使用 elDoc 進行完全離線的文件問答(Fully Offline RAG)

在過去兩年中,數以百萬計的使用者體驗過 ChatGPT、Gemini 以及其他類似的 GenAI 助手的強大功能。這些工具快速、直覺且令人印象深刻。使用者可以上傳文件、提出問題,並在幾秒鐘內獲得答案。但有經驗的使用者很快就會注意到一個根本性限制:
這些工具會在雲端處理您的文件,超出您的直接控制範圍。
對於一般使用者而言,這可能可以接受;但對於任何敏感資料,則完全不可行。
雲端 GenAI 助手的隱性安全與合規問題
當文件上傳至公共 GenAI 服務時,它們便不再停留在您的本地環境中。處理會在第三方基礎設施上進行,通常跨越多個地區,此時資料存放地、保留政策以及二次使用情況並非總是完全透明。存取控管通常為通用設計,面向一般消費者,而非企業級治理,導致合規與資訊安全團隊的可見性有限,審計追蹤薄弱,對敏感資訊的處理幾乎無法掌控。
在處理財務資料、法律合約、健康與保險文件、審計作業底稿,以及企業內部知識時,這些缺口會造成嚴重風險。對於需遵守 GDPR、財務法規或特定行業合規標準的組織而言,這種缺乏控制的情況往往足以阻止公共 GenAI 工具的採用。
雲端 GenAI 助手的擴展性問題鮮少被討論
當規模擴大時,另一個問題便不可避免:每次需要分析時上傳數 TB 的文件幾乎毫無意義。大多數組織已在檔案共享、文件管理系統、私有雲儲存及內部存檔中維護大型且安全的文件庫。反覆將相同資料送至外部 AI 服務既低效率、成本高、速度慢,還增加不必要的操作風險。一個更實際的做法,是讓文件安全地保留在組織內部邊界中,透過 AI 進行一次索引,並在需要洞察時智能查詢。
文件問答的「完全離線 RAG」究竟意味著什麼,以及是否真正可行
當人們聽到「與文件對話」時,常會認為流程的某些部分必須依賴網際網路或外部 AI 服務。實際上,完全離線的檢索增強生成(RAG)不僅可行,而且在平台設計正確的情況下,已可在生產環境中實現。
RAG 的核心是其架構模式,使 GenAI 能夠可靠地處理私有文件。系統不是要求語言模型「猜測」答案,而是先從可信的內部文件庫中檢索最相關的段落,再根據檢索到的內容生成答案。這正是文件問答能夠準確、可解釋並適用於真實商業場景的原因。
讓解決方案達到完全離線的,不是聊天介面本身,而是整個流程的每個步驟都完全在您的基礎設施中運行,無論是內部部署或私有雲環境。文件內容、元資料、向量嵌入、提示或回應均不會傳送至外部 API。
沒錯,這完全可行,而 elDoc 的設計正是為了讓這種方式落地可用。
elDoc 如何實現完全離線的文件問答
elDoc 是一個 GenAI 平台,可完全部署於內部部署、隔離網路環境或私有雲中。它以完整的自包含系統形式交付,包含所有實現離線文件理解、檢索及對話互動所需的元件。
流程從文件擷取與理解開始。elDoc 整合多種 OCR 引擎,以應對真實文件的多樣性與不一致性。依據部署需求,可使用通用的開源 OCR 進行一般資料擷取、高精度 OCR 處理複雜版面、具內建版面理解的視覺語言模型,以及適用於大規模處理的超高速多語 OCR。這種彈性使組織能在準確性、速度與嚴格離線要求之間取得平衡。
在任何語言模型分析文件之前,elDoc 會先應用電腦視覺層對文件影像進行清理、標準化與優化。傾斜的掃描、對比度低、背景雜訊、表格、印章與簽名等都會被修正並結構化,確保下游 AI 模型使用高品質輸入。
文件優化完成後,本地運行的大型語言模型可提供真正的語意理解。這些模型不僅提取文字,還能解析段落、表格與章節間的意義、上下文、關聯與意圖。正因如此,使用者能以自然語言提出問題,而非僅依賴關鍵字搜尋。
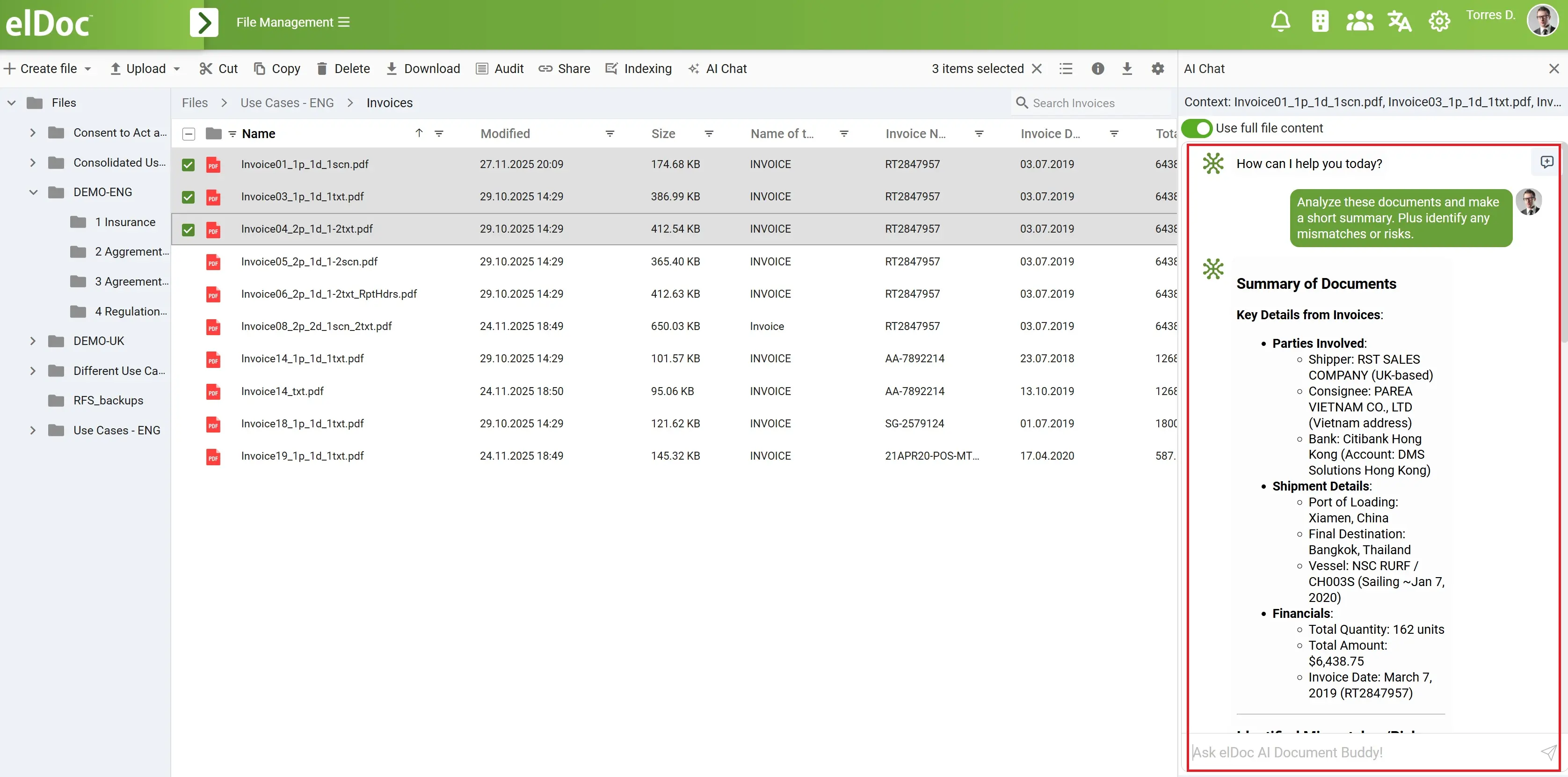
與文件對話:從個人使用到企業級智慧
一旦部署 elDoc,文件不再是存放於資料夾中的靜態檔案,而是成為安全、互動式的知識庫,使用者可以以自然語言查詢。在完全離線且受控的環境中,使用者無需逐一打開文件、手動搜尋或將資料匯出至外部工具,只需與文件對話即可。
對於個人使用者,elDoc 在處理高度敏感的個人文件時提供清晰與信心。使用者可以檢視健康記錄、保險政策或法律協議,而無需將私人資料暴露給公共 GenAI 平台。常見的查詢範例包括:
「請分析我的健康記錄,並標示任何可能影響治療或保險理賠的遺漏資訊或不一致之處。」
「根據我的保險政策,這項理賠是否涵蓋,是否有任何排除條款或我應注意的條件?」
在中小型組織中,elDoc 成為財務、營運及法務團隊的日常生產力工具。團隊無需手動審查文件,而是可以一次查詢整個文件集,即時獲得涵蓋發票、合約與信函的洞察。常見查詢範例包括:
「檢視所有發票與合約,找出逾期付款、不一致條款,以及約定金額與帳單金額之間的任何差異。」
在企業級應用中,elDoc 可在跨部門與多地區安全地實現大規模文件智慧,同時強制執行嚴格的存取控管與審計可追蹤性。財務、法務、稽核及合規團隊能提出複雜的跨文件查詢,否則需花費數日或數週的人工處理。常見查詢範例包括:
「比對所有合約版本,標示與終止、責任及罰則相關,且偏離標準政策的條款。」
「檢視過去三年的審計底稿,標示重大變動、異常或缺失的佐證資料。」
無論任何使用情境,體驗始終如一:文件安全保留在您的環境內,權限自動執行,每個答案皆基於核准文件的實際內容。elDoc 為真實文件提供對話式 GenAI,而不影響隱私、安全或控制權。

存儲、檢索與語意智慧—全部離線
完全離線的 RAG 同時需要穩健的存儲與檢索層。elDoc 使用可擴展的文件存儲系統,高效管理大型檔案與豐富的元資料,確保文件可長期存取、版本可控且可審計。在此基礎上,專用的向量資料庫會在本地生成語意嵌入,賦予文件「意義」,使其可超越簡單關鍵字進行搜尋。即便使用者以不精確或自然語言提問,系統仍能檢索相關內容。
為了精確匹配與高速篩選,elDoc 將語意檢索與全文搜尋功能結合。這種混合檢索方式可可靠地應用於合約、發票、報表、政策文件以及掃描文件,且資料始終保留在您的環境內,無需外部傳輸。
部署 elDoc 並開始與文件對話有多簡單?
儘管實現完全離線的文件問答需要複雜架構,包括安全存儲、OCR 引擎、電腦視覺、本地 LLM、語意搜尋與治理,elDoc 的部署卻刻意設計得簡單。複雜性內建於平台,而不會轉嫁給使用者或 IT 團隊。
elDoc 以容器化解決方案交付,可在不同環境中一致部署。無論您是個人使用者、小型團隊或大型企業,部署方式皆相同:在內部部署基礎設施或私有雲環境中執行容器。無需組裝獨立元件、整合多個供應商或管理脆弱流程,所有安全對話文件所需功能皆已打包完備。
一旦部署完成,即可立即開始。您可根據可用硬體資源連接偏好的大型語言模型,無論是僅 CPU、GPU 加速,或混合架構。elDoc 對模型無依賴,允許組織選擇最符合其效能、成本與安全需求的 LLM,同時保持推論完全本地化。
之後,使用者只需上傳文件或連接現有資料庫,觸發索引,即可開始對話。新文件可隨時新增,並自動納入未來查詢,而無需重新處理既有資料。從首次部署到有意義的文件對話,elDoc 將傳統上複雜的 GenAI 基礎架構專案轉化為實用、可重複且安全的方案。
簡而言之,elDoc 讓企業級、完全離線的文件問答變得可及,而不犧牲控制權、彈性或部署便利性。
elDoc 社群版:為您的文件提供本地 RAG
為了讓完全離線的文件智慧不僅限於大型企業使用,elDoc 也提供社群版。此版本專為個人使用者、開發者及小型團隊設計,他們希望在筆記型電腦、工作站或小型伺服器上本地運行基於 RAG 的文件問答,而無需將文件傳送到雲端。
社群版提供安全對話文件所需的核心功能。使用者可以上傳文件、本地建立索引,並對整個文件集提出自然語言問題。所有處理皆在本地設備或使用者的私人環境中完成,確保資料完全私密並可控。它不依賴外部 AI 服務,非常適合在敏感文件上實驗 GenAI。
即便體積輕巧,社群版仍遵循與企業平台相同的架構原則。文件透過 OCR 與電腦視覺處理後,建立本地語意索引,並透過由本地語言模型支持的 RAG 流程進行查詢。使用者只需連接與可用硬體資源(CPU 或 GPU)匹配的 LLM,即可開始對話。
elDoc 社群版非常適合:
- 小型團隊在本地運行
- 在企業部署前測試文件問答工作流程
- 注重隱私的使用者,希望在不使用雲端的情況下獲得 AI 協助
使用 elDoc 社群版後,強大的文件問答不再局限於複雜的企業部署。它將安全、本地、RAG 驅動的智慧帶給任何希望私密且高效處理文件的人。
elDoc 社群版附帶內容:完整本地 AI 堆疊
elDoc 社群版並非簡化版或示範版本,它是一個功能完整的本地 RAG 平台,包含從文件擷取、理解、搜尋到對話所需的完整 AI 流程,所有運行皆在您的機器或本地環境中完成。
儘管底層架構複雜,所有元件皆已預先整合與編排,使用者體驗順暢:上傳文件、建立一次索引,即可開始提問,無需模板、手動設定或依賴雲端。
以下為 elDoc 社群版所包含的完整堆疊。
OCR:將影像與 PDF 轉換為文字
大多數文件,尤其是發票,多以掃描件、影像或不可搜尋的 PDF 形式存在。OCR 是第一個關鍵步驟,將這些檔案轉換為機器可讀文字,使 AI 能真正理解內容。
在社群版中,elDoc 配備可離線運行的 OCR 引擎,包括:
- Tesseract OCR — 用於一般文字擷取的開源 OCR
- PaddleOCR — 超高速、多語言 OCR,針對多樣版面與格式進行優化
- Qwen3-VL — 具備版面理解功能的視覺語言 OCR,用於處理複雜文件
這些引擎可從雜訊多、品質低或多語文件中精確擷取文字,且所有處理皆保留在本地。
電腦視覺:清理與標準化文件
在將 OCR 輸出交給 AI 模型之前,elDoc 會先應用專用的電腦視覺預處理層,此步驟大幅提升準確性與可靠性。
電腦視覺層會對傾斜或旋轉頁面進行校正與對齊,進行去噪與對比度增強,並標準化版面。透過標準化混亂的實際文件,elDoc 確保下游 AI 模型使用乾淨、結構化的輸入,這是成功 RAG 的關鍵因素之一。
LLM:真正理解內容
elDoc 社群版的核心是一個本地運行的大型語言模型。此模型作為推理引擎,以比人類更快速、更一致的方式理解文件內容。
LLM 會解析非結構化文字、表格與章節的意義、上下文與意圖。它可擷取關鍵欄位,如總額、日期、稅額、供應商與明細項目,無需模板即可分類文件,並檢測不一致或異常。正因如此,使用者可提出自然語言查詢,而非依賴死板規則或關鍵字搜尋。
使用者只需連接符合其硬體資源(CPU 或 GPU)的 LLM,elDoc 將處理其餘流程。
RAG:連結跨文件的上下文
檢索增強生成(RAG)將單一文件轉化為互相連結的知識庫。在 elDoc 社群版中,RAG 使系統能檢索文件間的相關段落,並將其作為 AI 回答的依據。這讓使用者能跨文件驗證資料、檢測不一致,並提出跨多文件的複雜問題,例如比較發票、核對合約一致性,或統整資料集趨勢。
RAG 確保每個答案皆基於真實文件內容,而非假設或錯誤生成。
MongoDB:可擴展文件存儲
MongoDB 是 elDoc 的主要文件與元資料存儲系統。它能高效管理大型檔案與結構化擷取結果,即便文件結構差異很大。其彈性結構、快速檢索與可靠性,使其成為本地文件智慧工作流程的理想選擇,也是 elDoc 結構化資料層的核心。
Qdrant:語意智慧與向量搜尋
Qdrant 透過本地生成的向量嵌入提供語意理解,使 elDoc 能超越關鍵字找出文件意義,包括偵測相似文件、重複文件及文件間關聯。此語意層對智慧檢索、文件群集及精確 RAG 問答至關重要。
Apache Solr:高速全文搜尋
Apache Solr 補充語意搜尋,提供企業級關鍵字索引。它能即時進行全文搜尋、篩選、排序與大型文件集的導覽。
Solr 與 Qdrant 結合形成混合搜尋引擎:關鍵字精準結合語意理解與 AI 推理。
驗證站:分數、信心水準與例外管理
除了擷取功能外,elDoc 還包括驗證站,用以評估 AI 結果的品質與可靠性。
此層會為擷取欄位分配信心分數,標示低信心或衝突資料,並識別需要人工審查的例外。驗證規則可跨文件應用,以檢測欄位缺失、不一致數值、閾值違規,或相關文件間不匹配(例如發票與合約或政策)。驗證站實現人機協作流程,確保 AI 輸出透明、可審計且可投入生產,而非黑箱結果。
穩健的安全框架:角色、權限與治理
安全性從 elDoc 的設計之初就被納入,即便在社群版中亦然。平台內建基於角色的存取控制(RBAC)框架,明確定義使用者與團隊的角色與責任。權限可套用於工作區、資料夾、文件及功能層級,包括對 GenAI 功能的存取,例如索引、對話、匯出與檔案分享。
elDoc 支援多因素身份驗證(MFA)以確保安全存取,並可整合企業身份提供者,包括 Active Directory(AD)或目錄型驗證系統。這確保了身份管理的一致性、使用者控制集中化,並符合現有安全政策。
所有操作皆被紀錄,建立明確的審計追蹤,用於文件存取、AI 互動與驗證決策,對合規、治理與信任至關重要。
除了安全與治理外,elDoc 支援高可用性部署。得益於其容器化架構,elDoc 可部署於叢集或複製配置中,以消除單點故障。這使組織能確保持續存取文件智慧、在多節點間擴展工作負載,並在維護或基礎設施中斷期間維持營運韌性。
綜合以上能力,elDoc 不僅適合用於實驗,也能為個人使用者到關鍵任務的企業部署提供安全、可靠且持續可用的文件智慧。