Jak wyodrębniać dane z faktur przy użyciu GenAI (OCR, LLM, CV i RAG)

Tradycyjne przetwarzanie faktur jest powolne, manualne i podatne na błędy. Zespoły finansowe spędzają niezliczone godziny na przeglądaniu plików PDF, wyłapywaniu kwot, weryfikowaniu dostawców, sprawdzaniu numerów zamówień (PO) oraz wprowadzaniu danych do systemów ERP. Przez dekady dostawcy obiecywali, że „w końcu rozwiązali” problem ekstrakcji danych z faktur. Rzeczywistość była jednak zupełnie inna. Większość starszych rozwiązań wymagała jednego lub kilku z poniższych elementów:
- Konfiguracji szablonów lub układów dla każdego dostawcy
- Ciągłego ponownego trenowania wraz ze zmianą formatów
- Dedykowanego rozwoju dla przypadków specjalnych lub dokumentów niestandardowych
- Sztywnych modeli ML/NLP, które działały dobrze wyłącznie dla znanych układów
- Wysokiej liczby fałszywych trafień przy zróżnicowanych fakturach lub pogorszonej jakości dokumentów
- Częstych ręcznych korekt, przez co „automatyzacja” była tylko z nazwy
Nawet najbardziej zaawansowane narzędzia „AI OCR” poprzedniej generacji miały zasadnicze ograniczenia. Potrafiły odczytać tekst, ale nie potrafiły go zrozumieć. Rozpoznawały znaki, lecz nie znaczenie. Przechwytywały słowa, ale nie kontekst.
GenAI zmienia wszystko
Dziś zaawansowana inteligencja AI OCR w połączeniu z modelami LLM umożliwia organizacjom natychmiastowe wyodrębnianie ustrukturyzowanych danych z faktur, nawet ze skanów, dokumentów obróconych, odręcznych, wielojęzycznych lub niskiej jakości.
Bez szablonów.
Bez reguł niestandardowych.
Bez konfiguracji układów.
Bez niekończących się cykli trenowania modeli.
Jedynie zrozumienie na poziomie człowieka, osiągane z nadludzką szybkością. W tym artykule elDoc wyjaśnia, jak działa nowoczesna ekstrakcja danych z faktur oparta na GenAI, jakie technologie ją umożliwiają oraz dlaczego to podejście zdecydowanie przewyższa tradycyjne systemy oparte wyłącznie na OCR.
Jak elDoc zapewnia bezproblemową ekstrakcję danych z faktur: pełny stos technologii AI
Przetwarzanie faktur w elDoc opiera się na zintegrowanym potoku obejmującym silniki OCR, moduły computer vision, wnioskowanie LLM, kontekstowe wyszukiwanie oparte na RAG, wyszukiwanie semantyczne oraz wysokowydajne bazy danych. Wszystkie te technologie są skoordynowane tak, aby działać jako jeden spójny system, zapewniając precyzyjną ekstrakcję, inteligentną walidację oraz dokładną klasyfikację dla każdego formatu faktury, bez szablonów i bez ręcznej konfiguracji.
🔤 OCR — konwersja obrazów i plików PDF do postaci tekstowej
Większość faktur trafia do systemów w postaci skanów, obrazów lub nieprzeszukiwalnych plików PDF. OCR przekształca je w tekst możliwy do odczytu maszynowego, dzięki czemu AI może faktycznie „czytać” i interpretować zawartość dokumentów.
Zakres działania tej warstwy obejmuje:
- Ekstrakcję tekstu z obrazów i skanów
- Umożliwienie przeszukiwania plików PDF
- Umożliwienie dalszego wnioskowania przez modele AI
- Obsługę danych wielojęzycznych oraz zaszumionych
Silniki OCR wykorzystywane przez elDoc:
- Tesseract – otwartoźródłowy OCR do ogólnej ekstrakcji
- Google OCR API – chmurowy OCR o wysokiej dokładności dla złożonych treści
- Qwen3-VL – OCR typu vision-language z wbudowanym rozumieniem układu dokumentu
- PaddleOCR – niezwykle szybki, wielojęzyczny OCR dla różnorodnych formatów
W zależności od tego, czy rozwiązanie jest wdrożone lokalnie (on-premise), czy w chmurze, elDoc aktywuje najbardziej odpowiedni silnik OCR. Każdy z nich zapewnia wyjątkową dokładność oraz niezawodne rozpoznawanie tekstu.
🖼️ Computer Vision — czyszczenie i normalizacja dokumentu
Zanim jakikolwiek model AI zacznie interpretować fakturę, warstwa computer vision optymalizuje dokument pod kątem dokładności.
Funkcje realizowane przez tę warstwę:
- Prostowanie i wyrównywanie obróconych stron
- Usuwanie szumów oraz poprawę kontrastu
- Wykrywanie tabel, pieczęci i podpisów
- Segmentację stron oraz rozpoznawanie układu
- Normalizację skanów niskiej jakości
Dzięki temu OCR dostarcza czysty, ustrukturyzowany tekst nawet w przypadku nieuporządkowanych, starych lub niskiej rozdzielczości faktur.
🧠 LLM — rzeczywiste zrozumienie treści
Model językowy LLM stanowi „mózg” warstwy inteligencji elDoc. Odczytuje faktury jak człowiek, lecz z nadludzką szybkością, głębią analizy i spójnością.
Możliwości LLM obejmują:
- Zrozumienie znaczenia, kontekstu i intencji
- Rozpoznawanie typów i podtypów dokumentów
- Interpretację nieustrukturyzowanego i chaotycznego tekstu
- Ekstrakcję wszystkich kluczowych pól, takich jak kwoty, daty, VAT, dane dostawcy czy pozycje
- Wykrywanie niespójności i anomalii
- Klasyfikację dokumentów bez szablonów i reguł
To przełom, którego starsze systemy ML/NLP nigdy nie były w stanie osiągnąć.
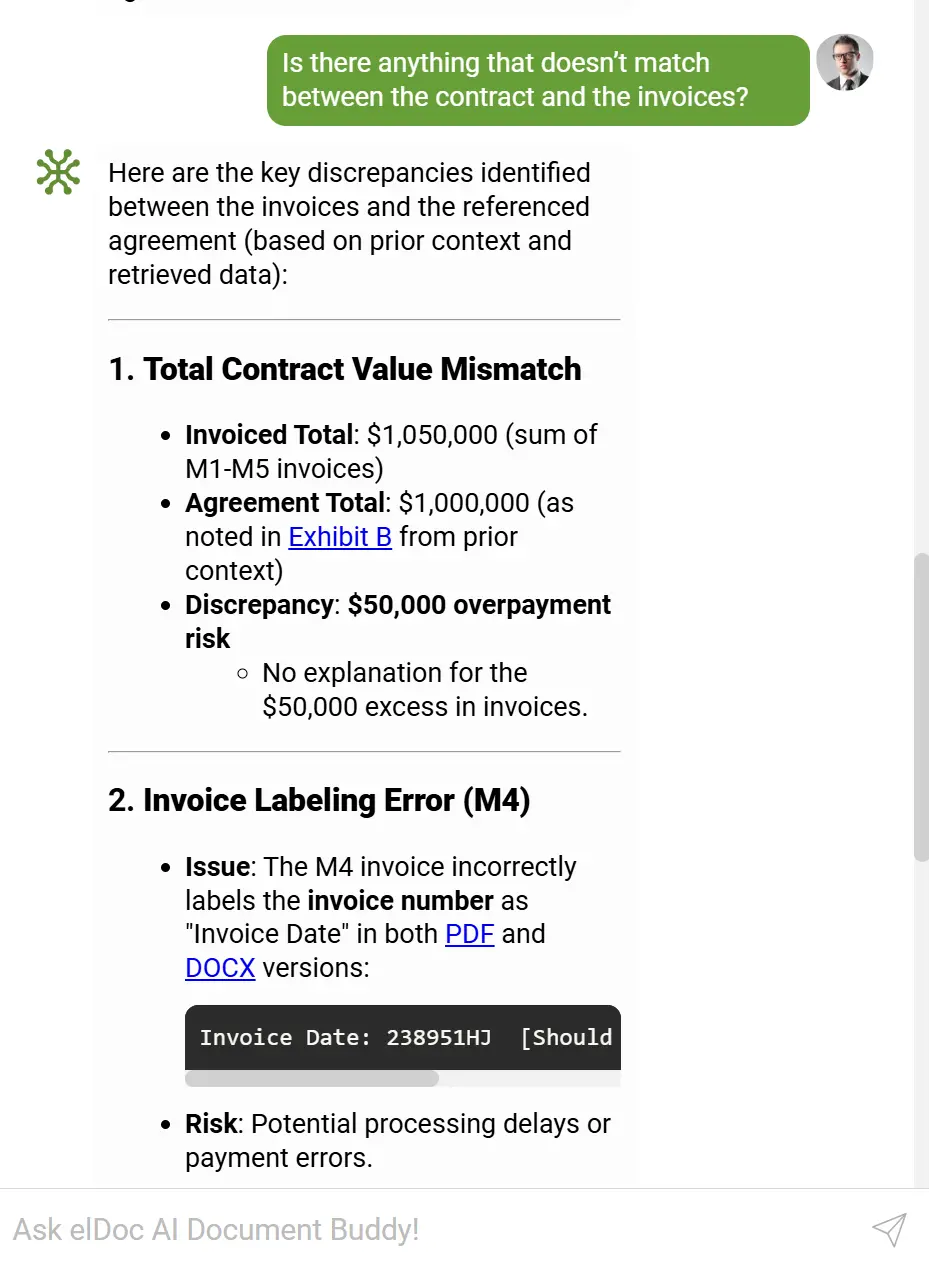
🔎 RAG — łączenie kontekstu pomiędzy dokumentami
Retrieval-Augmented Generation (RAG) dodaje głęboką inteligencję poprzez łączenie dokumentów ze sobą.
RAG umożliwia elDoc:
- Wyszukiwanie powiązanych faktur, zamówień (PO) i umów
- Przeprowadzanie walidacji między dokumentami
- Wykrywanie niespójności pomiędzy dokumentami
- Odpowiadanie na złożone pytania finansowe z wykorzystaniem wielu plików
- Budowanie kontekstowej „pamięci” całego repozytorium dokumentów
RAG przekształca całe repozytorium w dynamiczną, wzajemnie powiązaną bazę wiedzy.
🔒 MongoDB — skalowalne przechowywanie dokumentów
MongoDB pełni rolę głównego silnika przechowywania w elDoc, obsługując zarówno metadane, jak i duże pliki z wyjątkową wydajnością.
Dlaczego MongoDB?
- Wysoka skalowalność umożliwiająca obsługę milionów faktur
- Elastyczny schemat dostosowany do nieprzewidywalnych struktur dokumentów
- Szybkie wyszukiwanie danych na potrzeby procesów w czasie rzeczywistym
- Niezawodność i wydajność klasy korporacyjnej
MongoDB stanowi fundament warstwy danych strukturalnych platformy elDoc.
🧭 Qdrant — inteligencja semantyczna i wyszukiwanie wektorowe
Qdrant to wektorowa baza danych elDoc, która zapewnia dokumentom rzeczywiste zrozumienie semantyczne.
Qdrant umożliwia elDoc:
- Zrozumienie treści wykraczające poza dopasowanie słów kluczowych
- Natychmiastowe znajdowanie podobnych faktur oraz duplikatów
- Grupowanie powiązanych dokumentów
- Dopasowywanie faktur do umów lub zamówień (PO)
- Obsługę wyszukiwania semantycznego wspieranego przez AI
Jest to kluczowe dla inteligentnej walidacji oraz mapowania relacji pomiędzy dokumentami.
🔎 Apache Solr — pełnotekstowe wyszukiwanie o wysokiej wydajności
Solr uzupełnia warstwy AI i semantyczne o indeksowanie oraz wyszukiwanie słów kluczowych klasy korporacyjnej.
Solr zapewnia:
- Natychmiastowe wyszukiwanie pełnotekstowe wśród milionów plików
- Nawigację fasetową oraz filtrowanie wyników
- Zaawansowane mechanizmy rankingu i oceny trafności
- Ogromną skalowalność indeksowania
W połączeniu z Qdrantem Solr tworzy hybrydowy silnik wyszukiwania: wyszukiwanie słów kluczowych + wyszukiwanie semantyczne + wnioskowanie AI.
elDoc udostępnia GenAI każdemu: edycja elDoc Community
Dzięki edycji elDoc Community każdy — od niezależnych specjalistów po małe zespoły i firmy średniej wielkości — może natychmiast rozpocząć korzystanie z zaawansowanej automatyzacji dokumentów opartej na GenAI. Wszystkie kluczowe komponenty są już zintegrowane i zoptymalizowane, zapewniając użytkownikom praktyczne, rzeczywiste środowisko do pracy z AI OCR, ekstrakcją opartą na LLM, RAG oraz wyszukiwaniem semantycznym — bez złożonej konfiguracji i barier technicznych.
elDoc łączy GenAI, OCR, Computer Vision, RAG, wyszukiwanie semantyczne oraz wysokowydajne silniki danych w jeden spójny, inteligentnie skoordynowany pipeline. Zamiast opierać się na jednym modelu, statycznych regułach lub sztywnych szablonach, elDoc orkiestruje każdą technologię w optymalnej kolejności — od oczyszczania dokumentu, przez rozpoznawanie tekstu, aż po głębokie zrozumienie semantyczne, walidację oraz przechowywanie i eksport danych. Każda warstwa wnosi określoną funkcję: OCR odczytuje treść, Computer Vision normalizuje dokument, modele LLM rozumieją znaczenie, a RAG łączy kontekst w całej bibliotece dokumentów. W połączeniu ta holistyczna architektura zapewnia naprawdę niezawodną, bezszablonową ekstrakcję danych z faktur, działającą spójnie niezależnie od formatu dokumentu, języka, układu czy jakości skanu — nawet w najbardziej złożonych, rzeczywistych warunkach.