基於 LLM 的智能文件處理:無需模板、無需設定,只需真正的智慧

在過去的數十年間,不斷湧現的新技術浪潮承諾要實現從頭到尾的文件處理自動化,這一領域被稱為「智能文件處理」(Intelligent Document Processing,簡稱 IDP)。
為了應對這一挑戰,出現了數十家供應商,他們都聲稱能在各種複雜的文件類型中實現全面自動化。然而,沒有任何一家能達到真正的完美。為什麼?因為現實世界中的文件極其多樣、非結構化且充滿不可預測性。
傳統基於 OCR、AI、機器學習與自然語言處理(NLP)的 IDP 解決方案,面臨以下主要挑戰:
⚙️ 設定與模板配置繁瑣:每一種新的文件格式都需要手動建立規則、定義區域與設計版面。
🔁 需要不斷重新訓練:即使文件結構或版面稍有變化,也會導致現有模型失效,迫使團隊反覆進行再訓練。
📄 文件範圍有限:大多數供應商僅專注於一兩種文件類型(例如發票、帳單、身份證或護照),難以處理其他類型的文件。
⚠️ 準確度與誤報問題:提取的資料常出現錯誤或不一致,為企業帶來嚴重的財務與合規風險。
🧑 運行成本高:模型需要持續訓練、監控、驗證並處理異常情況。
🚫 對人工干預的依賴:儘管宣稱「自動化」,但真正的全自動處理幾乎不可能;人工仍需驗證、修正或批准結果。
因此,原本應該是「智能文件自動化」的體系,最終演變成一個由模板、設定與重訓週期構成的複雜且維護繁重的生態系統,與企業追求的簡單與靈活背道而馳。
大型語言模型(LLM)如何改變智能文件處理
大型語言模型(LLM)的出現,徹底改變了智能文件處理(IDP)的整個格局。傳統的 IDP 主要依賴 OCR、機器學習與自然語言處理等技術,但這些技術僅能自動化處理結構化與半結構化資料,對於複雜或非結構化文件的理解仍存在巨大缺口。
如今,結合 LLM 技術、OCR 與電腦視覺,這些缺口終於得以彌補。LLM 為文件自動化帶來類似人類的理解能力,使系統不僅能「看見」文字,更能理解其背後的意義、脈絡與意圖。
以下是 LLM 如何徹底革新整個 IDP 流程:
🧩 無需模板或配置
LLM 能即時適應任何文件的版面或結構,無需區域劃分、規則建立或模板設定。
🤖 無需機器學習訓練或人工監督
告別無止盡的模型再訓練與人工校正。LLM 可直接運作,無需額外訓練即可理解新文件類型。
⚡ 即時資料擷取
能在完整脈絡下即時擷取資訊,無需前置處理或複雜的資料映射。
🎯 更高的準確性與可靠性
LLM 透過理解語意與邏輯脈絡來驗證資料,而非僅靠模式識別,大幅降低誤判率。
🔄 複雜資料的統一與標準化
LLM 能自動轉換資料格式,例如將文字轉換為數字、貨幣或日期,無需後期處理或人工標準化。
🧠 語意層級的內容理解
不僅限於資料擷取,LLM 還能閱讀與理解非結構化文字,如合約、報告或通信,識別義務、風險與意圖。
🌍 任何文件,任何格式
從手寫筆記到掃描合約、發票、財務報表或電子郵件,LLM 都能處理各種結構與格式:這在過去幾十年幾乎是不可能的。
簡而言之,LLM 已將 IDP 從基於規則的自動化轉變為真正的智能。OCR、電腦視覺與 LLM 的結合代表了最終的融合,機器終於能像人類一樣「閱讀、理解並作出判斷」。
elDoc 如何運用 LLM 進行智能文件處理,並帶來卓越成果
在 elDoc,我們全面擁抱由 LLM 驅動的智能文件處理(IDP)新時代,結合大型語言模型(LLM)、OCR 與電腦視覺,實現真正的文件理解,而非僅僅是自動化。
與依賴僵化模板、手動設定及人工監督的傳統系統不同,elDoc 的 AI 文件智能員工能靈活工作,立即適應新的文件類型、版面與格式。其結果是流暢無縫的文件理解,從資料擷取到內容詮釋,無需任何預先訓練或配置。
以 LLM 為核心,elDoc 能像人類專家一樣閱讀、推理並理解資訊。它不僅僅是擷取文字,更能理解每份文件背後的脈絡、關聯與意圖。無論是處理發票、合約、稽核報告或合規文件,elDoc 都能智能地詮釋其意義,驗證所擷取的資料,並將其標準化為可直接用於業務的統一格式。
零模板與零設定
使用 elDoc,文件可即時處理,無論其結構、版面或格式為何。您無需建立模板、定義區域或設定對應關係。您只需指定想擷取的資料、只要提供您關注的欄位或數值清單即可。文件上傳後,elDoc 會自動執行 OCR 與電腦視覺分析,準確識別頁面上的每個元素。隨後,大型語言模型智慧接手,解讀內容、自動建立索引並精準擷取所需資料,全程無需手動設定或干預。
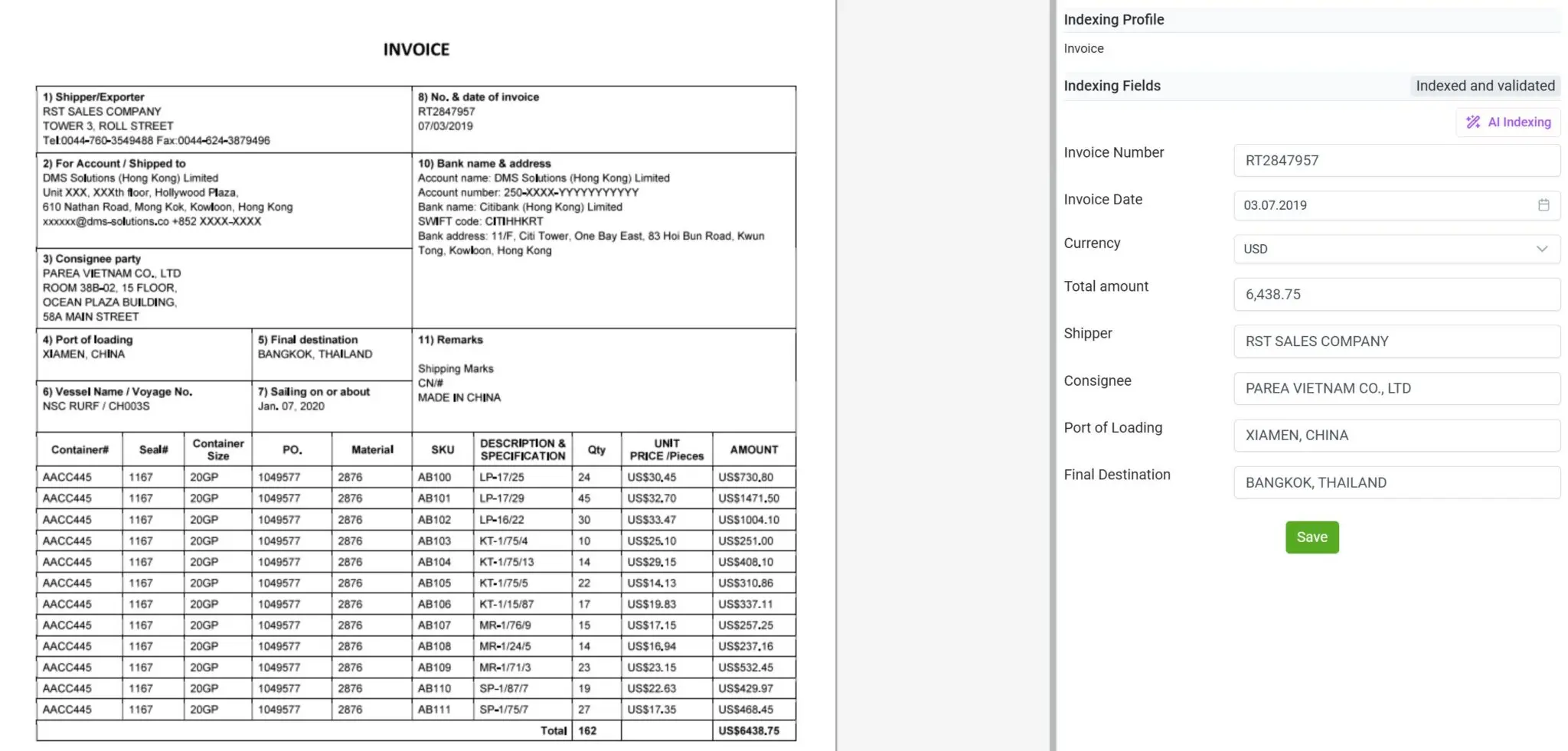
處理多樣化文件,不僅限於發票
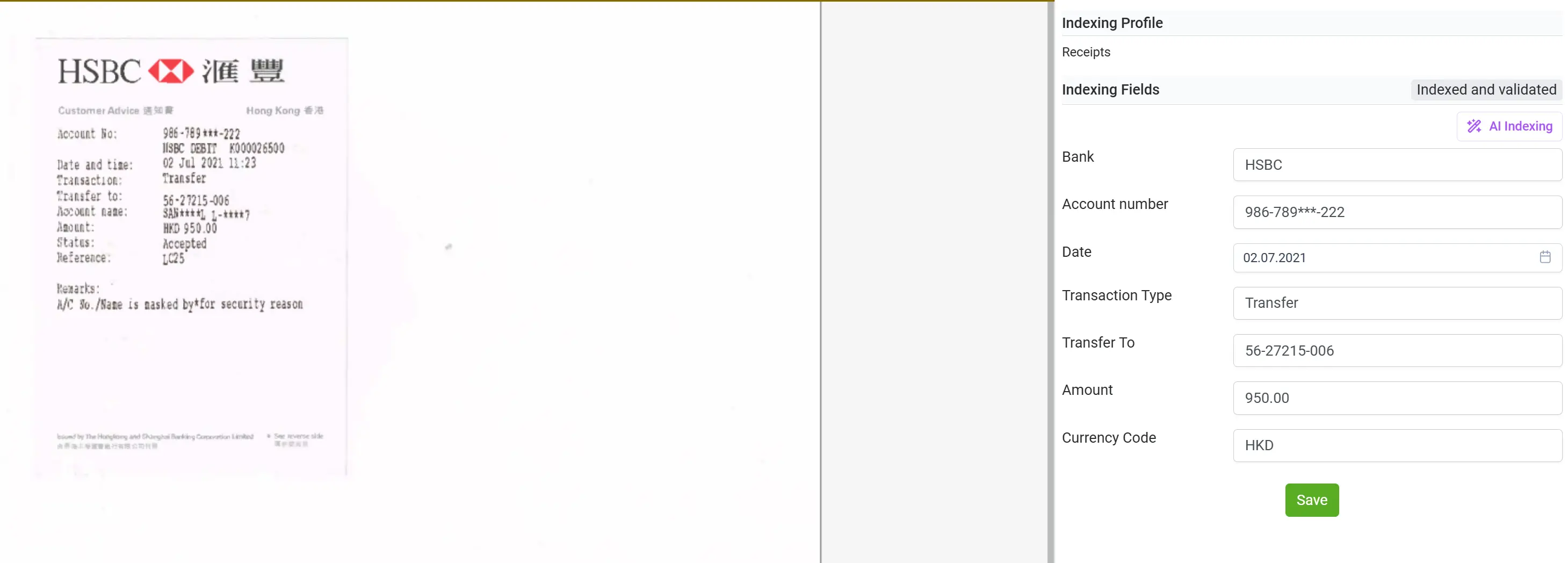
使用 elDoc,您不再受限於僅能處理發票或結構化表單。該平台專為應對各類文件而設計、包括 ATM 收據、水電費帳單、往來信件、合約、採購訂單、銀行對帳單、成績單等多種文件格式。
無論文件是掃描版、手寫版還是數位生成,elDoc 結合了 OCR、電腦視覺與 LLM 技術,能夠智慧地閱讀、理解並精確提取相關資料。這種高度的靈活性使組織能在單一平台上集中管理所有文件流程,無需多種專用工具,真正實現跨部門與多場景的端到端文件智能化處理。
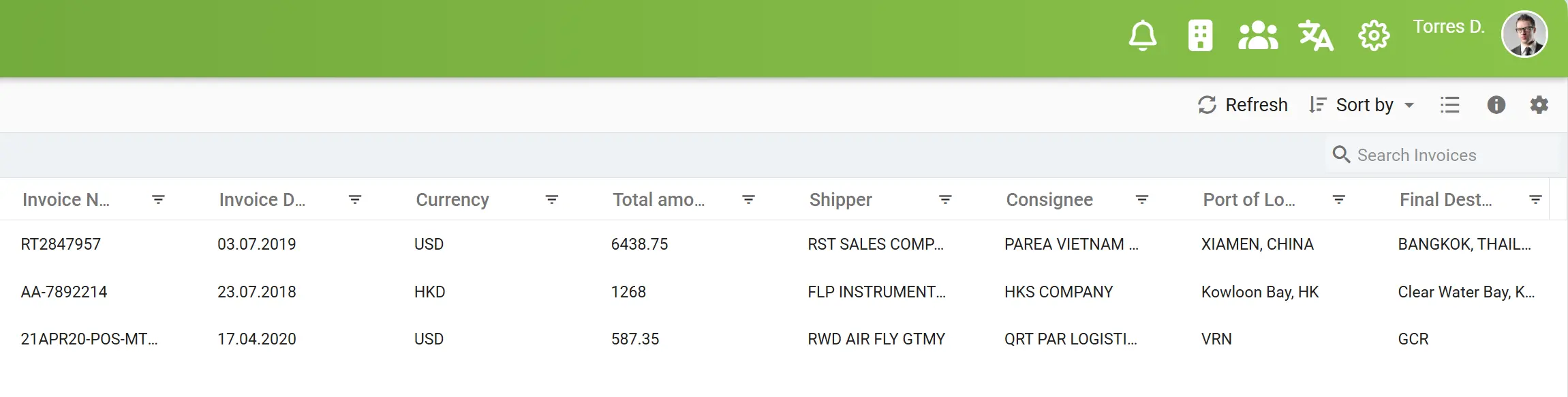
自動化資料填充
當 elDoc 完成資料擷取流程後,所有捕捉到的資訊將自動填入您的集中索引面板。這個面板就像一個智慧化、結構化的層級,讓已擷取的欄位即時分類、歸納並可供後續處理使用。這些索引化資料可用於強大的搜尋、篩選與跨文件分析,幫助使用者快速在大量文件中定位所需資訊。
這項自動化不僅消除了手動輸入與分類的需求,還確保所有資訊保持一致、可追溯,並隨時可用於後續流程,無論是審計、合規檢查或進階分析。透過 elDoc,您原本無結構的資料將轉化為可全文搜尋的結構化知識庫,只需數秒即可存取。
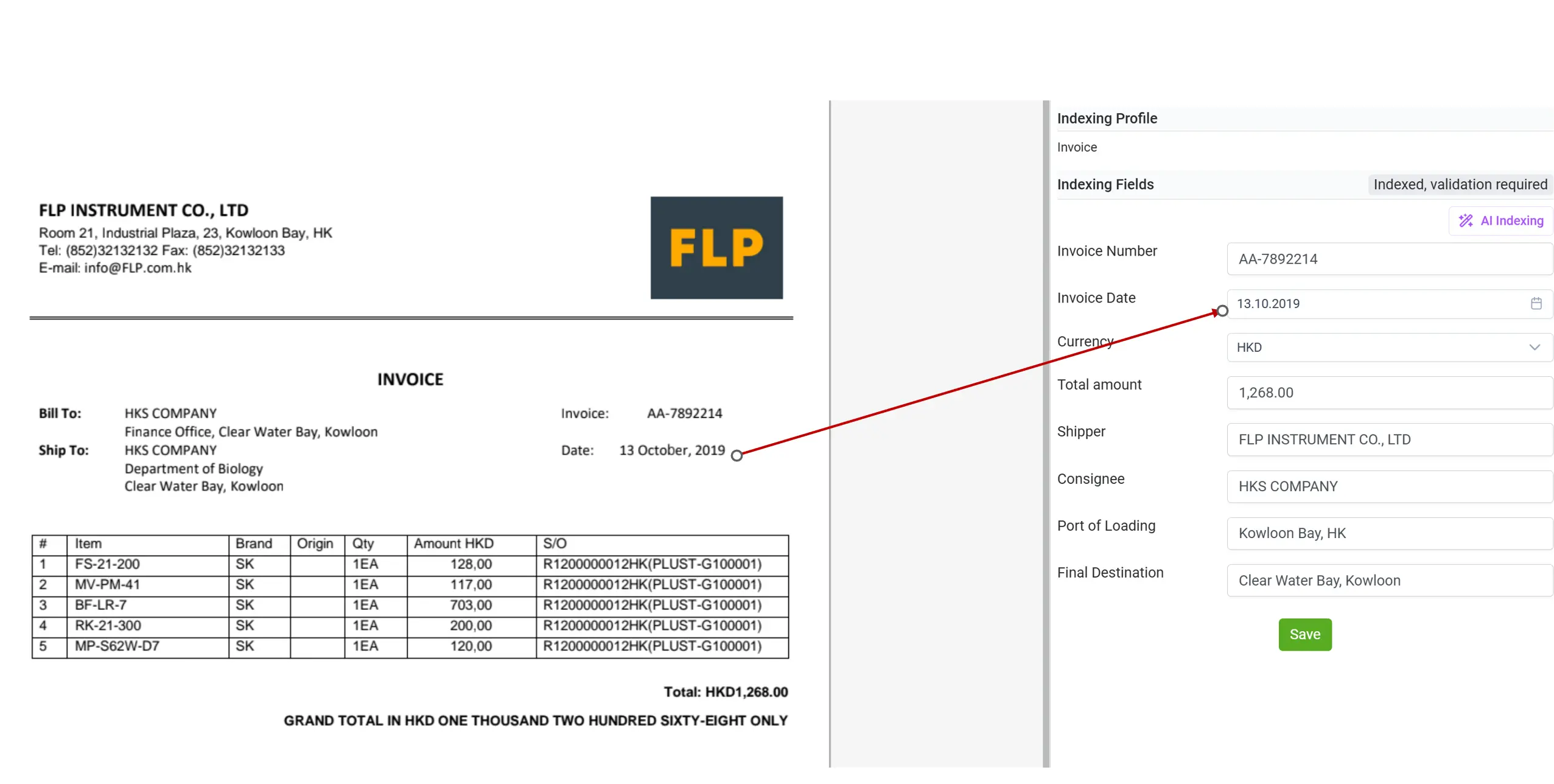
AI 資料後處理與資料標準化
在過去,文件處理中最大的挑戰之一就是資料標準化。不同的文件類型與來源經常以不一致的方式呈現相同的資料:例如發票日期可能使用點號、斜線,甚至以文字表示;金額也可能以不同的貨幣符號或間距顯示。這些不一致性使自動化處理、驗證與整合變得極為困難。
有了 elDoc 的 AI 驅動後處理,這個問題迎刃而解。當 elDoc 執行 AI 索引時,它會自動識別、標準化並轉換資料至所需格式,無論是將「10.03.2025」轉換為「2025-03-10」,還是統一數千份文件中的貨幣與數值格式。
這種智能標準化確保從文件中擷取的每一筆資訊都乾淨、一致,並可直接用於後續流程,無需人工修正或額外的後處理腳本。elDoc 將混亂、不一致的資料轉化為可靠且結構化的資料集,讓您的系統能安心信任與使用。
理解非結構化資料
使用 elDoc,您現在可以輕鬆處理非結構化資料,例如合約、報告、信件或任何以往需要人工審閱的多頁文件。無論您的檔案是以文字為主,還是掃描影像,elDoc 都會自動執行 OCR(光學字元辨識),以擷取原始文字與視覺元素。
當內容被數位化後,由 大型語言模型(LLM) 驅動的 AI 索引 會以近似人類的理解方式分析並詮釋資訊,從數百頁內容中識別實體、關聯與語境。即使資料以自然語言撰寫(例如:「發票日期後三十天內付款」),elDoc 也能理解、解析並將其轉換為結構化資料,例如精確的日期、金額或條款。這項先進能力讓 elDoc 能夠像人類一樣閱讀與理解文件,精準捕捉非結構化內容中的意義、意圖與關聯,並即時將其轉化為結構化、可行的洞察資訊。

滿足各種業務需求的 IDP 新時代
儘管基於 LLM 的智能文件處理(IDP)專注於智慧自動化,但若要確保企業級效能,仍需解決許多實際與操作層面的挑戰。elDoc 正是為此而設計,能夠流暢且無縫地應對這些需求。
在需要資料驗證的情況下,elDoc 提供專屬的 驗證工作台(Validation Station):一個直覺化的介面,讓使用者能在最終確認前,根據預期或業務規則檢視並核對擷取的資料。這確保了資料的最高準確性與合規性,特別是對於財務報表、合約或監管文件等關鍵檔案。
驗證完成後,資料可輕鬆以多種格式匯出,例如 JSON 或 CSV,並與下游系統(如 ERP、CRM 或分析平台)整合使用。
elDoc 亦提供高度靈活的文件處理流程。使用者可以單獨處理文件,只需簡單輸入指令:
「請從此文件中擷取並建立索引。」或處理企業級工作負載,將成千上萬份文件批次上傳,進行自動分類、資料擷取與智能索引。
這種靈活性使 elDoc 能夠同時滿足臨時性需求與大規模企業環境,完美契合每個組織的特定業務情境。
因此,elDoc 開啟了智能文件處理的新時代、打破傳統系統的限制,終於實現企業長久以來所追求的目標:在每個文件流程中兼具 速度、準確性、靈活性與真正的智慧化。