Інтелектуальна обробка документів з LLM / AI: без шаблонів, без налаштувань — лише інтелект

Протягом останніх десятиліть ми спостерігаємо постійні хвилі нових технологій, що обіцяють повну автоматизацію обробки документів — напрям, який отримав назву Інтелектуальна обробка документів (IDP – Intelligent Document Processing).
Десятки постачальників з’явилися, щоб вирішити це завдання, кожен із яких заявляв, що здатен досягти повної автоматизації для найскладніших типів документів. Проте жодному не вдалося досягти досконалості.
Чому? Тому що реальні документи — надзвичайно різноманітні, неструктуровані та непередбачувані.
Основні виклики традиційних IDP-рішень, побудованих на OCR, AI, Machine Learning та NLP
⚙️ Складне налаштування та шаблони — кожен новий формат документа потребував ручного створення правил, зонування та дизайну макетів.
🔁 Постійне перенавчання моделей — навіть незначні зміни у структурі документа руйнували існуючі моделі, змушуючи команди проводити тренування знову і знову.
📄 Обмежене покриття типів документів — більшість постачальників спеціалізувалися лише на 1–2 сферах (наприклад, рахунки, квитанції, ID-карти, паспорти) і не справлялися з іншими типами документів.
⚠️ Низька точність і хибнопозитивні результати — витягнуті дані часто містили помилки чи неточності, що створювало фінансові та комплаєнс-ризики.
🧑 Високе операційне навантаження — моделі вимагали постійного навчання, моніторингу, валідації та обробки винятків.
🚫Залежність від участі людини — попри всі заяви про “повну автоматизацію”, на практиці без участі людини не обходилось: хтось завжди мав перевірити, скоригувати або схвалити результат.
У підсумку, замість “інтелектуальної” автоматизації документообігу бізнес отримував складну, ресурсоємну систему шаблонів, конфігурацій і нескінченних циклів перенавчання — далеку від простоти та гнучкості, якої прагнули організації.
Як LLM в elDoc трансформує інтелектуальну обробку документів?
Поява Large Language Models (LLM) докорінно змінила підхід до IDP. Якщо традиційні системи спиралися на OCR, машинне навчання та NLP, то вони могли автоматизувати лише структуровані або напівструктуровані дані, залишаючи прогалину у роботі з неструктурованими документами.
Тепер, коли LLM поєднано з OCR і комп’ютерним зором, ці прогалини усунено.
LLM додають “людське” розуміння контексту, дозволяючи системам не лише “бачити” текст, а й розуміти його зміст, контекст та намір.
Як LLM в elDoc революціонізує процес IDP?
🧩 Без шаблонів і конфігурацій
LLM миттєво адаптується до будь-якого макета чи структури документа — без зонування, правил чи шаблонів.
🤖 Без навчання моделей і контролю людини
Забудьте про нескінченні цикли перенавчання. LLM працюють “з коробки”, розуміючи нові типи документів без додаткових тренувань.
⚡ Миттєве вилучення даних
Інформація витягується миттєво, з урахуванням контексту — без попередньої обробки або складного мапінгу.
🎯 Вища точність та надійність
LLM суттєво знижують кількість помилкових збігів, інтерпретуючи зміст логічно, а не лише за шаблоном.
🔄 Уніфікація та нормалізація даних
LLM автоматично конвертують формати даних — наприклад, слова у цифри, валюти або дати — усуваючи потребу у постобробці.
🧠 Семантичне розуміння контенту
LLM здатні “читати” неструктурований текст (контракти, звіти, листування), виявляючи зобов’язання, ризики та наміри.
🌍 Будь-який документ, будь-який формат
Від рукописних нотаток до сканованих контрактів, рахунків чи звітів — LLM обробляє все, що раніше було недоступним для автоматизації.
У підсумку, LLM перетворює IDP із системи правил у справжній штучний інтелект. Комбінація OCR + Computer Vision + LLM — це злиття, де машини нарешті можуть “читати, розуміти і приймати рішення”, як люди.
Як elDoc використовує LLM для інтелектуальної обробки документів – і які результати це дає?
У elDoc ми повністю прийняли нову епоху LLM-орієнтованої IDP, поєднуючи великі мовні моделі, OCR та комп’ютерний зір, щоб досягти справжнього розуміння документів — не лише автоматизації.
На відміну від традиційних систем, що покладаються на шаблони, ручне налаштування та людський контроль, AI Document Employees від elDoc працюють інтелектуально — миттєво адаптуючись до будь-яких нових типів документів, макетів і форматів.
Результат — повноцінне розуміння документів: від вилучення даних до їх інтерпретації — без попереднього навчання чи налаштувань.
Без шаблонів і конфігурацій
З elDoc документи обробляються миттєво — незалежно від їхньої структури чи формату.
Вам не потрібно створювати шаблони, визначати зони або налаштовувати мапінг. Достатньо лише вказати, які дані потрібно отримати.
Після завантаження документів elDoc автоматично здійснює OCR та комп’ютерне розпізнавання, точно ідентифікуючи всі елементи сторінки. Потім вступає в дію LLM — інтерпретує зміст, виконує автоматичне індексування й витягує потрібні дані з високою точністю — без ручного втручання.
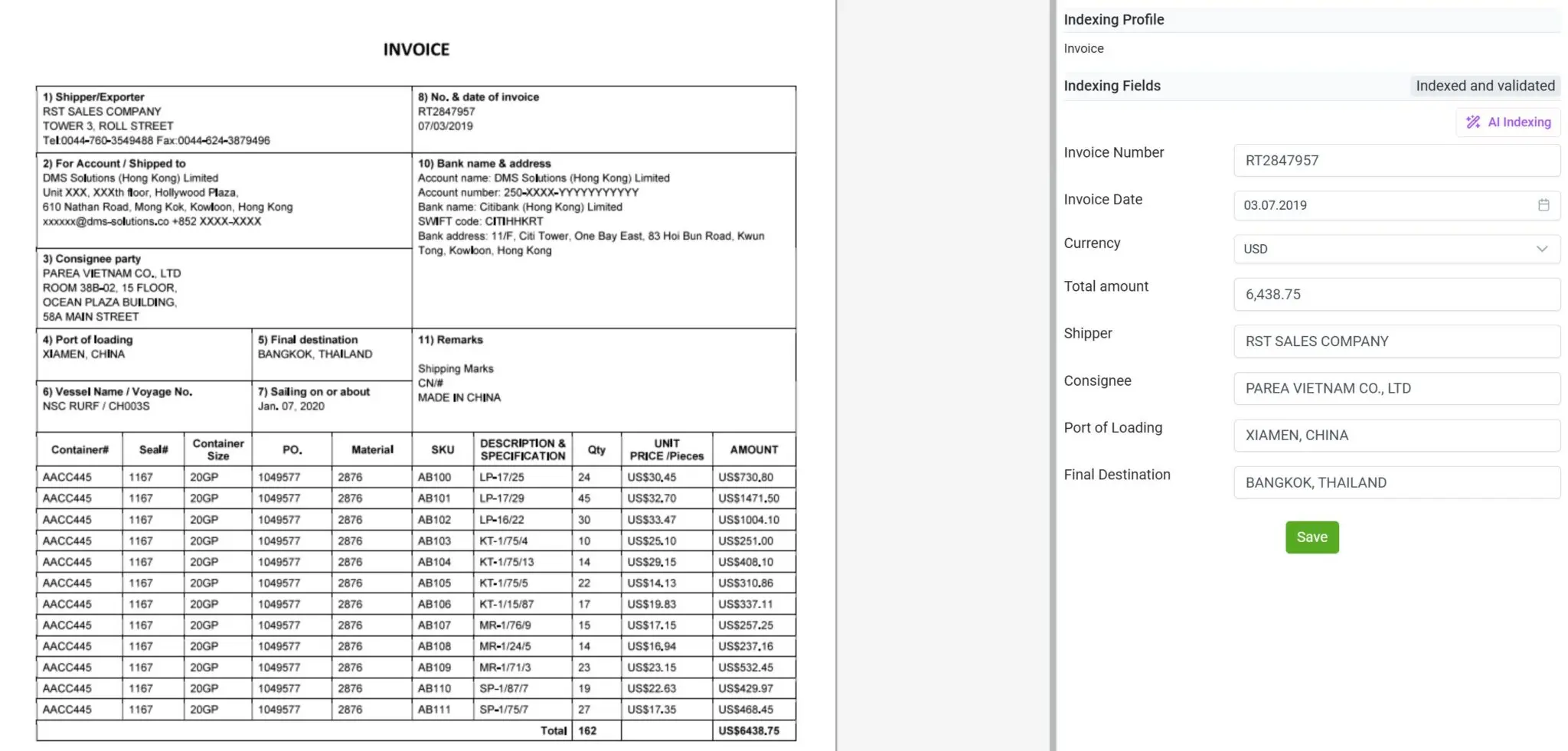
Обробка широкого спектра документів, не лише рахунків
З elDoc ви більше не обмежені лише інвойсами чи формами.
Платформа здатна працювати з будь-якими типами документів — квитанціями, рахунками за комунальні послуги, листуванням, контрактами, замовленнями, виписками з банку, звітами, протоколами тощо.
Незалежно від того, чи документ відсканований, рукописний або створений цифрово, elDoc завдяки поєднанню OCR + Computer Vision + LLM точно зчитує, інтерпретує та витягує релевантні дані.
Ця універсальність дозволяє організаціям централізувати документообіг на одній платформі, усуваючи потребу у багатьох інструментах та досягаючи справжнього наскрізного інтелекту документів.
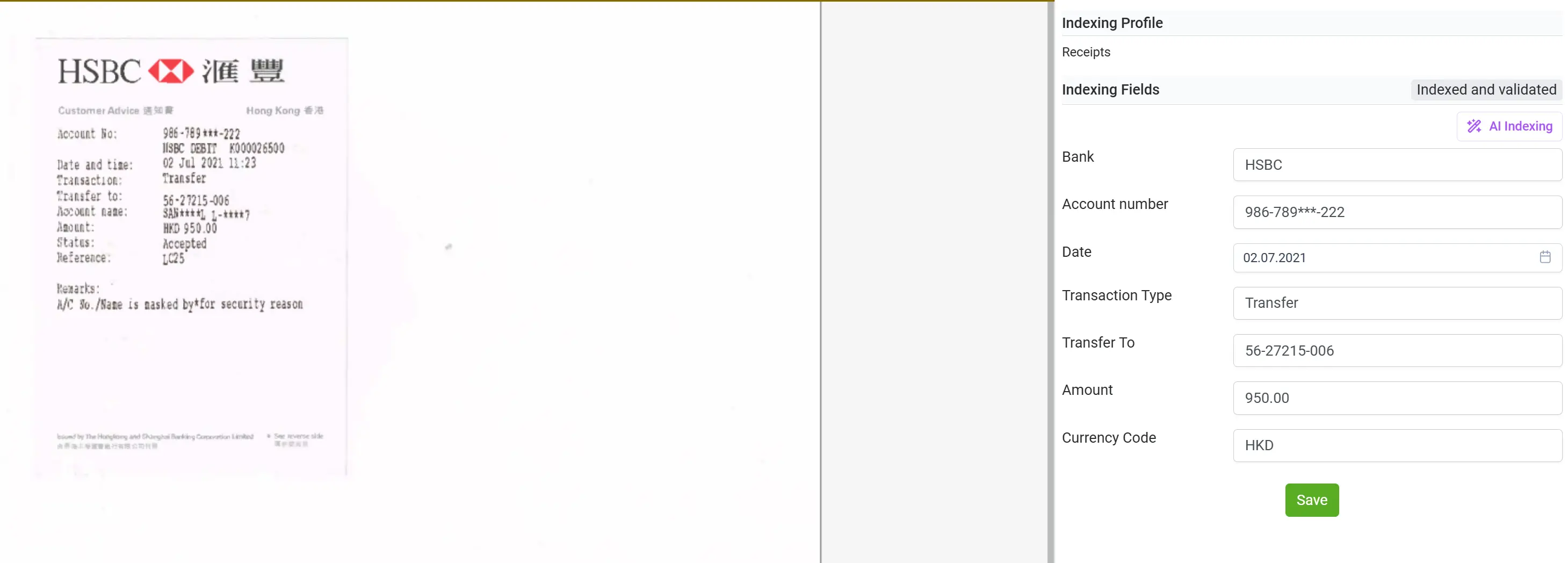
Автоматичне заповнення та індексація даних
Після вилучення інформації elDoc автоматично структурує її у централізованій панелі індексації.
Тут усі поля впорядковуються, категоризуються та стають доступними для подальшої обробки, пошуку чи аналітики.
Цей процес усуває ручне введення даних і забезпечує повну узгодженість, простежуваність та готовність до перевірок або звітності.
Ваші неструктуровані дані перетворюються на структуровану базу знань, доступну за лічені секунди.
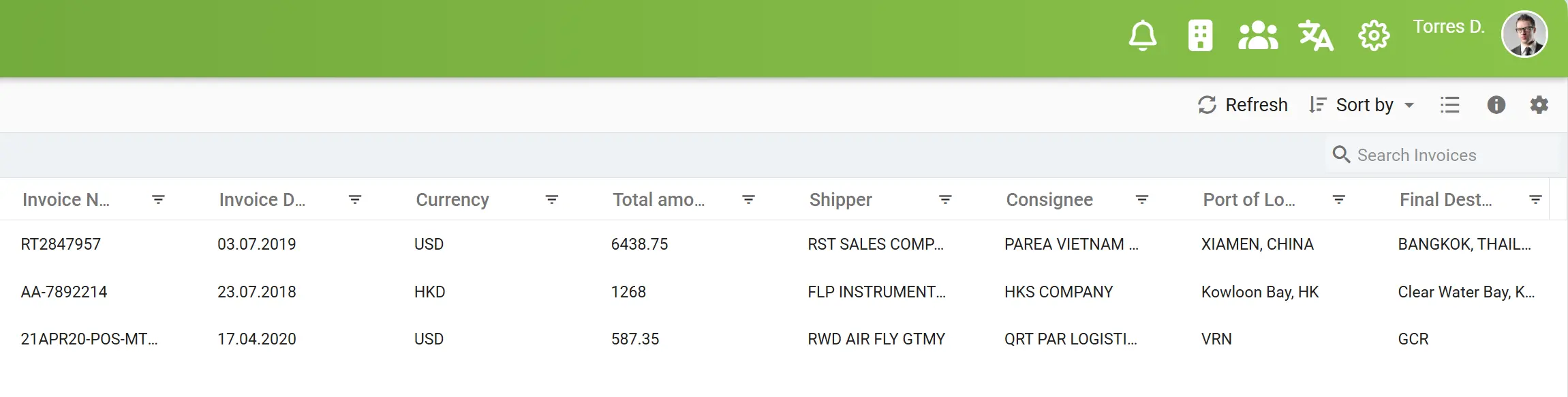
AI-постобробка та нормалізація даних
Одна з головних проблем раніше — різний формат даних у різних документах.
Наприклад, дати могли записуватись як “10.03.2025”, “10/03/25” або навіть словами; суми — з різними валютами чи пробілами.
З AI-постобробкою elDoc це вирішено. Система автоматично розпізнає, стандартизує й перетворює дані у потрібний формат (наприклад, “10.03.2025” → “2025-03-10”).
Це гарантує, що всі дані чисті, узгоджені й готові до використання без ручних правок.
Ця інтелектуальна нормалізація гарантує, що кожен фрагмент інформації, вилучений із ваших документів, є чистим, узгодженим і готовим до подальшого використання — без потреби в ручних виправленнях чи додаткових скриптах постобробки.
elDoc перетворює неохайні, непослідовні дані на надійний, структурований набір, якому можуть довіряти ваші системи.
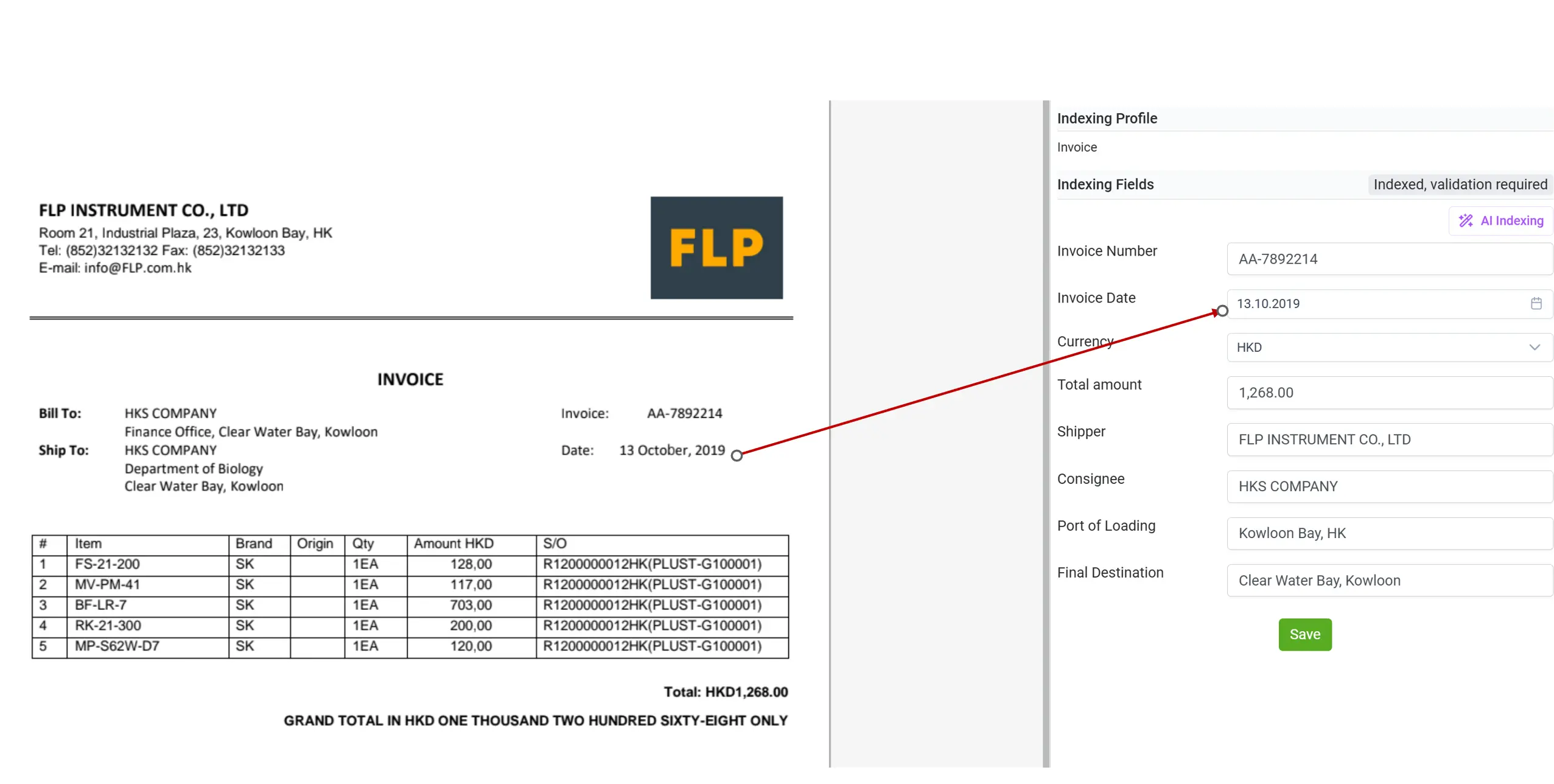
Розуміння неструктурованих даних
Тепер з elDoc ви можете легко обробляти контракти, звіти, листи чи будь-які багатосторінкові документи.
Після OCR контент аналізується AI-індексацією на базі LLM, яка розуміє контекст, сутності та зв’язки між ними.
Навіть якщо дані подані природною мовою (наприклад: “оплата протягом тридцяти днів після дати рахунку”), elDoc здатен інтерпретувати це як конкретну дату чи суму.
Таким чином, неструктурований текст миттєво перетворюється на структуровані, придатні до дій дані.

Нова ера IDP для будь-яких бізнес-потреб
Попри те, що LLM забезпечують інтелектуальну автоматизацію, на рівні підприємств важлива також надійність та контроль якості.
Тому elDoc передбачає Validation Station — інтуїтивний інтерфейс, де користувач може перевірити та підтвердити витягнуті дані перед фіналізацією.
Це особливо важливо для фінансових звітів, контрактів або регуляторних документів.
Після валідації дані можна експортувати у різних форматах — JSON, CSV тощо — для інтеграції з ERP, CRM чи аналітичними системами.
elDoc також підтримує повну гнучкість робочих процесів — від обробки окремих документів (“Будь ласка, витягни й проіндексуй дані з цього документа”) до масштабних корпоративних завантажень тисяч файлів для масової класифікації та індексації.
elDoc також підтримує повну гнучкість робочих процесів — від обробки окремих документів (“Будь ласка, витягни й проіндексуй дані з цього документа”) до масштабних корпоративних завантажень тисяч файлів для масової класифікації та індексації.
Ця гнучкість дозволяє elDoc адаптуватися до будь-яких сценаріїв — від невеликих запитів до великих корпоративних екосистем.
Таким чином, elDoc відкриває нову еру інтелектуальної обробки документів — еру, що руйнує обмеження застарілих систем і нарешті забезпечує те, чого бізнес завжди прагнув: швидкість, точність, адаптивність і справжній інтелект у кожному документному процесі.