Зчитування даних за допомогою LLM, OCR, Computer Vision: розгортання локально або в хмарі

Протягом понад десяти років витягування даних залишається найзатребуванішою функцією в рішеннях інтелектуальної обробки документів (IDP). На ринку з’явилася велика кількість постачальників, кожен із яких обіцяв автоматизацію на базі штучного інтелекту, здатну зчитувати ключові дані з документів.
Однак більшість так і не змогли реалізувати обіцянку справжньої інтелектуальної автоматизації. Системи й надалі вимагали нескінченного налаштування шаблонів, ручного навчання та жорсткої конфігурації для кожного нового типу документа — від рахунків і контрактів до звітів і форм.
Сучасним підприємствам уже недостатньо традиційних систем OCR чи рушіїв, заснованих на правилах — їм потрібне справжнє розуміння. З появою великих мовних моделей (LLM) зчитування даних увійшло в нову еру. LLM здатні читати, інтерпретувати та витягувати структуровану інформацію практично з будь-якого документа — без крихких шаблонів, попереднього навчання чи ручного налаштування.
Незалежно від того, йдеться про рахунки, контракти, банківські виписки, поліси чи навіть об’ємне листування, LLM розуміють контекст, взаємозв’язки та смислове наповнення даних.
Для багатьох організацій, особливо у регульованих галузях і корпоративному середовищі, конфіденційність даних та контроль над ними є безкомпромісними вимогами. Команди прагнуть використовувати потужність LLM та штучного інтелекту, але робити це в межах власної інфраструктури, повністю під своїм управлінням і контролем. І саме тут elDoc змінює правила гри. elDoc надає повну потужність зчитування даних на основі LLM, дозволяючи розгортати рішення на 100% локально або безпечно в хмарі — з однаковим рівнем інтелекту, продуктивності та автоматизації.
У цій публікації пояснюється, як працює зчитування даних за допомогою LLM, чим воно відрізняється від традиційних систем IDP, а також як безпечно розгорнути його — локально, у хмарі або в гібридному середовищі.
LLM змінює підхід до зчитування даних з документів: чому це важливо?
У elDoc нас завжди мотивують інновації та прагнення впроваджувати найсучасніші технології у реальну бізнес-автоматизацію. З появою великих мовних моделей (LLM) стало очевидно, що ці моделі здатні повністю змінити підхід до зчитування та розуміння даних. Традиційні системи OCR та рушії, засновані на правилах, могли лише розпізнавати символи, але не контекст. LLM, натомість, здатні читати, аналізувати та осмислювати, відкриваючи нову еру справжнього інтелектуального розуміння документів.
На відміну від застарілих систем, які покладаються на жорсткі шаблони або тривалі цикли налаштування, витягування даних на основі LLM у elDoc працює миттєво з широким спектром типів документів — навіть коли змінюються макети, мови чи формати. Система динамічно адаптується до кожного документа, розуміючи намір, взаємозв’язки та смисловий контекст тексту.
Ось чому зчитування даних на основі LLM змінює уявлення про можливе:
- Без шаблонів: працює без зусиль із різними макетами, постачальниками та форматами — включно з PDF, сканами, зображеннями та електронними листами — без ручного налаштування або попередньо визначених зон.
- Структура + Семантика: виходить за межі поверхневого тексту та глибоко розуміє зміст документа, витягуючи пари «ключ–значення» і контекстне значення. Наприклад, може виявляти розбіжності між умовами рахунку та пунктом контракту.
- Швидке отримання результату: перехід від пілотного проєкту до продуктивного середовища займає дні, а не місяці. Жодного тривалого навчання чи складного налаштування — лише миттєвий результат.
- Розширюваність за задумом: легко додавайте нові поля, типи документів або бізнес-правила за допомогою простих інструкцій природною мовою. Модель миттєво розуміє ваш намір.
Завдяки поєднанню LLM, Retrieval-Augmented Generation (RAG) та просунутого фреймворку інтелектуальної обробки документів elDoc, організації нарешті отримують те, що індустрія обіцяла роками — справжню автоматизацію, яка читає, розуміє та витягує дані так само, як це робить людина, але з надлюдською швидкістю.
Основні можливості elDoc для зчитування даних
В платформі elDoc зчитування даних — це не просто розпізнавання тексту, а його осмислення.
Платформа elDoc поєднує Computer Vision, OCR, інтелект LLM та механізм аналітичного мислення на основі RAG, створюючи єдиний, цілісний конвеєр для справжнього інтелектуального розуміння документів.
Нижче наведено основні компоненти, які роблять це можливим:
🧠 1. Попередня обробка з використанням Комп’ютерного Зору (Computer Vision)
Перш ніж розпочати процес зчитування даних, elDoc використовує передові технології комп’ютерного зору для нормалізації зображень документів. Якщо документ завантажено з неправильним поворотом, перекошений або містить візуальні артефакти, такі як тіні чи розмиття, — elDoc автоматично виявляє та виправляє ці недоліки. Це гарантує, що процес витягування даних починається з найчистішого та найточнішого візуального представлення, що значно підвищує точність OCR і LLM-обробки.
🔍 2. Оптичне розпізнавання тексту (OCR)
Після нормалізації зображення технологія OCR перетворює його на машинозчитуваний текст.
elDoc підтримує розпізнавання як друкованого, так і рукописного тексту, що забезпечує безперервне витягування даних зі сканованих документів, PDF-файлів, квитанцій, форм та зображень.
На цьому етапі візуальні дані перетворюються на структурований цифровий контент, готовий до інтелектуальної обробки та аналізу за допомогою LLM.

🧩 3. LLM — Розуміння документів на рівні людини
Велика мовна модель (LLM) є серцем конвеєра зчитування даних у elDoc. Вона не просто «читає» — вона розуміє контекст, взаємозв’язки та семантику всередині ваших документів. LLM ідентифікує ключові поля, сутності та шаблони, такі як суми, дати, IBAN, назви компаній або пункти договорів — навіть якщо структура документа змінюється між різними постачальниками чи форматами. Модель також здатна до міждокументного аналізу, наприклад, перевіряє, чи збігаються умови оплати у рахунку з положеннями відповідного контракту чи політики.
Окрім зчитування даних, інтелектуальні можливості elDoc на основі LLM дозволяють автоматично стандартизувати та нормалізувати дані. Документи часто містять невідповідності — різні формати дат, валюти, способи найменування чи відображення полів, які можуть відрізнятися залежно від постачальника, регіону або типу документа.
З elDoc цей хаос перетворюється на впорядкованість. LLM розуміє контекст і зміст, що дозволяє їй інтерпретувати та конвертувати різні формати у єдиний структурований стандарт.
Для прикладу:
- Формати дат, як-от «01/02/2025», «Feb 1, 2025» чи «2025-02-01», розпізнаються як одна й та сама дата та автоматично стандартизуються.
- Валютні значення, наприклад «USD 1,000», «1,000$» або «US Dollars – One Thousand», нормалізуються до єдиного узгодженого формату.
Така нормалізація гарантує, що зчитані дані завжди будуть узгодженими, чистими та готовими до аналітики, незалежно від походження чи структури документа.
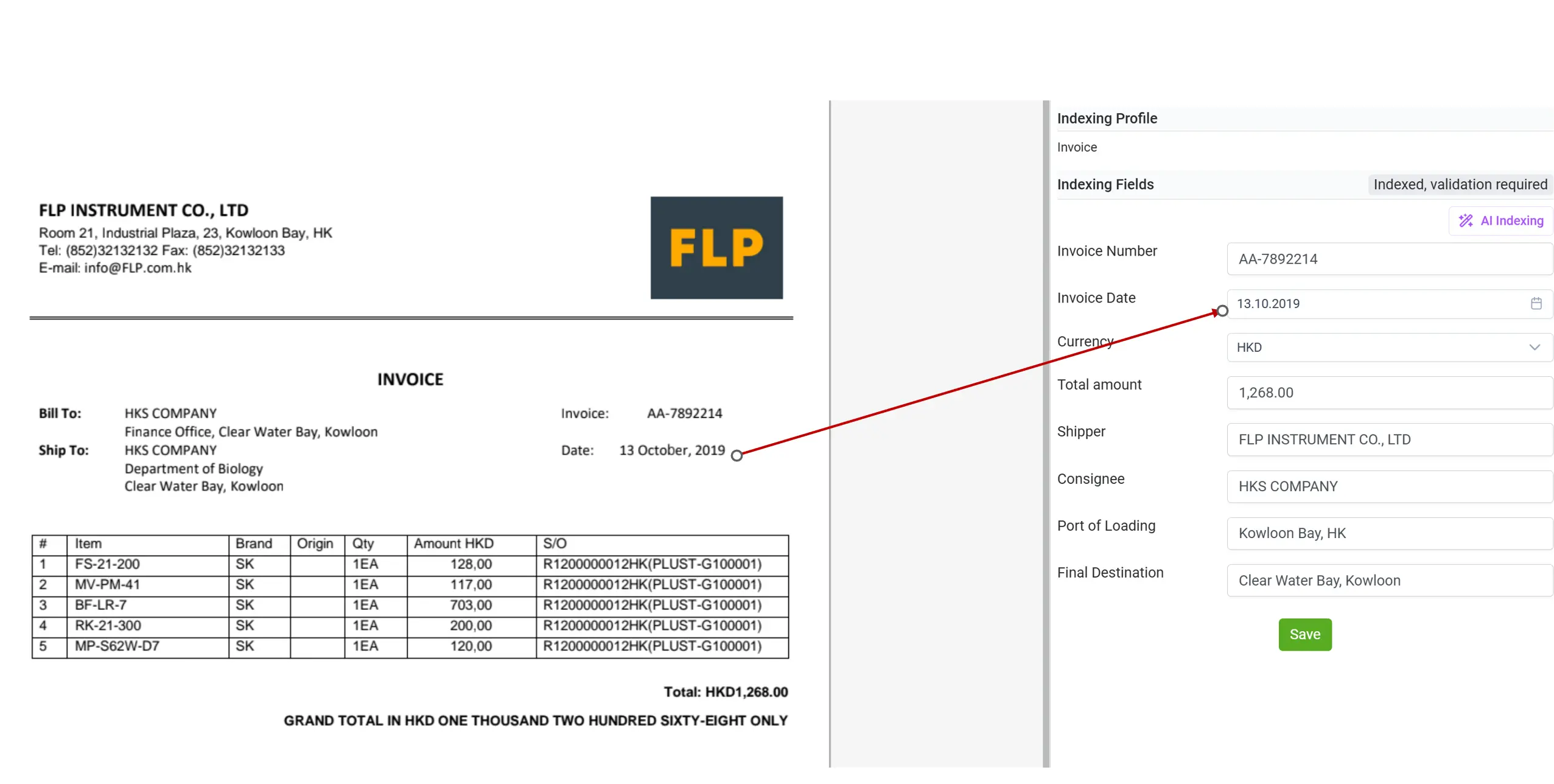
🔗 4. RAG — Механізм глибинного аналізу та логічного поєднання документів
elDoc інтегрує технологію Retrieval-Augmented Generation (RAG), щоб ще більше розширити можливості LLM.
RAG дозволяє системі знаходити відповідні сторінки, пункти або пов’язані документи, на яких базується її розуміння, і надавати висновки, засновані на фактах.
Наприклад, ви можете запитати elDoc:
«Підтверди, чи умови оплати в цьому рахунку відповідають умовам у Генеральній угоді про надання послуг (MSA)». RAG знаходить відповідний пункт у контракті та порівнює його з даними рахунку, надаючи контекстну, перевірену відповідь. Таке поєднання пошуку та аналітичного мислення створює глибокий інтелект документів — значно потужніший за базове витягування даних.
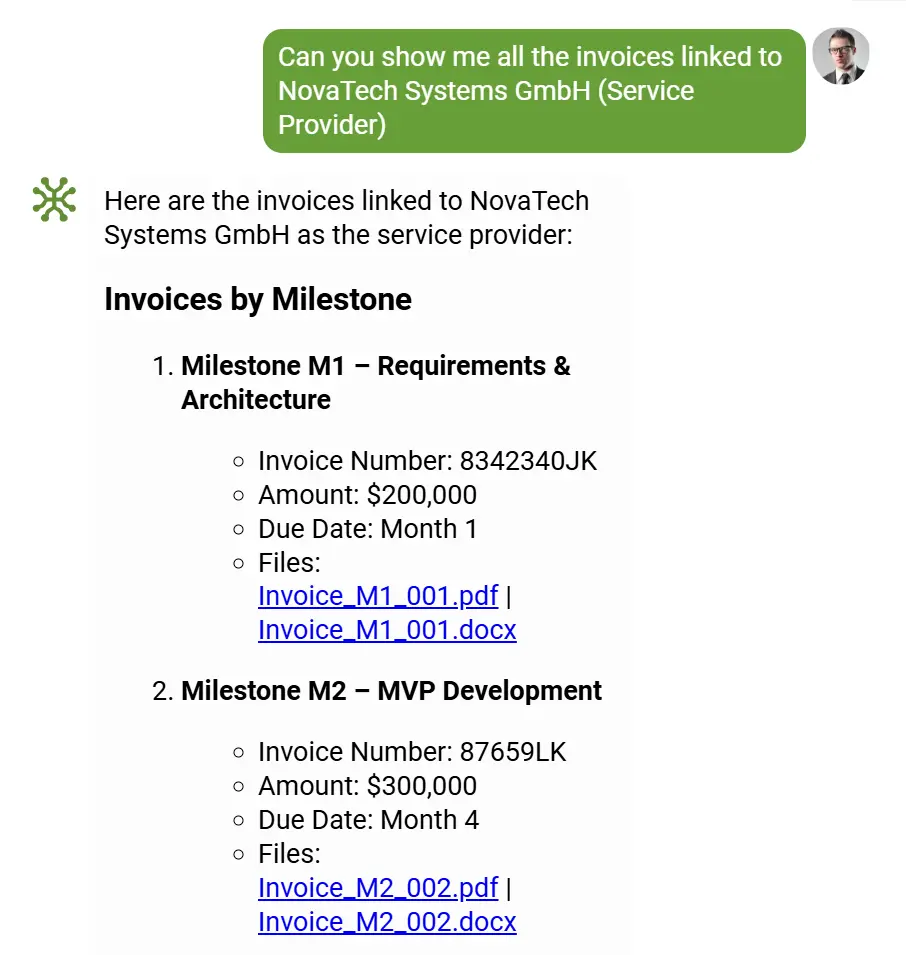
👩💻 5. Механізм перевірки за участю людини (HITL)
Навіть за надзвичайно високої точності витягування даних на основі LLM, у elDoc розуміють, що людська перевірка все ще відіграє важливу роль — особливо у критичних або регульованих середовищах.
Саме тому elDoc пропонує як опціональну можливість інтуїтивний інтерфейс Human-in-the-Loop (HITL), створений для поєднання ефективності автоматизації з точністю експертного контролю.
У цьому інтерфейсі користувачі можуть:
- Instantly see side-by-side comparisons between the original document and the extracted data.
- Миттєво переглядати порівняння оригінального документа та витягнутих даних поруч.
- Додавати відсутню інформацію або робити примітки щодо особливих випадків, які потребують специфічної бізнес-логіки.
Кожна взаємодія фіксується для повного відстеження, що гарантує відповідність вимогам і готовність до аудиту.
Для організацій, що працюють із складними або чутливими документами (такими як фінансові звіти, юридичні контракти чи комплаєнс-звіти), HITL гарантує, що жодне критичне рішення не буде ухвалене без участі людини, водночас забезпечуючи швидкість і масштабованість ШІ.
Простіше кажучи, HITL у elDoc дає змогу отримати найкраще з обох світів: Експертне судження та контроль людини, і Швидкість та інтелект автоматизації.
📤 6. Експорт і розумне зберігання даних — від статичних документів до живих знань
Після того як документи оброблено, перевірено та погоджено, elDoc перетворює зчитану інформацію на структуровані, готові до дії дані. Ці дані можуть безперешкодно надходити до будь-якої наступної системи, аналітичного рівня або бізнес-процесу. Лише один клік або автоматичний тригер у робочому процесі — і elDoc забезпечує миттєвий експорт у різних форматах, таких як CSV, JSON, Excel, або через API-інтеграцію з вашими наявними системами — ERP, CRM, бухгалтерською платформою чи сховищем даних.
Це означає, що витягнуті дані одразу можуть використовуватись у ваших бізнес-процесах, звітах та аналітичних панелях без ручного втручання чи додаткового форматування.
Але elDoc виходить далеко за межі простого експорту.
Усі витягнуті та перевірені дані автоматично зберігаються у розумному сховищі даних elDoc — це безпечний, структурований і доступний для запитів шар знань, створений для безперервного AI-аналізу та міждокументного інтелекту.
У межах цього інтелектуального сховища даних ваша організація має можливість:
- 🔎 Perform AI-driven queries using natural language (e.g., “Find all invoices above €5,000 issued by Vendor A last quarter”).
- 🔗 Виконувати AI-запити природною мовою (наприклад: «Знайди всі рахунки понад €5,000, виставлені постачальником А за минулий квартал»).
- 📊 Виконувати міждокументну аналітику — наприклад, порівнювати умови оплати в різних договорах або виявляти повторювані невідповідності в даних.
- 🧠 Проводити подальший аналіз на основі LLM, наприклад: попросити elDoc «показати всі рахунки, де ставка ПДВ не відповідає умовам контракту» або «виявити постачальників із дубльованими позиціями виставлення рахунків».
Цей інтелектуальний шар зберігання даних фактично перетворює ваші колись статичні документи на живі, взаємопов’язані знання — завжди доступні, придатні для пошуку та готові до глибшого аналізу чи автоматизації.
Moreover, data governance and compliance are built into every step:
- Крім того, управління даними та дотримання вимог інтегровані на кожному етапі процесу:
- Кожна зміна, експорт або запит на доступ повністю відстежується — для забезпечення аудиту та відповідності вимогам.
- Адміністратори можуть визначати політики зберігання, правила доступу та права на експорт — для кожної ролі або підрозділу окремо.
По суті, elDoc не просто зчитує та зберігає ваші дані — він підносить їх на новий рівень.
Ваші документальні дані перетворюються на постійну, динамічну базу інтелектуальних знань, яка надає змогу і людям, і штучному інтелекту ухвалювати швидші, розумніші та більш обґрунтовані бізнес-рішення.
🔒 Зчитування даних за допомогою LLM у elDoc — доступно локально та в хмарі
Поява генеративного ШІ (GenAI) та великих мовних моделей (LLM) докорінно змінила світ обробки документів. Тепер організації можуть витягувати, розуміти та аналізувати дані з інтелектом, подібним до людського, і з урахуванням контексту. Однак, попри колосальний потенціал цих технологій, не всі компанії готові передавати свої конфіденційні документи у сторонні хмарні системи — і це цілком зрозуміло.
Підприємства у сферах фінансів, державного управління, охорони здоров’я та права працюють із високочутливою інформацією — контрактами, звітами, комплаєнс-документами, персональними даними — де суверенітет даних, безпека та конфіденційність є беззаперечними вимогами.
Для таких організацій питання полягає не в тому, чи може ШІ допомогти, а як зробити це безпечно — у межах власної інфраструктури.
Саме тут elDoc вирізняється з-поміж інших. elDoc забезпечує справжнє витягування даних на основі LLM та інтелектуальну обробку документів із використанням Generative AI — повністю доступні локально (on-premise), без передачі жодних даних за межі вашого середовища. Ви отримуєте ті самі потужні можливості штучного інтелекту, аналітичне мислення та високу продуктивність, що й у хмарній версії, але розгорнуті у вашій власній безпечній інфраструктурі та під повним вашим контролем.
Використовуючи elDoc On-Premise, ви можете:
- 🏢 Запускати всі процеси LLM та RAG локально — безпосередньо на ваших серверах або у приватній хмарі, гарантуючи, що жоден документ, текст чи метадані не передаються за межі вашої інфраструктури.
- 🔐 Maintain full control over your data residency, encryption keys, and access management.
- ⚙️ Зберігати повний контроль над розміщенням даних, ключами шифрування та управлінням доступом.
- 🚀 Отримувати таку саму продуктивність, як у хмарних розгортаннях, завдяки оптимізованій оркестрації GPU/CPU та легкій архітектурі інференсу.
- 🧩 Поєднувати гібридний інтелект — використовувати локальне розгортання для обробки чутливих даних, водночас підключаючись до хмари для масштабної аналітики або роботи з менш конфіденційними типами документів.
Такий підхід поєднує найкраще з обох світів — потужність Generative AI із впевненістю у повному локальному контролі та управлінні.
На практиці локальне розгортання elDoc надає підприємствам можливість:
- Розгортати LLM-систему для інтелектуальної обробки документів безпосередньо за власним фаєрволом,
- Безпечно інтегруватися з внутрішніми системами — ERP, CRM та іншими корпоративними рішеннями,
- Забезпечувати відповідність суворим нормативним вимогам (GDPR, HIPAA, SOC 2, ISO 27001),
- І водночас отримувати швидке, «людиноподібне» розуміння та витягування даних із будь-якого формату документа.
Незалежно від того, чи обираєте ви локальне розгортання, хмару або гібридний варіант — elDoc гарантує однакову функціональність, масштабованість і точність. Різниця лише в одному: ви самі вирішуєте, де зберігаються ваші дані. Адже справжня інтелектуальна автоматизація не повинна ставати загрозою для конфіденційності даних — і з elDoc цього ніколи не станеться.