień związanych z wstępnym przetwarzaniem czy złożonym mapowaniem danych.
🎯 Wyższa dokładność i niezawodność
LLM znacząco ograniczają liczbę fałszywych trafień, interpretując znaczenie i weryfikując dane w oparciu o kontekst logiczny, a nie wyłącznie rozpoznawanie wzorców.
🔄 Zaawansowana unifikacja i normalizacja danych
LLM mogą automatycznie konwertować formaty danych, na przykład przekształcając zapis słowny w liczby, waluty lub daty, eliminując potrzebę późniejszego przetwarzania lub ręcznej normalizacji.
🧠 Semantyczne rozumienie treści
Poza samą ekstrakcją danych LLM potrafią czytać i rozumieć tekst nieustrukturyzowany, taki jak umowy, raporty czy korespondencja, identyfikując zobowiązania, ryzyka oraz intencje.
🌍 Każdy dokument, każdy format
Od odręcznych notatek po zeskanowane umowy, faktury, sprawozdania finansowe czy e-maile – LLM potrafią przetwarzać dowolną strukturę i format, co przez dekady było niemożliwe.
W skrócie, LLM przekształciły IDP z automatyzacji opartej na regułach w prawdziwą inteligencję. Połączenie OCR, Computer Vision i LLM stanowi przełomową konwergencję technologii, dzięki której maszyny mogą wreszcie „czytać, rozumieć i podejmować decyzje” tak jak ludzie.
Jak elDoc wykorzystuje LLM w Intelligent Document Processing i jakie rezultaty to przynosi
W elDoc w pełni wykorzystujemy nową erę Intelligent Document Processing (IDP) opartego na LLM, łącząc Large Language Models, OCR oraz Computer Vision, aby zapewnić rzeczywiste rozumienie dokumentów, a nie tylko ich automatyzację.
W przeciwieństwie do tradycyjnych systemów opartych na sztywnych szablonach, ręcznej konfiguracji i nadzorze człowieka, AI Document Employees w elDoc działają w sposób inteligentny, natychmiast dostosowując się do nowych typów dokumentów, układów i formatów. Efektem jest płynne rozumienie dokumentów – od ekstrakcji danych po ich interpretację – bez konieczności wstępnego trenowania czy konfiguracji.
Dzięki LLM stanowiącemu rdzeń rozwiązania elDoc potrafi czytać, analizować i rozumieć informacje tak jak ludzki ekspert. System nie tylko wyodrębnia tekst, lecz także rozumie kontekst, zależności i intencje stojące za każdym dokumentem. Niezależnie od tego, czy przetwarzane są faktury, umowy, raporty audytowe czy dokumenty regulacyjne, elDoc inteligentnie interpretuje treść, weryfikuje wyodrębnione dane oraz normalizuje je do spójnych formatów gotowych do wykorzystania w biznesie.
Brak szablonów i konfiguracji
W elDoc dokumenty są przetwarzane natychmiast, niezależnie od ich struktury, układu czy formatu. Nie ma potrzeby tworzenia szablonów, definiowania stref ani konfigurowania mapowań. Wystarczy określić, jakie dane mają zostać wyodrębnione, czyli wskazać listę interesujących pól lub wartości. Po przesłaniu dokumentów elDoc automatycznie uruchamia OCR i Computer Vision, precyzyjnie rozpoznając każdy element na stronie. Następnie inteligencja LLM przejmuje proces, interpretując treść, przeprowadzając automatyczne indeksowanie oraz wyodrębniając wymagane dane z najwyższą dokładnością – bez ręcznej konfiguracji i bez ingerencji użytkownika.
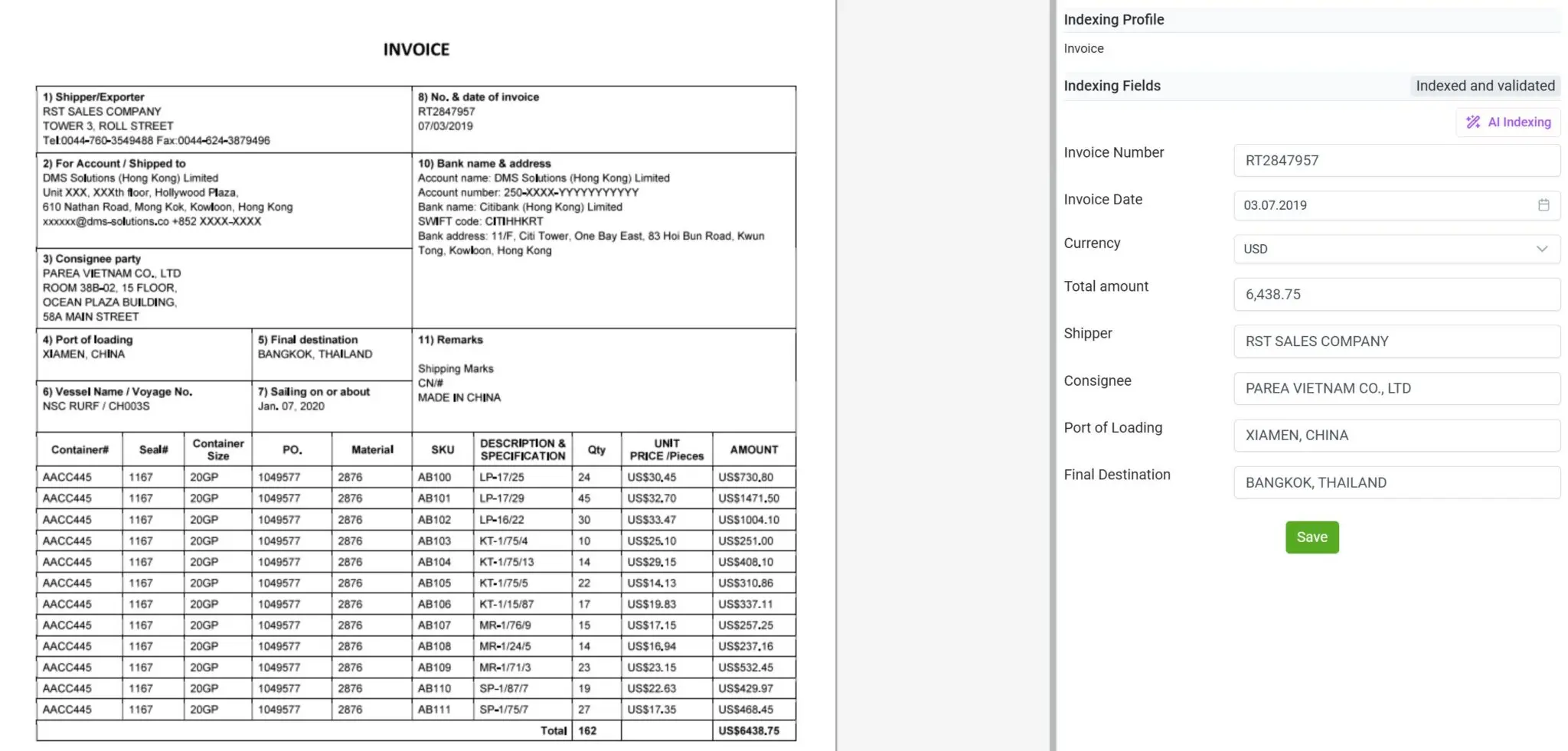
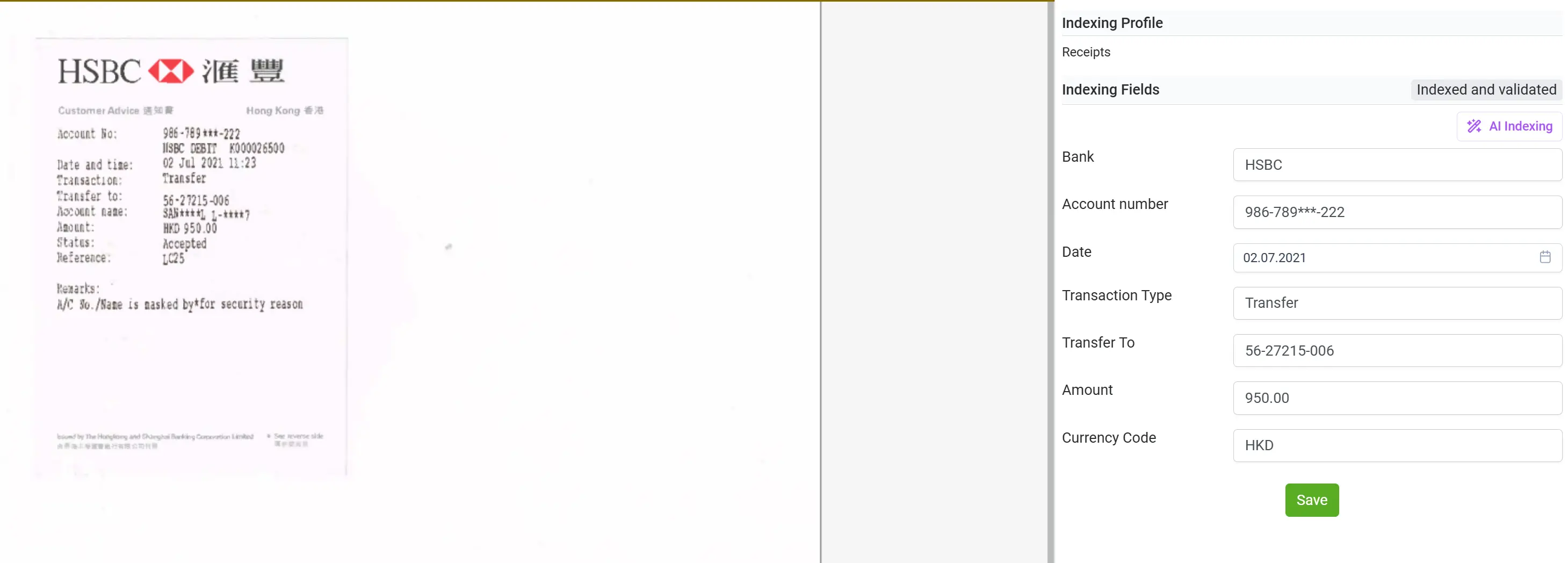
Obsługa szerokiego spektrum dokumentów, nie tylko faktur
Dzięki elDoc nie jesteś już ograniczony wyłącznie do przetwarzania faktur czy formularzy ustrukturyzowanych. Platforma została zaprojektowana do obsługi szerokiego wachlarza typów dokumentów, w tym potwierdzeń z bankomatów, rachunków za media, korespondencji, umów, zamówień zakupu, wyciągów bankowych, transkryptów i wielu innych.
Niezależnie od tego, czy dokument jest zeskanowany, odręczny czy wygenerowany cyfrowo, połączenie OCR, Computer Vision i LLM w elDoc umożliwia jego inteligentne odczytanie, interpretację oraz precyzyjne wyodrębnienie istotnych danych. Ta wszechstronność pozwala organizacjom scentralizować wszystkie procesy dokumentowe w jednej platformie, eliminując potrzebę korzystania z wielu wyspecjalizowanych narzędzi i zapewniając prawdziwą, kompleksową inteligencję dokumentową we wszystkich działach i zastosowaniach.
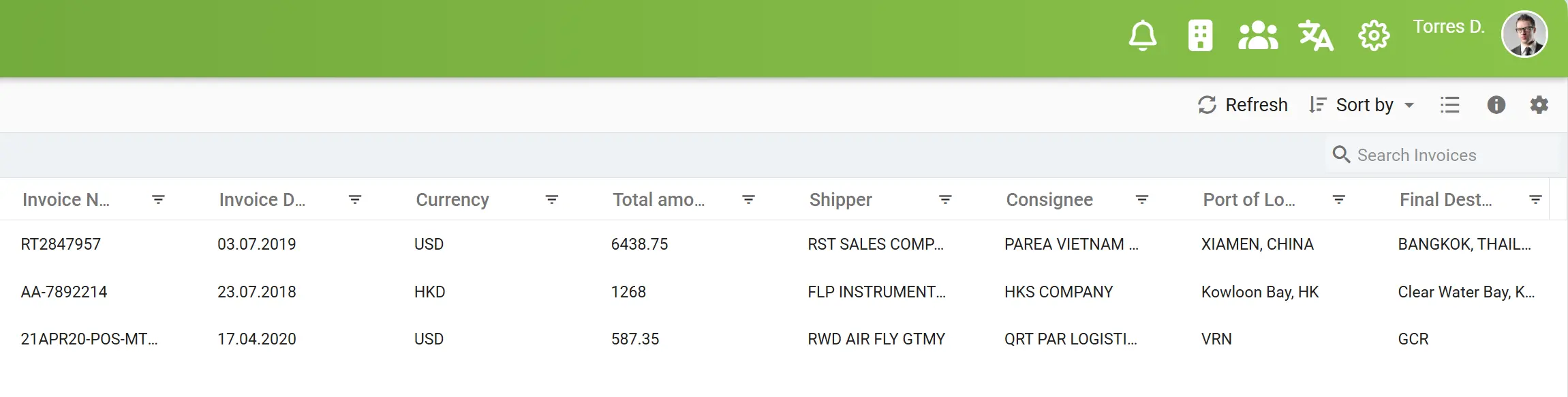
Automatyczne uzupełnianie danych
Po zakończeniu procesu ekstrakcji danych przez elDoc wszystkie przechwycone informacje są automatycznie przenoszone do scentralizowanego panelu indeksowania. Panel ten stanowi inteligentną, ustrukturyzowaną warstwę, w której wyodrębnione pola są natychmiast porządkowane, kategoryzowane i udostępniane do dalszego przetwarzania. Zindeksowane dane mogą być następnie wykorzystywane do zaawansowanego wyszukiwania, filtrowania oraz analizy międzydokumentowej, umożliwiając szybkie odnajdywanie informacji w dużych zbiorach dokumentów.
Automatyzacja ta nie tylko eliminuje ręczne wprowadzanie i klasyfikację danych, lecz także zapewnia spójność, pełną identyfikowalność oraz gotowość informacji do dalszych procesów, niezależnie od tego, czy dotyczą one audytu, kontroli zgodności, czy zaawansowanej analityki. Dzięki elDoc wcześniej nieustrukturyzowane dane stają się w pełni przeszukiwalną, uporządkowaną bazą wiedzy dostępną w kilka sekund.
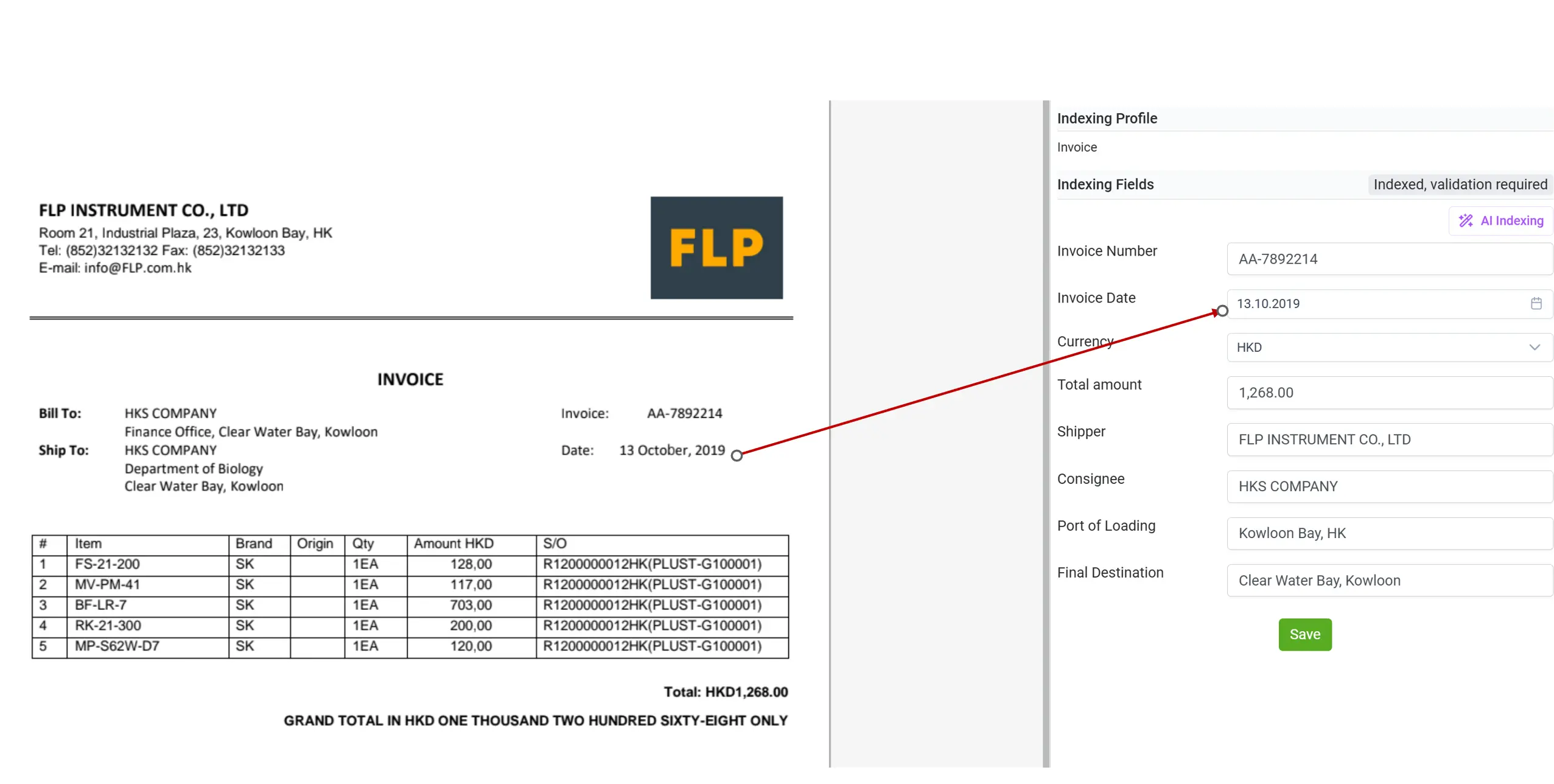
Post-processing danych i normalizacja danych z wykorzystaniem AI
W przeszłości jednym z największych wyzwań w przetwarzaniu dokumentów była normalizacja danych. Różne typy dokumentów i źródła często przedstawiały te same informacje w niespójny sposób, na przykład daty faktur zapisywane z użyciem kropek, ukośników lub słownie, a kwoty prezentowane z różnymi symbolami walut i odstępami. Takie rozbieżności znacząco utrudniały automatyczne przetwarzanie, walidację i integrację danych.
Dzięki post-processingowi opartemu na AI w elDoc problem ten zostaje wyeliminowany. Podczas procesu indeksowania AI system automatycznie rozpoznaje, standaryzuje i konwertuje dane do wymaganego formatu, niezależnie od tego, czy chodzi o przekształcenie „10.03.2025” w „2025-03-10”, czy ujednolicenie formatów walut i liczb w tysiącach dokumentów.
Ta inteligentna normalizacja sprawia, że każda informacja wyodrębniona z dokumentów jest czysta, spójna i gotowa do dalszego wykorzystania, bez potrzeby ręcznych korekt czy dodatkowych skryptów przetwarzających. elDoc przekształca chaotyczne i niespójne dane w wiarygodny, ustrukturyzowany zbiór danych, na którym mogą polegać Twoje systemy.
Rozumienie danych nieustrukturyzowanych
Dzięki elDoc możesz teraz bez wysiłku przetwarzać dane nieustrukturyzowane, takie jak umowy, raporty, korespondencja czy dowolne wielostronicowe dokumenty, które wcześniej wymagały ręcznej analizy. Niezależnie od tego, czy pliki mają formę tekstową, czy są zeskanowanymi obrazami, elDoc automatycznie przeprowadza OCR w celu wyodrębnienia surowego tekstu i elementów wizualnych.
Po zdigitalizowaniu treści indeksowanie AI oparte na LLM analizuje i interpretuje informacje z rozumieniem zbliżonym do ludzkiego, identyfikując encje, zależności i kontekst na przestrzeni setek stron. Nawet gdy dane zapisane są w języku naturalnym, na przykład „płatność w ciągu trzydziestu dni od daty faktury”, elDoc potrafi je zrozumieć, zinterpretować i przekształcić w dane ustrukturyzowane, takie jak konkretne daty, kwoty czy warunki. Ta zaawansowana funkcjonalność pozwala elDoc czytać i rozumieć dokumenty jak człowiek, precyzyjnie uchwytując znaczenie, intencję i relacje w treści nieustrukturyzowanej oraz natychmiast przekształcając je w uporządkowane, gotowe do działania informacje.

Nowa era możliwości IDP dla każdej potrzeby biznesowej
Chociaż IDP oparte na LLM koncentruje się na inteligentnej automatyzacji, nadal istnieje wiele aspektów praktycznych i operacyjnych, które należy uwzględnić, aby zapewnić wydajność na poziomie korporacyjnym. elDoc został zaprojektowany tak, aby bezproblemowo sprostać tym wymaganiom.
W sytuacjach, gdy wymagana jest walidacja danych, elDoc udostępnia dedykowaną Validation Station, czyli intuicyjny interfejs umożliwiający użytkownikom przegląd i potwierdzenie wyodrębnionych danych zgodnie z oczekiwaniami lub regułami biznesowymi przed ich ostatecznym zatwierdzeniem. Zapewnia to maksymalną dokładność danych i zgodność z wymogami, szczególnie w przypadku kluczowych dokumentów, takich jak sprawozdania finansowe, umowy czy dokumenty regulacyjne.
Po zatwierdzeniu dane mogą zostać łatwo wyeksportowane w różnych formatach, takich jak JSON lub CSV, w celu integracji z systemami docelowymi, na przykład ERP, CRM lub platformami analitycznymi.
elDoc oferuje również pełną elastyczność w zakresie przepływów pracy związanych z przetwarzaniem dokumentów. Użytkownicy mogą przetwarzać dokumenty pojedynczo, wpisując polecenie:
„Proszę wyodrębnić i zindeksować dane z tego dokumentu”,
lub obsługiwać zadania na skalę przedsiębiorstwa, w których tysiące plików są przesyłane zbiorczo w celu automatycznej klasyfikacji, ekstrakcji i inteligentnego indeksowania.
Ta elastyczność sprawia, że elDoc doskonale sprawdza się zarówno w zastosowaniach ad hoc, jak i w środowiskach korporacyjnych na dużą skalę, dostosowując się do specyficznych potrzeb każdej organizacji.
W rezultacie elDoc otwiera nową erę Intelligent Document Processing, przełamując ograniczenia systemów legacy i dostarczając firmom to, czego zawsze potrzebowały: szybkość, dokładność, elastyczność oraz prawdziwą inteligencję w każdym procesie dokumentowym.