Як зчитувати дані з рахунків-фактур за допомогою GenAI (OCR + LLM + CV + RAG)

Традиційна обробка рахунків-фактур є повільною, вручну керованою та схильною до помилок. Фінансові команди витрачають безліч годин на читання PDF-файлів, фіксацію сум, перевірку постачальників, валідацію номерів замовлень (PO) та внесення даних у ERP-системи. Протягом десятиліть постачальники обіцяли, що вони «нарешті вирішили проблему» автоматичного вилучення даних з рахунків. Але реальність була іншою. Більшість традиційних рішень вимагали одного або кількох із таких елементів:
- налаштування шаблонів або макетів для кожного постачальника
- постійного перенавчання, коли змінювалися формати
- кастомної розробки для нестандартних документів або особливих кейсів
- жорстких ML/NLP-моделей, які добре працювали лише на заздалегідь відомих макетах
- високої кількості помилок, коли рахунки відрізнялися за структурою або якість зображень погіршувалась
- частих ручних виправлень, що робило «автоматизацію» фактично неавтоматизованою
Навіть найпросунутіші «AI OCR»-інструменти попереднього покоління мали фундаментальні обмеження — вони могли читати текст, але не розуміти його. Вони розпізнавали символи, але не значення. Вони фіксували слова, але не контекст.
GenAI змінює все
Сьогодні поєднання передового OCR, CV та інтелекту LLM дозволяє компаніям миттєво витягувати структуровані дані з рахунків — навіть зі сканованих, повернутих, рукописних, багатомовних або низькоякісних документів.
Без шаблонів
Без кастомних правил
Без налаштувань макетів
Без нескінченних циклів перенавчання моделей
Просто людський рівень розуміння — на надлюдській швидкості. У цій статті elDoc пояснює, як працює сучасне GenAI-витягування даних з рахунків, які технології це забезпечують і чому новий підхід кардинально перевершує традиційні OCR-системи.
Як elDoc забезпечує безшовне зчитування даних із рахунків: повний AI-стек пояснений
Обробка рахунків-фактур в elDoc реалізована за допомогою інтегрованого конвеєра, що включає OCR-двигуни, модулі комп’ютерного зору, LLM-розуміння, контекстний RAG-пошук, семантичний пошук та високопродуктивні бази даних. Усі ці технології працюють як єдина система, забезпечуючи точне вилучення, розумну валідацію та правильну класифікацію для будь-якого формату рахунків — без шаблонів і ручного налаштування.
🔤 OCR — перетворення зображень і PDF у текст
Більшість рахунків надходять як скани, зображення або незмінні PDF-файли. OCR перетворює їх у машинозчитуваний текст, щоб AI міг «читати» та інтерпретувати зміст.
Що робить цей шар:
- Витягує текст зі сканів і зображень
- Підтримує багатомовність при зчитуванні та розпізнаванні
- Робить PDF-файли пошуковими
- Забезпечує роботу подальших AI-модулів
OCR-ри, що використовуються elDoc:
- Tesseract – open-source OCR для загального зчитування тексту
- Google OCR API – високоточний хмарний OCR для складного тексту
- Qwen3-VL – OCR та розуміння макету через vision-language моделі
- PaddleOCR – надшвидкий, багатомовний OCR для широкого спектра форматів
Залежно від того, чи рішення розгортається локально (on-premise) або в хмарі, elDoc активує найбільш придатний OCR-двигун — усі вони забезпечують виняткову точність і надійне розпізнавання тексту.
🖼️ Комп’ютерний зір — очищення та нормалізація документа
Перш ніж будь-яка AI-модель інтерпретує рахунок, шар Computer Vision оптимізує документ для максимальної точності.
Що виконується на цьому етапі:
- Вирівнювання та усунення перекосів сторінок
- Шумозаглушення та підсилення контрасту
- Виявлення таблиць, печаток, підписів
- Сегментація сторінки та розпізнавання макету
- Нормалізація низькоякісних сканів
Це гарантує, що OCR генерує чистий і структурований текст навіть для складних, старих або низькороздільних документів.
🧠LLM — справжнє розуміння змісту
Велика мовна модель (LLM) — це «мозок» інтелектуального шару elDoc. Вона читає рахунки так само, як людина — але з надлюдською швидкістю, точністю та послідовністю.
Можливості LLM:
- Розуміє зміст, контекст і намір
- Розпізнає типи та підтипи документів
- Інтерпретує неструктурований або складний текст
- Витягує всі ключові поля (суми, дати, ПДВ, дані постачальника, позиції тощо)
- Виявляє невідповідності та аномалії
- Класифікує документи без шаблонів чи жорстких правил
Це — прорив, якого попередні ML/NLP-системи ніколи не могли досягти.
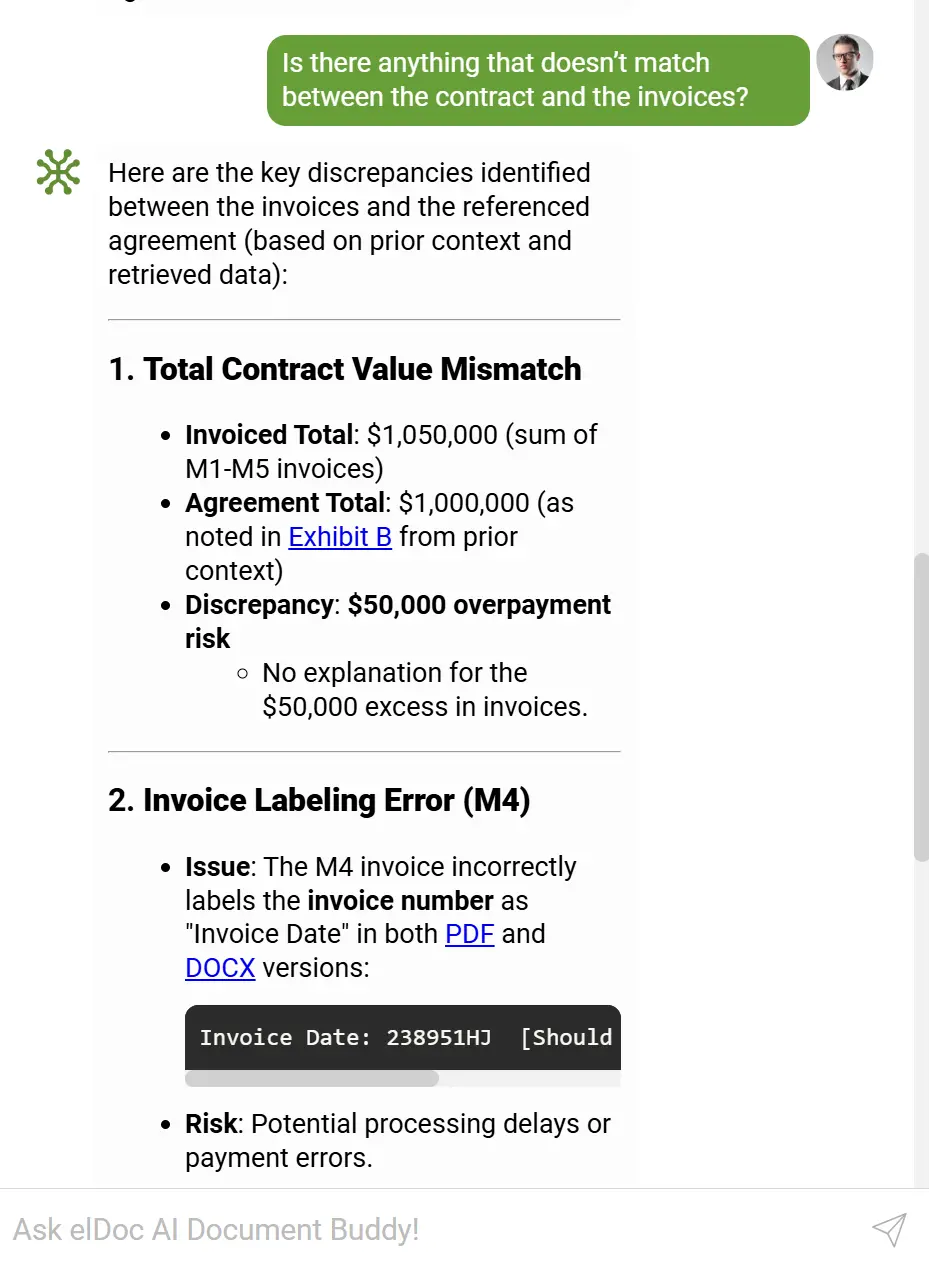
🔎 RAG — поєднання контексту між документами
Retrieval-Augmented Generation (RAG) додає глибокий інтелект, поєднуючи документи між собою.
RAG дозволяє elDoc:
- знаходити пов’язані рахунки, замовлення (PO) та контракти
- виконувати міждокументну валідацію
- виявляти невідповідності між документами
- відповідати на складні фінансові запити, використовуючи кілька файлів
- формувати контекстну пам’ять усієї документної бази
RAG перетворює ваше сховище на динамічну, взаємопов’язану базу знань.
🔒MongoDB — масштабоване сховище документів
MongoDB виступає основним рушієм зберігання в elDoc, обробляючи як метадані, так і великі файли на винятковому рівні продуктивності.
Чому MongoDB?
- висока масштабованість для мільйонів рахунків
- гнучка схема для непередбачуваних документних структур
- швидке отримання даних для реального робочого процесу
- корпоративна надійність і продуктивність
MongoDB формує ядро структурованого шару даних elDoc.
🧭 Qdrant — семантичний інтелект і векторний пошук
Qdrant — це векторна база даних elDoc, яка забезпечує справжнє семантичне розуміння документів.
Qdrant дозволяє elDoc:
- інтерпретувати зміст поза межами ключових слів
- миттєво знаходити подібні рахунки або дублікати
- кластеризувати споріднені документи
- співставляти рахунки з контрактами чи PO
- виконувати AI-підсилений семантичний пошук
Це критично для інтелектуальної валідації та побудови зв’язків між документами.
🔎Apache Solr — високошвидкісний повнотекстовий пошук
Solr додає корпоративний рівень індексації та пошуку за ключовими словами поверх AI та семантичних шарів.
Solr забезпечує:
- миттєвий повнотекстовий пошук серед мільйонів файлів
- фасетну та фільтровану навігацію
- просунуте ранжування та релевантність результатів
- масштабованість для масового індексування
Разом із Qdrant Solr формує гібридний пошук: пошук за ключовими словами + семантичний пошук + AI-розуміння.
elDoc зробив GenAI доступним для всіх: Community Edition
З Community Edition elDoc будь-хто — від індивідуальних спеціалістів до малих команд і середніх компаній — може одразу використовувати потужну GenAI-автоматизацію документів. Усі ключові компоненти вже інтегровані та оптимізовані, надаючи реальне готове середовище для AI OCR, вилучення LLM, RAG і семантичного пошуку без складного налаштування та технічних бар’єрів.
elDoc поєднує GenAI, OCR, Computer Vision, RAG, семантичний пошук і високопродуктивні движки зберігання в єдиний, інтелектуально скоординований конвеєр. Замість того, щоб покладатися на одну модель, статичні правила або жорсткі шаблони, elDoc оркеструє кожну технологію в оптимальній послідовності — починаючи з очищення документа, переходячи до розпізнавання тексту, і завершуючи глибоким семантичним розумінням, валідацією, зберіганням та експортом даних. Кожен шар додає свою унікальну можливість: OCR зчитує контент, Computer Vision нормалізує документ, LLM інтерпретує зміст, а RAG поєднує контекст усієї документної бібліотеки. Разом ця цілісна архітектура забезпечує надійне вилучення даних із рахунків без шаблонів, що стабільно працює з будь-яким форматом, мовою, макетом або якістю скану — навіть у найскладніших реальних умовах.