Procesamiento Inteligente de Documentos con LLM: sin plantillas, sin configuración, solo inteligencia

Durante las últimas décadas, ha habido una ola constante de nuevas tecnologías que prometían automatizar el procesamiento de documentos de principio a fin, una disciplina que pasó a conocerse como Procesamiento Inteligente de Documentos (IDP).
Decenas de proveedores surgieron para resolver este desafío, cada uno afirmando lograr una automatización total en documentos complejos. Sin embargo, ninguno logró alcanzar una verdadera perfección.
¿Por qué? Porque los documentos del mundo real son altamente diversos, no estructurados e impredecibles.
Los principales desafíos de las soluciones tradicionales de IDP, basadas en OCR, IA, aprendizaje automático y NLP, incluían:
⚙️ Configuración pesada y uso de plantillas: cada nuevo formato de documento requería la creación manual de reglas, definición de zonas y diseño de layouts.
🔁 Reentrenamiento constante: incluso pequeños cambios en la estructura o el diseño de un documento rompían los modelos existentes, obligando a los equipos a reentrenarlos una y otra vez.
📄 Cobertura documental limitada: la mayoría de los proveedores se especializaban en uno o dos dominios (por ejemplo, facturas, recibos, documentos de identidad o pasaportes) y tenían dificultades para manejar otros tipos de documentos.
⚠️ Precisión y falsos positivos: los datos extraídos a menudo contenían errores o inconsistencias, lo que generaba riesgos financieros y de cumplimiento significativos para las organizaciones.
🧑 Alta carga operativa: los modelos requerían entrenamiento continuo, monitoreo, validación y gestión de excepciones.
🚫 Dependencia del factor humano: a pesar de todas las promesas de “automatización”, el procesamiento completamente automático rara vez era posible; siempre se necesitaba una persona para verificar, corregir o aprobar los resultados.
Como resultado, lo que se suponía que era automatización inteligente de documentos se convirtió en un ecosistema complejo y costoso de mantener, basado en plantillas, configuraciones y ciclos de reentrenamiento, muy lejos de la simplicidad y agilidad que las organizaciones buscaban.
Cómo los LLM transforman el procesamiento inteligente de documentos
La aparición de los Large Language Models (LLM) ha transformado por completo el panorama del Procesamiento Inteligente de Documentos (IDP). Mientras que el IDP tradicional se basaba en OCR, aprendizaje automático y procesamiento del lenguaje natural, estas tecnologías solo podían automatizar datos estructurados y semiestructurados, dejando una gran brecha a la hora de comprender documentos complejos o no estructurados.
Hoy, con la tecnología LLM combinada con OCR y Computer Vision, estas brechas finalmente se cierran.
Los LLM aportan una comprensión similar a la humana a la automatización documental, lo que permite a los sistemas no solo “ver” el texto, sino también comprender su significado, contexto e intención.
Así es como los LLM revolucionan todo el proceso de IDP:
🧩 Sin necesidad de plantillas ni configuración
Los LLM pueden adaptarse de forma instantánea a cualquier diseño o estructura documental, sin necesidad de definir zonas, crear reglas ni configurar plantillas.
🤖 Sin entrenamiento de modelos ni supervisión humana
Olvídate del reentrenamiento constante de modelos o de las correcciones humanas en el proceso. Los LLM funcionan desde el primer momento y comprenden nuevos tipos de documentos sin ciclos de entrenamiento adicionales.
⚡Extracción de datos instantánea
La información se extrae de forma inmediata y con plena comprensión del contexto, sin retrasos por preprocesamiento ni necesidad de mapeos de datos complejos.
🎯 Mayor precisión y confiabilidad
Los LLM reducen drásticamente los falsos positivos al interpretar el significado y validar los datos extraídos en función del contexto lógico, y no solo del reconocimiento de patrones.
🔄 Unificación y normalización avanzada de datos
Los LLM pueden convertir automáticamente formatos de datos, por ejemplo, transformar palabras en cifras, monedas o fechas, eliminando la necesidad de posprocesamiento o normalización manual.
🧠 Comprensión semántica del contenido
Más allá de la extracción, los LLM pueden leer y comprender texto no estructurado, como contratos, informes o correspondencia, identificando obligaciones, riesgos e intenciones.
🌍 Cualquier documento, en cualquier formato
Desde notas manuscritas hasta contratos escaneados, facturas, estados financieros o correos electrónicos, los LLM pueden procesar cualquier estructura o formato, algo que durante décadas fue imposible.
En resumen, los LLM han transformado el IDP de una automatización basada en reglas en verdadera inteligencia. La combinación de OCR + Computer Vision + LLM representa la convergencia definitiva, donde las máquinas finalmente pueden “leer, comprender y decidir” como lo haría una persona.
Cómo elDoc aprovecha los LLM para el procesamiento inteligente de documentos y los resultados que ofrece
En elDoc, hemos adoptado plenamente la nueva era del Procesamiento Inteligente de Documentos (IDP) impulsado por LLM, combinando Large Language Models, OCR y Computer Vision para ofrecer una verdadera comprensión de los documentos, y no solo automatización.
A diferencia de los sistemas tradicionales que dependen de plantillas rígidas, configuraciones manuales y supervisión humana, los Asistentes de Documentos con IA de elDoc trabajan de forma inteligente y se adaptan de inmediato a nuevos tipos de documentos, diseños y formatos. El resultado es una comprensión documental fluida, desde la extracción de datos hasta la interpretación, sin necesidad de preentrenamiento ni configuración.
Con los LLM como núcleo, elDoc puede leer, razonar y comprender la información tal como lo haría un experto humano. No se limita a extraer texto, sino que comprende el contexto, las relaciones y la intención detrás de cada documento. Ya sea al procesar facturas, contratos, informes de auditoría o documentos regulatorios, elDoc interpreta el significado de forma inteligente, valida los datos extraídos y los normaliza en formatos coherentes y listos para su uso empresarial.
Cero plantillas y cero configuración
Con elDoc, los documentos se procesan de forma inmediata, independientemente de su estructura, diseño o formato. No necesitas crear plantillas, definir zonas ni configurar mapeos. Lo único que defines es qué datos deseas capturar, simplemente una lista de los campos o valores que te interesan. Una vez que los documentos se cargan, elDoc ejecuta automáticamente OCR y Computer Vision, reconociendo con precisión cada elemento de la página. A continuación, la inteligencia de los LLM toma el control, interpreta el contenido, realiza la indexación automática y captura los datos requeridos con precisión, todo ello sin configuración ni intervención manual.
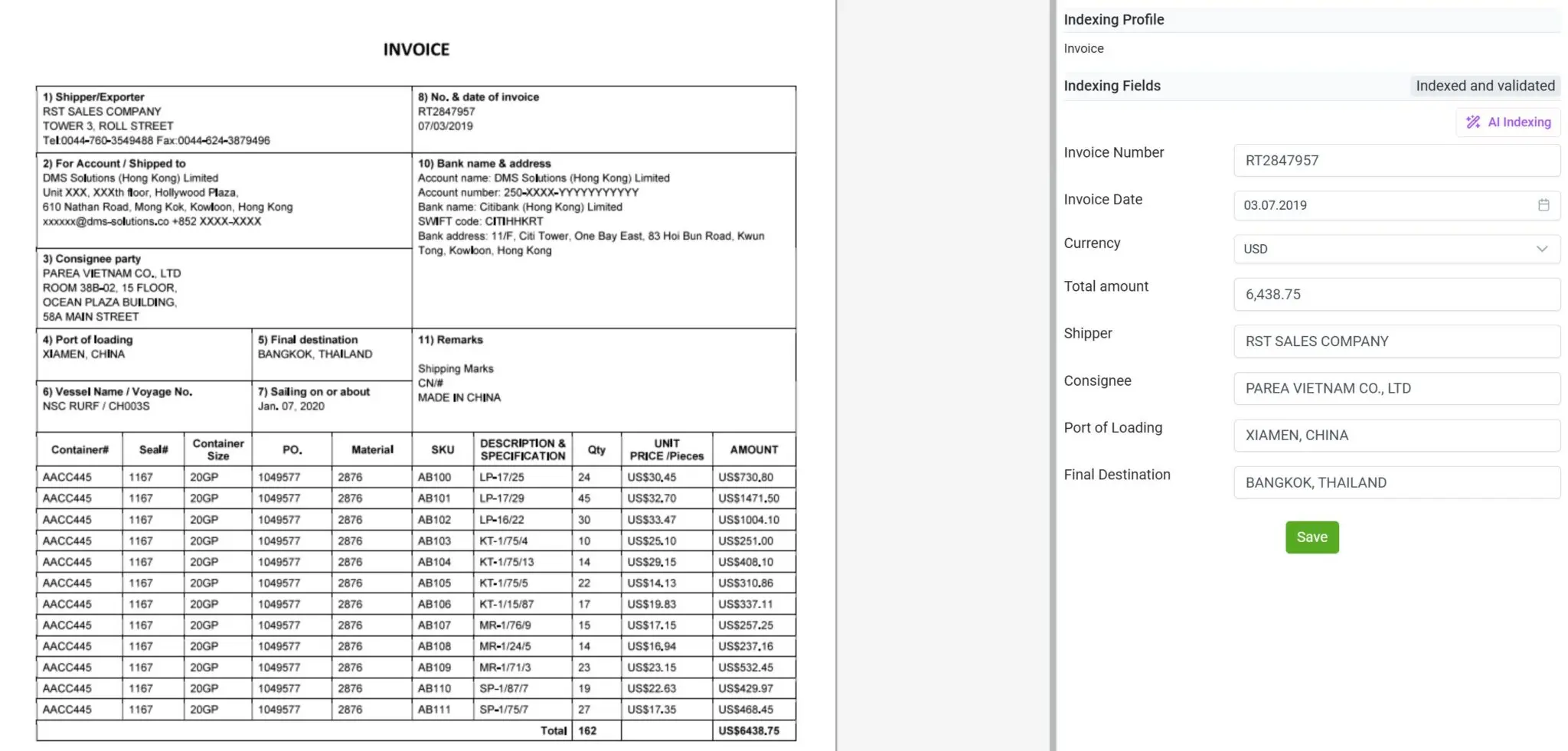
Gestión de una amplia variedad de documentos, no solo facturas
Con elDoc, ya no estás limitado a procesar únicamente facturas o formularios estructurados. La plataforma está diseñada para manejar un amplio espectro de tipos de documentos, incluidos comprobantes de cajeros automáticos, facturas de servicios, correspondencia, contratos, órdenes de compra, estados de cuenta bancarios, transcripciones y muchos más.
Ya sea que el documento esté escaneado, escrito a mano o generado digitalmente, la combinación de OCR, Computer Vision y LLM de elDoc le permite leer, interpretar y extraer datos relevantes de forma inteligente y precisa. Esta versatilidad permite a las organizaciones centralizar todos los flujos de trabajo documentales en una sola plataforma, eliminando la necesidad de múltiples herramientas especializadas y logrando una verdadera inteligencia documental de extremo a extremo en todos los departamentos y casos de uso.
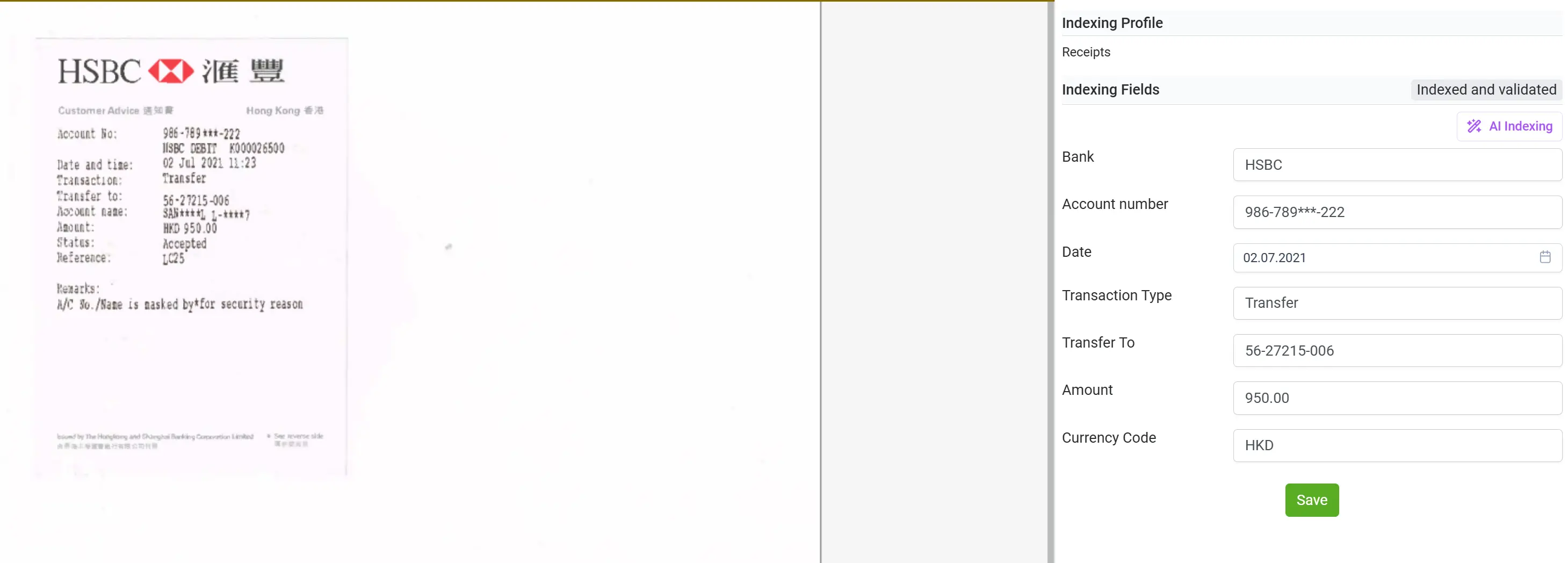
Población automática de datos
Una vez que elDoc completa el proceso de extracción de datos, toda la información capturada se incorpora automáticamente a tu panel de indexación centralizado. Este panel actúa como una capa inteligente y estructurada donde los campos extraídos se organizan y categorizan de forma inmediata, quedando disponibles para su procesamiento posterior. Los datos indexados pueden utilizarse para búsquedas avanzadas, filtrado y análisis entre documentos, lo que permite a los usuarios localizar información rápidamente incluso en grandes volúmenes documentales.
Esta automatización no solo elimina la carga de la entrada manual de datos y la clasificación, sino que también garantiza que toda la información se mantenga coherente, trazable y lista para los flujos de trabajo posteriores, ya sea para auditorías, verificaciones de cumplimiento o analítica avanzada. Con elDoc, tus datos previamente no estructurados se convierten en una base de conocimiento estructurada y totalmente buscable, accesible en cuestión de segundos.
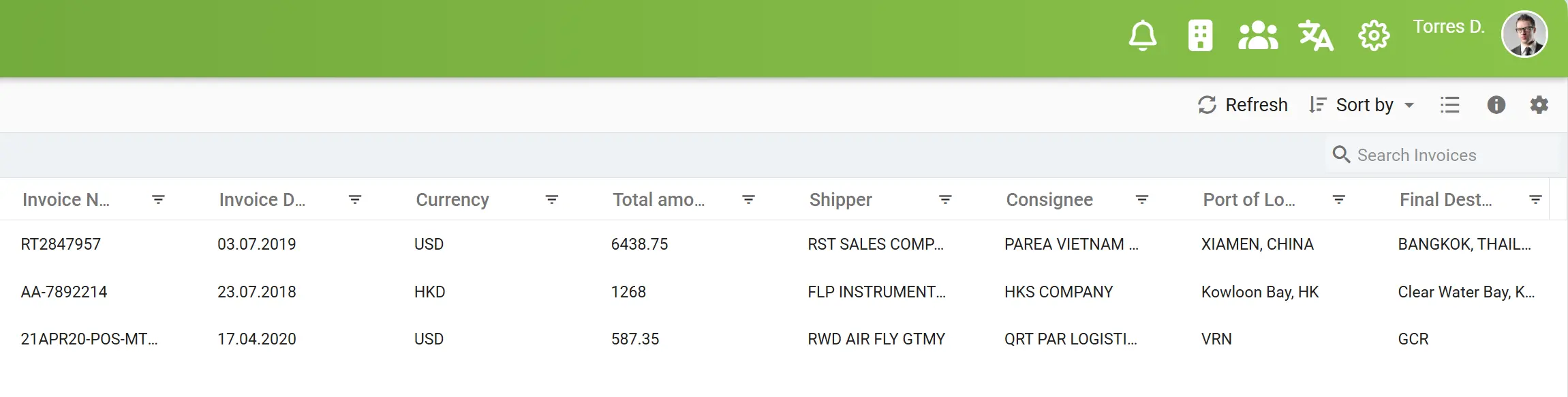
Posprocesamiento de datos con IA y normalización de la información
En el pasado, uno de los mayores desafíos en el procesamiento de documentos era la normalización de datos. Los distintos tipos de documentos y fuentes solían representar la misma información de forma inconsistente, por ejemplo, fechas de facturas escritas con puntos, barras o incluso con palabras, o importes mostrados con diferentes símbolos de moneda y separaciones. Estas inconsistencias hacían que el procesamiento automatizado, la validación y la integración resultaran extremadamente complejos.
Con el posprocesamiento impulsado por IA de elDoc, este problema se elimina por completo. A medida que elDoc realiza la indexación con IA, reconoce, estandariza y convierte automáticamente los datos al formato requerido, ya sea transformando “10.03.2025” en “2025-03-10” o unificando formatos de moneda y valores numéricos en miles de documentos.
Esta normalización inteligente garantiza que cada dato extraído de tus documentos sea limpio, coherente y esté listo para su uso posterior, sin necesidad de correcciones manuales ni scripts adicionales de posprocesamiento. elDoc transforma datos desordenados e inconsistentes en un conjunto de datos estructurado y confiable en el que tus sistemas pueden confiar.
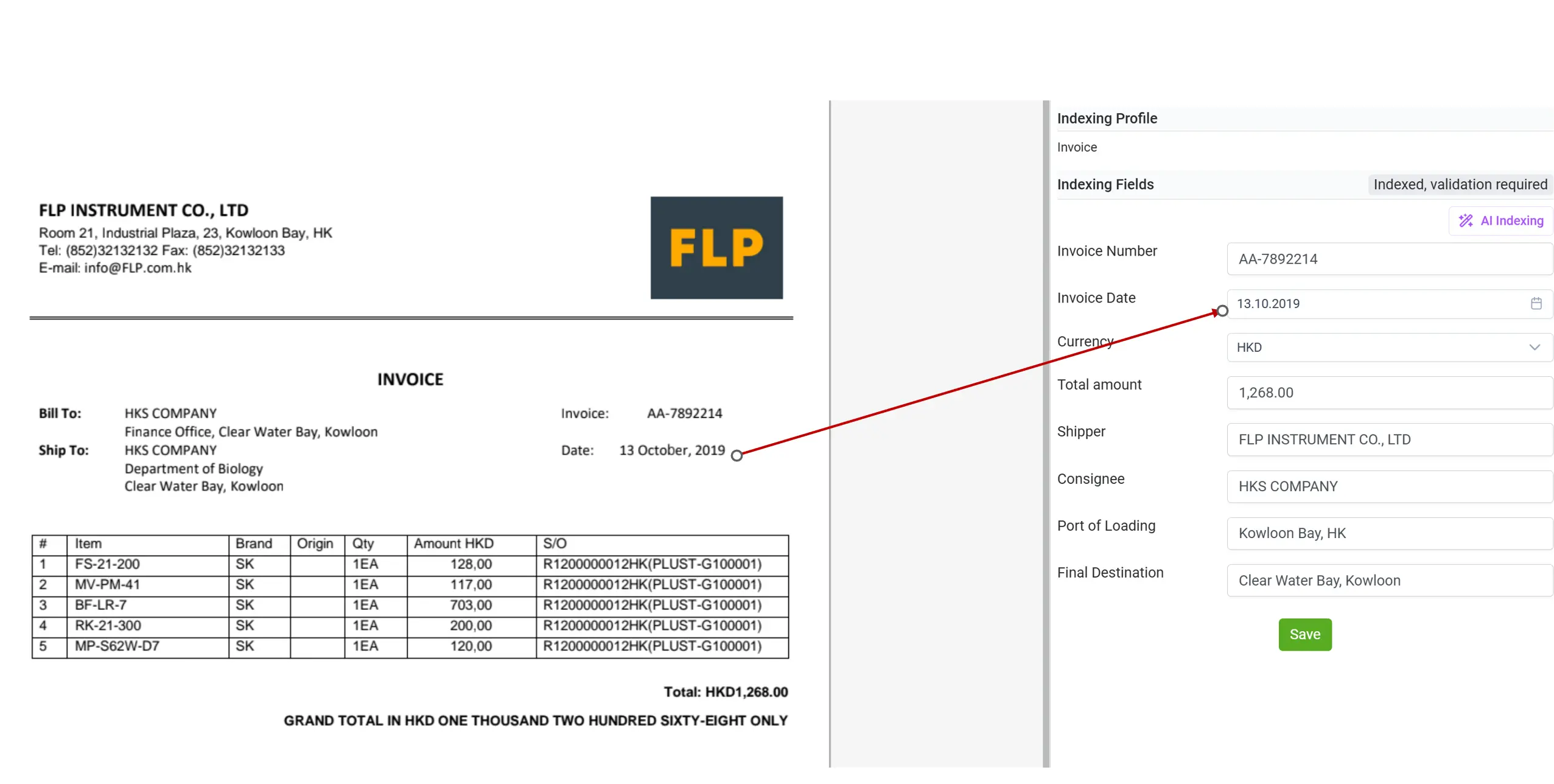
Comprensión de datos no estructurados
Con elDoc, ahora puedes procesar sin esfuerzo datos no estructurados como contratos, informes, correspondencia o cualquier documento de varias páginas que antes requería revisión manual. Ya sea que tus archivos sean documentos digitales basados en texto o imágenes escaneadas, elDoc ejecuta automáticamente OCR para extraer el texto bruto y los elementos visuales.
Una vez digitalizado el contenido, la indexación con IA impulsada por LLM analiza e interpreta la información con una comprensión similar a la humana, identificando entidades, relaciones y contexto incluso a lo largo de cientos de páginas. Incluso cuando la información está escrita en lenguaje natural (por ejemplo, “pago vencido treinta días después de la fecha de la factura”), elDoc puede comprenderla, interpretarla y convertirla en datos estructurados como fechas exactas, importes o condiciones. Esta capacidad avanzada permite a elDoc leer y comprender documentos como lo haría una persona, capturando con precisión el significado, la intención y las relaciones dentro del contenido no estructurado, y transformándolo de forma inmediata en insights estructurados y accionables.

Una nueva era de capacidades IDP para cada necesidad empresarial
Aunque el IDP impulsado por LLM se centra en la automatización inteligente, todavía existen numerosos aspectos prácticos y operativos que deben abordarse para garantizar un rendimiento de nivel empresarial. elDoc ha sido diseñado para gestionar todo esto de forma fluida.
En los casos en los que se requiere validación de datos, elDoc ofrece una Estación de Validación dedicada: una interfaz intuitiva que permite a los usuarios revisar y confirmar los datos extraídos según las expectativas o las reglas de negocio antes de finalizar los resultados. Esto garantiza la máxima precisión de los datos y el cumplimiento normativo, especialmente en documentos críticos como estados financieros, contratos o informes regulatorios.
Una vez validados, los datos pueden exportarse fácilmente en múltiples formatos, como JSON o CSV, para su integración con sistemas posteriores como ERP, CRM o plataformas de analítica.
elDoc también ofrece una flexibilidad total en los flujos de procesamiento. Los usuarios pueden procesar documentos de forma individual, simplemente indicando:
«Por favor, extrae e indexa los datos de este documento»,
o bien gestionar cargas de trabajo a escala empresarial, en las que miles de archivos se cargan en bloque para su clasificación, extracción e indexación inteligente automatizadas.
Esta flexibilidad permite que elDoc se adapte tanto a casos de uso ad hoc como a entornos empresariales de gran escala, ajustándose a las necesidades específicas de cada organización.
Como resultado, elDoc inaugura una nueva era del Procesamiento Inteligente de Documentos, una que rompe con las limitaciones de los sistemas heredados y, por fin, ofrece lo que las empresas siempre han necesitado: velocidad, precisión, adaptabilidad y verdadera inteligencia en cada flujo de trabajo documental.