Ekstrakcja danych z PDF i skanów za pomocą GenAI: jak OCR, LLM i RAG zmieniają inteligencję dokumentów

Ekstrakcja danych z plików PDF oraz zeskanowanych dokumentów od zawsze była jednym z najbardziej problematycznych wyzwań w cyfrowych operacjach biznesowych. Przez lata organizacje polegały na systemach ekstrakcji opartych na szablonach, które wymagały tworzenia, konfigurowania i utrzymywania oddzielnych szablonów dla każdego typu dokumentu, dostawcy, układu i formatu. Wystarczyło przesunięcie jednego pola o kilka pikseli, aby szablon przestał działać. Pojawienie się nowego dostawcy oznaczało konieczność przygotowania kolejnej konfiguracji przez zespół IT. Gdy dla tej samej kategorii dokumentów istniało wiele układów, złożoność rosła wykładniczo.
Tradycyjne OCR potrafiło odczytywać tekst, ale nie rozumiało jego znaczenia ani tego, do jakiego kontekstu należą poszczególne informacje. Dokumenty były traktowane jak płaskie obrazy, bez uwzględnienia ich struktury, sensu i wzajemnych powiązań. W efekcie firmy poświęcały ogromne ilości czasu na dopracowywanie szablonów, weryfikację wyników oraz ręczne korygowanie błędów ekstrakcji. Proces ten był powolny, kosztowny, mało elastyczny i trudny do skalowania.
Nowoczesne GenAI całkowicie zmienia ten model. Zamiast zmuszać organizacje do dostosowywania się do ograniczeń szablonów, GenAI dostosowuje się do samego dokumentu. Łącząc OCR, Computer Vision, duże modele językowe (LLM) oraz Retrieval-Augmented Generation (RAG), organizacje mogą wreszcie wyjść poza podstawowe rozpoznawanie tekstu i przejść do rzeczywistego rozumienia dokumentów.
Jak elDoc upraszcza ekstrakcję danych i czyni ją bezwysiłkową dla użytkowników końcowych
Choć wiele platform deklaruje wykorzystanie AI do przetwarzania dokumentów, większość z nich nadal opiera się na tradycyjnym OCR połączonym ze sztywnymi szablonami lub z góry zdefiniowanymi regułami ekstrakcji. elDoc przyjmuje zasadniczo inne podejście. Zamiast traktować dokumenty jak statyczne pliki tekstowe, elDoc przetwarza je jako inteligentne, wielowarstwowe artefakty, które zawierają strukturę wizualną, znaczenie semantyczne, logikę kontekstową oraz relacje biznesowe.
Architektura elDoc opiera się na czterech ściśle zintegrowanych filarach: OCR, Computer Vision, dużych modelach językowych (LLM) oraz Retrieval-Augmented Generation. Razem tworzą one jednolity pipeline GenAI, zdolny do interpretowania dokumentów w sposób zbliżony do ludzkiego rozumowania, przy jednoczesnym zachowaniu spójności i szybkości wymaganych w środowisku enterprise.
Choć stojący za elDoc pipeline GenAI jest wysoce zaawansowany, platforma została zaprojektowana tak, aby użytkownicy końcowi nie musieli myśleć o silnikach OCR, konfiguracjach modeli, etapach wstępnego przetwarzania ani logice dokumentów. Wszystko odbywa się automatycznie w tle. Użytkownicy otrzymują przejrzysty i intuicyjny proces, który nawet najbardziej złożone pliki PDF i skany zamienia w ustrukturyzowane, wiarygodne dane w zaledwie kilku krokach.
1. Przesyłanie plików ręcznie lub automatycznie – OCR i Computer Vision stosowane automatycznie
Użytkownicy mogą dodawać dokumenty do elDoc w możliwie najprostszy sposób:
- ręczne przesyłanie metodą „przeciągnij i upuść”
- automatyczne pobieranie z monitorowanych folderów
- przetwarzanie dokumentów przesyłanych e-mailem do elDoc
- integracje oparte na API z systemami ERP, SharedDrive, OneDrive lub CRM
W momencie, gdy plik trafia do elDoc, przetwarzanie rozpoczyna się automatycznie. Nie ma potrzeby konfigurowania szablonów, definiowania typów dokumentów ani przygotowywania reguł ekstrakcji. Gdy tylko pojawi się plik PDF lub zeskanowany obraz, elDoc automatycznie uruchamia OCR w celu wydobycia tekstu. W przeciwieństwie do tradycyjnych systemów, które wymagają ręcznego wyboru silnika lub przełączania narzędzi w zależności od języka, jakości czy złożoności dokumentu, elDoc abstrahuje całą tę złożoność.
elDoc obsługuje wiele silników OCR, zoptymalizowanych pod kątem wdrożeń chmurowych i on-premise, treści wielojęzycznych oraz scenariuszy wymagających wysokiej dokładności. Jeśli dokument wymaga zrozumienia struktury, Computer Vision jest stosowane automatycznie. elDoc przejmuje wszystkie techniczne etapy po stronie użytkownika, takie jak wykrywanie tabel i par klucz–wartość, korekta orientacji obrazu, redukcja szumów, korekcja przekoszeń i perspektywy oraz segmentacja układu. Użytkownicy końcowi nie muszą regulować jasności, obracać obrazów ani zastanawiać się, czy dokument jest „wystarczająco dobry”. elDoc normalizuje wszystko przed zastosowaniem głębszego przetwarzania, zapewniając najwyższą jakość ekstrakcji bez ręcznej ingerencji.

2. Naciśnij przycisk „AI Indexing (AI Data Capture)” – bez szablonów, bez konfiguracji
Po przesłaniu plików użytkownik po prostu klika „AI Indexing (AI Data Capture)”. To wszystko – nie trzeba projektować szablonów, rysować pól na ekranie, programować reguł ani definiować typów dokumentów wcześniej. Jednym kliknięciem elDoc uruchamia pełny pipeline GenAI. OCR odczytuje dokument, Computer Vision interpretuje układ, LLM rozumie znaczenie, a RAG osadza ekstrakcję w logice biznesowej. Wszystko dzieje się automatycznie, bez żadnych decyzji ani konfiguracji po stronie użytkownika.
Doświadczenie jest celowo proste: Prześlij → Kliknij AI Indexing → Otrzymaj uporządkowane dane.
W tle elDoc wykonuje zadania, które kiedyś wymagały specjalistycznych zespołów – użytkownik widzi jednak jedynie elegancki, jednoprzyciskowy przepływ pracy działający dla faktur, zamówień zakupu, formularzy, umów, raportów, dokumentów KYC, dokumentów transportowych i wielu innych.

3. Przeglądaj przechwycone dane — pojedynczo lub masowo, z pełnym kontekstem wizualnym
Po zakończeniu procesu AI Indexing w elDoc, użytkownicy mogą natychmiast przeglądać wyekstrahowane dane w sposób najlepiej dopasowany do ich przepływu pracy. Platforma zapewnia pełną elastyczność — zarówno przy szczegółowej analizie jednego dokumentu, jak i przy przetwarzaniu setek dokumentów jednocześnie.
W przypadku przeglądu pojedynczego dokumentu użytkownicy mogą otworzyć dowolny plik i zobaczyć wizualizację obok siebie:
- oryginalny PDF lub zeskanowany obraz po jednej stronie oraz
- wyekstrahowane, uporządkowane dane po drugiej stronie.
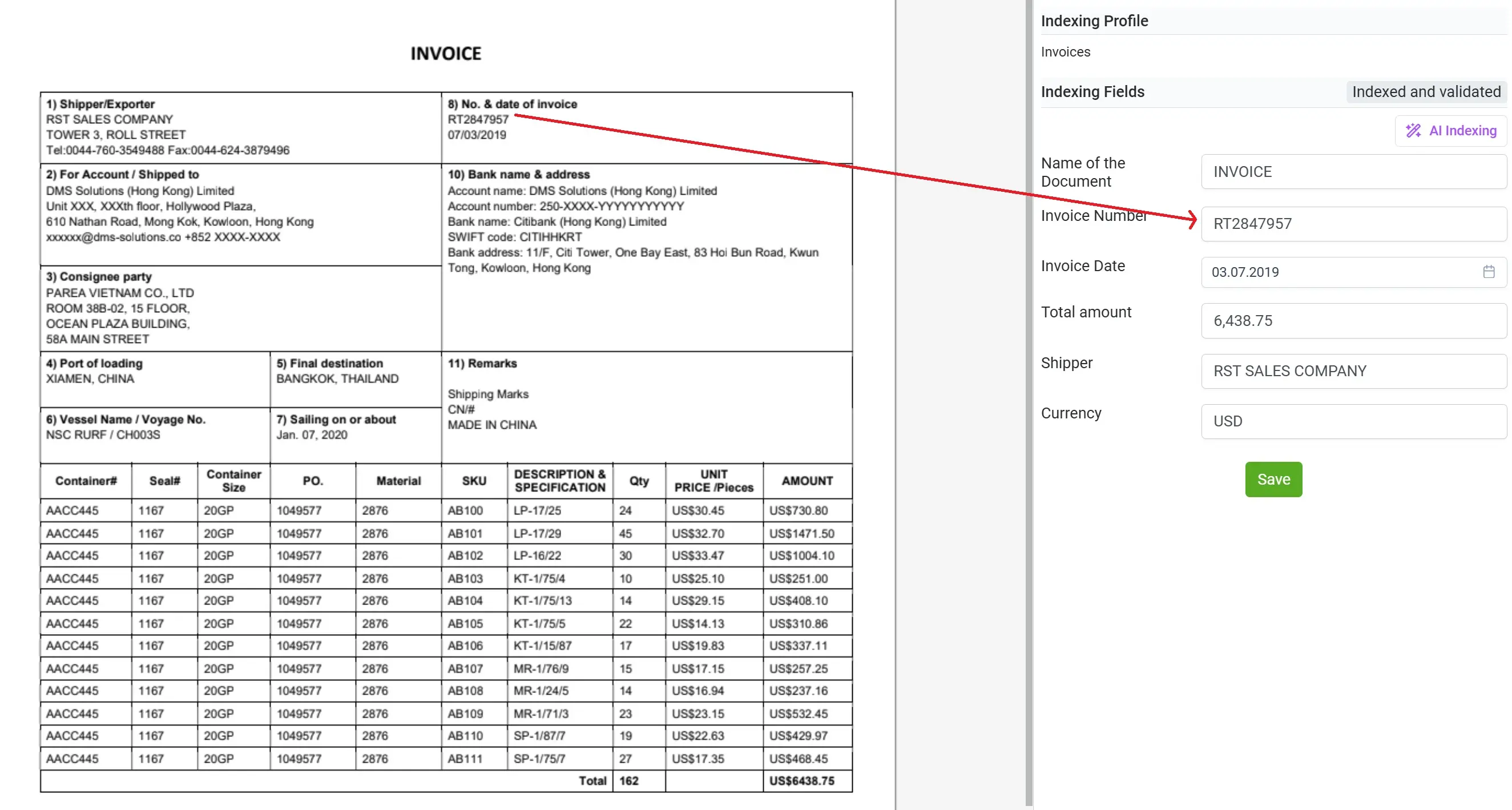
To sprawia, że weryfikacja jest niezwykle szybka. Nie trzeba zmieniać zakładek, szukać pól ani zgadywać, skąd pochodzą dane. Każde wykryte pole jest wyraźnie pokazane, a dokładność można potwierdzić wizualnie, linia po linii, w czasie rzeczywistym.
W razie potrzeby użytkownicy mogą rozwinąć tabelę, sprawdzić pozycje, podsumowania częściowe, daty i zweryfikować wartości całkowite — wszystko bez opuszczania widoku dokumentu.
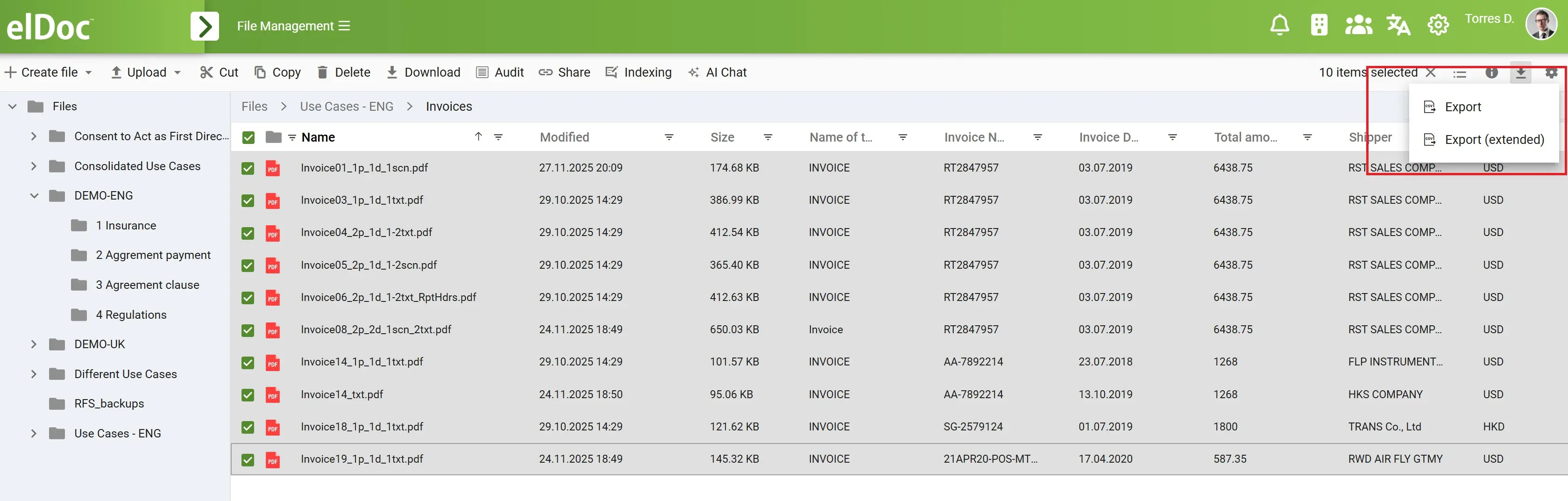
W przypadku przeglądu masowego elDoc oferuje potężny, scentralizowany pulpit. Można zobaczyć dane przechwycone ze wszystkich przetworzonych dokumentów jednocześnie. Ten widok umożliwia:
- filtrowanie według typu dokumentu, dostawcy, daty, statusu lub dowolnego wyekstrahowanego pola
- reorganizację kolumn i dostosowanie układu
- grupowanie i sortowanie zgodnie z wewnętrznym przepływem pracy
- eksport podzbiorów danych do systemów dalszego przetwarzania
- natychmiastowe wykrywanie anomalii lub brakujących informacji w wielu plikach
Ułatwia to obsługę dużych partii dokumentów z taką samą precyzją, jak pojedynczy dokument. Zamiast otwierać PDF-y jeden po drugim lub ręcznie kopiować wartości do arkuszy kalkulacyjnych, użytkownicy otrzymują czysty, uporządkowany zestaw danych gotowy do analizy, prezentowany w znanym widoku tabeli.
elDoc daje każdemu użytkownikowi kontrolę nad sposobem pracy: szczegółową weryfikację z kontekstem wizualnym lub operacje na dużych zestawach danych obejmujących tysiące dokumentów. Oba doświadczenia zostały zaprojektowane tak, aby były intuicyjne i łatwe, działając w tle dzięki GenAI, OCR, Computer Vision i RAG.

4. Eksportuj wyekstrahowane dane do CSV jednym kliknięciem — gotowe do każdego przepływu pracy
Po przeglądzie przechwyconych danych — pojedynczo lub w całej partii — elDoc umożliwia bezproblemowy eksport wszystkiego, co jest potrzebne. Za jednym kliknięciem użytkownicy mogą pobrać wszystkie wyekstrahowane pola, tabele i uporządkowane informacje w czystym, gotowym do użycia pliku CSV. Nie ma potrzeby ręcznego kopiowania i wklejania, czyszczenia danych, formatowania arkuszy ani radzenia sobie z niejednolitymi strukturami. elDoc automatycznie organizuje wyekstrahowane informacje w ustandaryzowany format, który płynnie wpasowuje się w przepływy pracy.
Wyeksportowany plik CSV jest natychmiast gotowy do użycia. Każda kolumna jest opisana, każdy wiersz spójny, a każde wpisane pole odzwierciedla informacje przechwycone z dokumentów. W przypadku przetwarzania masowego funkcja ta staje się niezwykle potężna. Użytkownicy mogą przetwarzać setki — a nawet tysiące — dokumentów za pomocą AI Indexing i wyeksportować jeden skonsolidowany plik CSV zawierający wszystkie wyekstrahowane dane. Filtry, widoki niestandardowe i wybór pól pozwalają eksportować dokładnie to, czego potrzebujesz, nic więcej i nic mniej.
To zmienia godziny (lub dni) ręcznej pracy związanej z ekstrakcją danych w prosty przepływ pracy:
Prześlij → AI Indexing → Przegląd → Eksport.
Jednym kliknięciem Twoja organizacja otrzymuje czyste, uporządkowane i zweryfikowane dane — gotowe do wykorzystania w systemach, które ich potrzebują. Ciężką pracę wykonują OCR, Computer Vision, LLM i RAG, a użytkownik korzysta z płynnego, bezproblemowego procesu zaprojektowanego do codziennej pracy biznesowej.
5. Rozmawiaj z danymi za pomocą GenAI — zadawaj pytania, otrzymuj natychmiastowe odpowiedzi
Gdy dokumenty są już zaindeksowane i uporządkowane, elDoc udostępnia potężną funkcję: możesz prowadzić rozmowy bezpośrednio ze swoimi wyekstrahowanymi danymi za pomocą GenAI. Zamiast ręcznie przeszukiwać faktury, zestawienia, formularze czy raporty, wystarczy zadawać pytania w języku naturalnym — a elDoc udziela precyzyjnych odpowiedzi osadzonych w kontekście.
Użytkownicy mogą natychmiast przeprowadzać dogłębną analizę finansową, porównania, tworzyć podsumowania, klasyfikacje lub weryfikacje. Na przykład możesz zapytać:
- „Podsumuj wszystkie faktury od Dostawcy X za ostatni kwartał.”
- „Jaka jest łączna kwota VAT w tych 150 fakturach?”
- „Pokaż wszystkie transakcje powyżej 50 000 HKD w moich wyciągach bankowych.”
- „Porównaj warunki płatności we wszystkich otrzymanych zamówieniach zakupu.”
- „Zaznacz faktury z niezgodnymi sumami lub potencjalnymi błędami.”
- „Pokaż podział wydatków według kategorii.”
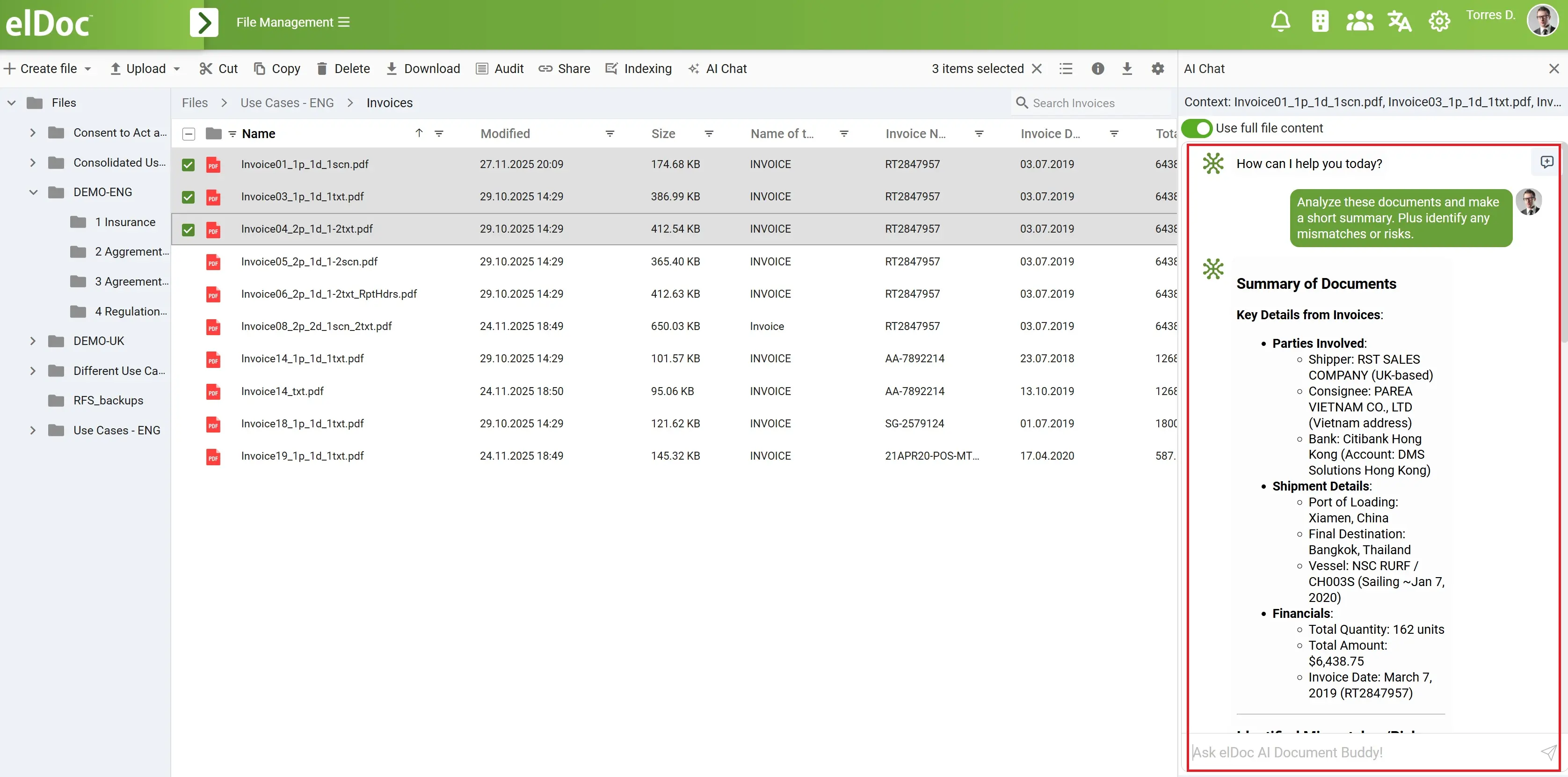
Silnik GenAI w elDoc wykorzystuje uporządkowane dane wyekstrahowane podczas procesu przetwarzania, wraz z kontekstem oryginalnych dokumentów, aby generować dokładne i w pełni oparte na źródłach odpowiedzi. W połączeniu z RAG i wyszukiwaniem wektorowym system pobiera odpowiednie informacje, zapewniając, że odpowiedzi są rzetelne i zgodne z wewnętrznymi zasadami firmy.
Dzięki temu wyekstrahowane dane stają się inteligentną warstwą wiedzy, którą można przeszukiwać, analizować i rozumieć w formie konwersacyjnej — bez arkuszy kalkulacyjnych, formuł czy skomplikowanych zapytań.
Nawet duże zestawy dokumentów stają się łatwe do eksploracji. Użytkownicy nie muszą już ręcznie sprawdzać wartości ani tworzyć tabel przestawnych. Wystarczy, że zadają pytanie, a elDoc dostarcza wgląd, podsumowania i szczegółowe odniesienia do źródłowych dokumentów w razie potrzeby. GenAI przekształca statyczne dane dokumentów w dynamiczny, interaktywny zasób — umożliwiając zespołom finansowym, ds. zgodności, operacyjnym i audytowym pracę mądrzej, szybciej i bardziej pewnie.