Сортування та Організація документів за допомогою штучного інтелекту / LLM

У сучасному світі, де даних стає дедалі більше, організації щодня опрацьовують тисячі документів: контракти, рахунки-фактури, кадрові файли, політики, замовлення, звіти, електронні листи та багато іншого. Протягом багатьох років бізнеси всіх розмірів — від великих міжнародних корпорацій до малих компаній і навіть окремих фахівців — мріяли про рішення, яке могло б автоматично впоратися з цим хаосом.
Чому?
Адже обробляти документи вручну — це повільно, одноманітно, неефективно й часто виснажливо. Сортування, найменування, тегування, розкладання по папках, перевірка та організація документів забирають години продуктивного часу, при цьому залишаючи простір для людських помилок. Це дорого, неефективно й практично неможливо масштабувати.
Гарна новина?
Сучасні системи інтелектуальної обробки документів на базі ШІ та LLM, такі як elDoc, нарешті роблять цю мрію досяжною, автоматизуючи класифікацію, впорядкування та структурування даних з винятковою швидкістю й точністю.
Цей блог пояснює, як технології ШІ та LLM змінюють класифікацію й організацію документів, а також чому підхід elDoc, створений на базі штучного інтелекту, є справжнім проривом для будь-якої організації з великим обсягом документів, яка прагне позбутися ручної роботи та перейти до справжньої інтелектуальної автоматизації.
Чому раніше це було неможливо?
Протягом десятиліть багато постачальників намагалися автоматизувати обробку документів, використовуючи комбінацію OCR, штучного інтелекту, машинного навчання та особливо технологій NLP. І хоча ці інструменти давали часткові покращення, вони ніколи не вирішували проблему повністю. Навіть у поєднанні всіх цих технологій традиційні AI-стеки все ще не мали справжнього інтелекту.
Вони вимагали:
- безкінечного створення шаблонів,
- continuous model training,
- постійного навчання моделей,
- жорстких правил, та
- постійного обслуговування.
Системи не могли по-справжньому “розуміти” документи так, як це роблять люди. Якщо змінювалося розташування елементів документа, якщо текст був неструктурованим, форматування — непослідовним, або якщо вміст був довгим і складним — автоматизація одразу виходила з ладу. Саме тому організації роками були змушені виконувати ручні перевірки, ручне сортування та ручну валідацію.
LLM повністю змінили ситуацію
Поява великих мовних моделей повністю змінила те, що машини здатні розуміти.
LLM тепер можуть:
- розуміти контекст,
- інтерпретувати значення,
- читати неструктурований текст,
- зчитувати ключові дані,
- порівнювати пов’язані документи,
- та здійснювати логічні висновки на основі великих обсягів тексту — майже як людина.
Те, що було неможливим для систем на основі OCR, ML чи NLP, раптом стало досяжним. Завдяки LLM здатність аналізувати, класифікувати та впорядковувати документи більше не залежить від шаблонів чи навчання. Система миттєво розуміє намір, семантику та структуру документа — навіть якщо він неохайний, непослідовний, відсканований або неструктурований. Цей прорив і робить сучасні платформи штучного інтелекту, такі як elDoc, здатними забезпечувати справді інтелектуальну обробку документів уже сьогодні.
Що все ж потрібно для досягнення справжньої AI-класифікації та сортування?
Хоча LLM докорінно змінили розуміння документів, справжня класифікація на основі ШІ все одно потребує узгодженої технологічної екосистеми. Кожен рівень відіграє ключову роль у перетворенні сирих, неструктурованих документів на структуровані, придатні до пошуку й інтелектуально впорядковані знання.
🔤 1. OCR — перетворення зображень і PDF у текст
Більшість документів надходять у вигляді сканів, зображень або PDF-файлів без можливості пошуку. OCR перетворює їх на машинозчитуваний текст, щоб ШІ міг фактично «читати» вміст.
✔ Зчитує текст із зображень
✔ Робить PDF-файли придатними для пошуку
✔ Дозволяє подальшу обробку ШІ
🖼️ 2. Computer Vision — очищення та нормалізація документа
Перш ніж ШІ почне щось інтерпретувати, Computer Vision готує документ:
✔ Вирівнює та коригує перекоси сторінок
✔ Покращує якість низькороздільних сканів
✔ Виявляє таблиці, підписи, печатки
✔ Розуміє макет і структуру документа
Цей етап забезпечує точність навіть для неохайних, повернутих або зашумлених документів.
🧠 3. LLM — справжнє розуміння вмісту
Велика мовна модель є «мозком» інтелектуальної класифікації:
✔ Розуміє значення та контекст
✔ Розпізнає типи документів
✔ Інтерпретує неструктурований текст
✔ Видобуває ключову інформацію
✔ Класифікує документи так, як це робить людина
Це той рівень інтелекту, якого старі системи ML/NLP ніколи не могли досягти.
🔎 4. RAG — поєднання контексту між документами
Retrieval-Augmented Generation (RAG) підвищує рівень інтелекту, використовуючи ваші реальні документи як базу знань.
✔ Знаходить пов’язані документи
✔ Виконує міждокументний аналіз
✔ Виявляє невідповідності (наприклад, між рахунком-фактурою та контрактом)
✔ Відповідає на складні запити, використовуючи кілька файлів
RAG перетворює вашу бібліотеку документів на динамічну систему знань.
🗄️ 5. Структуроване зберігання — метадані та файли
Документоорієнтована база даних (наприклад, MongoDB) як основний рушій зберігання документів
✔ Ефективно зберігає великі файли
✔ Безшовно керує всіма пов’язаними метаданими
Це дає змогу обробляти величезні набори даних (кілька терабайтів) зі стабільною й передбачуваною продуктивністю.
🧭 6. Векторна база даних — семантичне розуміння та пошук схожості
Векторна база даних (наприклад, Qdrant) є необхідною для сучасного AI-пошуку та кластеризації.
✔ Семантичний пошук («знайти подібні документи»)
✔ Виявлення дублікатів
✔ Групування та оцінка схожості
✔ Автоматичне пов’язування пов’язаних файлів
Саме це дозволяє ШІ впорядковувати документи інтелектуально, а не просто в алфавітному порядку.
📁 7. Платформа для спільної роботи з документами — місце, де все поєднується
Нарешті, усі ці технології мають працювати в єдиній платформі, де користувачі можуть:
✔ Переглядати, шукати та впорядковувати файли
✔ Перевіряти зчитані дані (HITL — участь людини)
✔ Безпечно ділитися документами
✔ Запускати робочі процеси
✔ Керувати версіями та дозволами
✔ Виконувати AI-пошук та аналітику
Створити все з нуля чи використати elDoc для миттєвої AI-класифікації та сортування файлів?
Досягнення справжньої класифікації та впорядкування документів на основі ШІ вимагає складної екосистеми технологій: OCR, Computer Vision, LLM, RAG, структурованого зберігання, векторного пошуку, рушіїв робочих процесів, журналів аудиту, засобів безпеки та повноцінного комплексу інструментів для спільної роботи. Створити все це самостійно — не лише довго, але й надзвичайно дорого та технічно складно.
Саме для цього й було створено elDoc.
Маючи десятиліття досвіду у створенні надійних рішень для інтелектуальної обробки документів, elDoc уже містить усі ключові компоненти, необхідні для сучасної AI-автоматизації документів. Його архітектура спеціально розроблена для відповідності вимогам сучасних технологій ШІ та LLM — готова з першого дня, без шаблонів, без навчання та без складного налаштування.
elDoc об’єднує в одній єдиній, безшовній платформі:
🔒 MongoDB
Високомасштабовану документоорієнтовану базу даних, розроблену для зберігання великих обсягів структурованих і напівструктурованих даних, отриманих із документів. Вона забезпечує швидкий пошук, гнучку еволюцію схем і стабільну продуктивність навіть під час одночасної обробки мільйонів файлів.
🧭 Qdrant
Високопродуктивну векторну базу даних, яка перетворює інтелектуальну роботу з документами з ключового пошуку на семантичний. Qdrant дає змогу elDoc:
- розуміти зміст не лише за точними збігами,
- миттєво знаходити схожі документи,
- кластеризувати пов’язані файли,
- зіставляти рахунки-фактури з контрактами,
- виявляти дублікати та майже дублікати
- підтримувати семантичний AI-пошук.
Це створює справжню «інтелектуальну навігацію по документах», а не просто фільтрування.
🔤 Multiple OCR Engines
Щоб обробляти будь-які типи документів і різний рівень їхньої якості, elDoc використовує кілька OCR-рушіїв — вибір залишається за вами.
- Tesseract – open-source OCR для загального зчитування тексту
- Google OCR API – високоточний хмарний OCR для складного тексту
- Qwen3-VL – vision-language OCR для AI-орієнтованого розуміння макета
- PaddleOCR – надзвичайно швидкий багатомовний OCR
Такий мульти-рушійний підхід забезпечує максимальну точність для відсканованих PDF-файлів, фотографій, багатомовних документів і зображень низької якості.
🔎 Apache Solr
Перевірений корпоративний пошуковий рушій, який використовується для високошвидкісного індексування та пошуку за ключовими словами.
Solr підтримує:
- миттєвий повнотекстовий пошук
- фасетну (фільтровану) навігацію
- просунуте ранжування та визначення релевантності
- масштабованість для індексування великих обсягів даних
У поєднанні з ШІ та векторним пошуком це формує гібридну пошукову систему: ключовий пошук + семантичний пошук + глибинний AI-пошук.
🖼️ Computer Vision
Перш ніж ШІ прочитає та зрозуміє документ, Computer Vision готує та нормалізує його.
Цей рівень виконує:
- вирівнювання перекошених сканів
- видалення шумів і корекцію контрасту
- виявлення таблиць, печаток, підписів і діаграм
- розпізнавання макета сторінки
- сегментацію складних багаторозділових документів
Це значно підвищує якість OCR і точність роботи LLM.
🧠 Вбудований інтелект LLM
Корінь можливостей elDoc у розумінні документів.
LLM забезпечують:
- розуміння неструктурованого вмісту на рівні людини
- інтелектуальну класифікацію документів
- контекстне зчитування даних
- семантичне групування та сортування
- інтерпретацію довгих і складних файлів
- взаємодію з документами природною мовою
elDoc підтримує різних постачальників LLM, різні розміри моделей та режими розгортання, включно з повністю локальними інсталяціями для роботи в чутливих або захищених середовищах.
🔍 RAG (Retrieval-Augmented Generation)
RAG перетворює обробку одного документа на багатодокументний інтелект.
Завдяки RAG elDoc може:
- пов’язувати документи між собою
- виявляти невідповідності між файлами
- пов’язувати контракти з рахунками-фактурами, звітами або електронними листами
- виконувати міждокументні запити та відповіді (Q&A)
- створювати контекстно-орієнтовані аналітичні висновки
Це забезпечує надлюдський рівень логічного опрацювання документів.
🗂️ Керування метаданими
Кожен документ, завантажений до elDoc, автоматично отримує інтелектуальне збагачення метаданих.
Система захоплює та впорядковує:
- тип документа
- інформацію про постачальника/клієнта
- дати, суми, ідентифікатори
- теги проєкту або відділу
- категорії класифікації
- ярлики та резюме, згенеровані ШІ
Ці метадані забезпечують роботу фільтрації, аналітики, автоматизації та пошуку.
📁 Безпечне файлове сховище та платформа для спільної роботи
elDoc — це не просто ШІ-рушій, а повноцінна платформа для управління документами.
Вона забезпечує:
- безпечне зберігання з контрольованим доступом
- обмін документами на основі дозволів
- співпрацю в реальному часі
- редагування та анотування
- робочі процеси рецензування та затвердження
- журнали аудиту
- керування версіями
- журнали активності та функції контрольованості (governance)
Користувачі можуть організовувати, керувати, аналізувати документи та співпрацювати над ними — усе в одному місці, без потреби переходити між різними системами.
Створено для справжніх AI-робочих процесів, а не для застарілої автоматизації
Архітектура elDoc спочатку створена з урахуванням роботи з LLM, підтримуючи масштабну обробку неструктурованих даних, багатодокументне логічне мислення та глибоке семантичне розуміння.
Усе вже скоординовано й працює разом — без необхідності для користувачів підключати чи обслуговувати різні інструменти. Тоді як інші системи вимагають налаштування, навчання та ручних правил, elDoc працює “з коробки”.
Ви просто ставите запитання — а ваш “AI-співробітник з документів” робить усе інше
Замість того щоб витрачати години на ручне сортування, перейменування, групування чи перевірку документів, elDoc дозволяє керувати всім за допомогою природної мови:
- «Впорядкуй ці документи за типом і роком».
- «Згрупуй контракти за датою продовження».
- «Знайди всі документи, пов’язані з цим постачальником».
- «Порівняй контракт з усіма пов’язаними рахунками-фактурами й знайди розбіжності».
Ваш AI-співробітник з документів виконує роботу миттєво, інтелектуально та з надлюдською точністю, перетворюючи те, що колись було виснажливим ручним завданням, на просту команду.
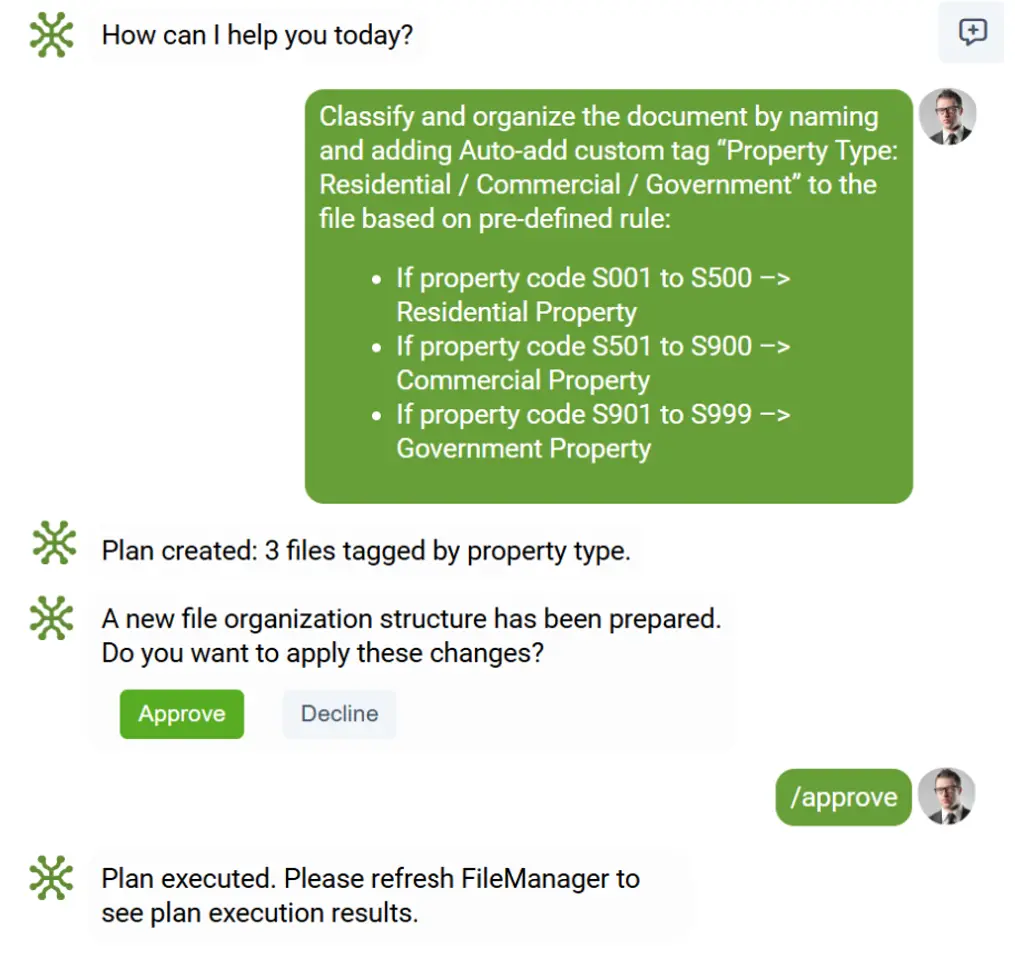
elDoc робить AI-класифікацію та сортування документів реальністю
З elDoc інтелектуальна класифікація та сортування документів більше не є далекими обіцянками — це практична, доступна й effortless-реальність. Вам більше не потрібно хвилюватися про те, як організувати, структурувати чи зрозуміти свої файли. Ви просто заходите в систему, завантажуєте документи — і ваш AI-співробітник з документів, ваш постійно доступний цифровий асистент, виконує всю складну роботу за вас.
Коли все впорядковано, ви можете співпрацювати над файлами, безпечно ділитися ними, керувати версіями, редагувати, рецензувати та затверджувати документи без жодних перешкод. Усе це відбувається в єдиній, об’єднаній платформі, створеній для спрощення ваших робочих процесів і виведення обробки документів на новий рівень завдяки справжньому AI-інтелекту.